









博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

目录:

数据挖掘入门:从原理到技术栈的全面介绍
在当今信息爆炸的时代,**数据挖掘(Data Mining)**成为各行各业洞察数据价值的关键技术。它的核心目标是从大量原始数据中挖掘出有意义的模式、关系和趋势,从而支持商业决策、预测未来走向,甚至自动化推荐系统的构建。数据挖掘本身并不是孤立存在的,而是依赖于多种技术的协作,本文将简要介绍其概念,并解析几种常见相关技术:Hadoop、Python、Vue 和 MySQL,了解它们在数据挖掘中的角色和作用。
什么是数据挖掘?
数据挖掘是一种自动从海量数据中发现有用信息的技术,它融合了统计学、人工智能、数据库技术、机器学习等多个领域。典型应用包括用户行为分析、销售预测、欺诈检测等。它常包含几个关键步骤:数据收集、清洗、转换、挖掘和结果可视化。挖掘的目标可以是分类(如识别邮件是否为垃圾邮件)、聚类(如将客户分为不同群体)、预测(如预测销量)或发现关联关系(如购物篮分析)。
Hadoop:大数据处理平台的基石
在数据挖掘中,我们往往需要处理TB甚至PB级别的数据。这时,传统的数据库就力不从心了,Hadoop提供了强大的分布式存储(HDFS)和计算框架(MapReduce),可以让数据在多个节点之间并行处理。它是大数据处理的核心基础设施,特别适合批量数据预处理和离线分析任务。
Python:灵活强大的数据挖掘编程语言
Python 几乎是数据挖掘和数据科学领域的标准语言之一。它拥有丰富的库,如 pandas(数据处理)、scikit-learn(机器学习)、matplotlib/seaborn(可视化)、xgboost(高级建模)等,极大降低了挖掘门槛。无论是数据清洗、建模,还是分析结果展示,Python 都能一站式搞定。
Vue:数据可视化与结果呈现的前端利器
挖掘出结果后,如何让非技术人员也能读懂这些数据?这时前端框架如 Vue.js 派上用场。Vue 是一款渐进式 JavaScript 框架,易于与图表库(如 ECharts、Chart.js)结合,构建响应式、交互友好的数据展示界面。它特别适用于开发可视化仪表盘、数据报表或在线数据分析工具。
MySQL:结构化数据的存储与查询
在数据挖掘的早期阶段,很多原始数据来源于关系型数据库,而 MySQL 是其中最常见的数据库之一。它用于存储业务数据(如用户信息、交易记录等),并提供强大的 SQL 查询能力,方便快速获取结构化数据用于进一步分析。虽然处理能力不及Hadoop那样强大,但在中小型数据挖掘项目中仍非常实用。

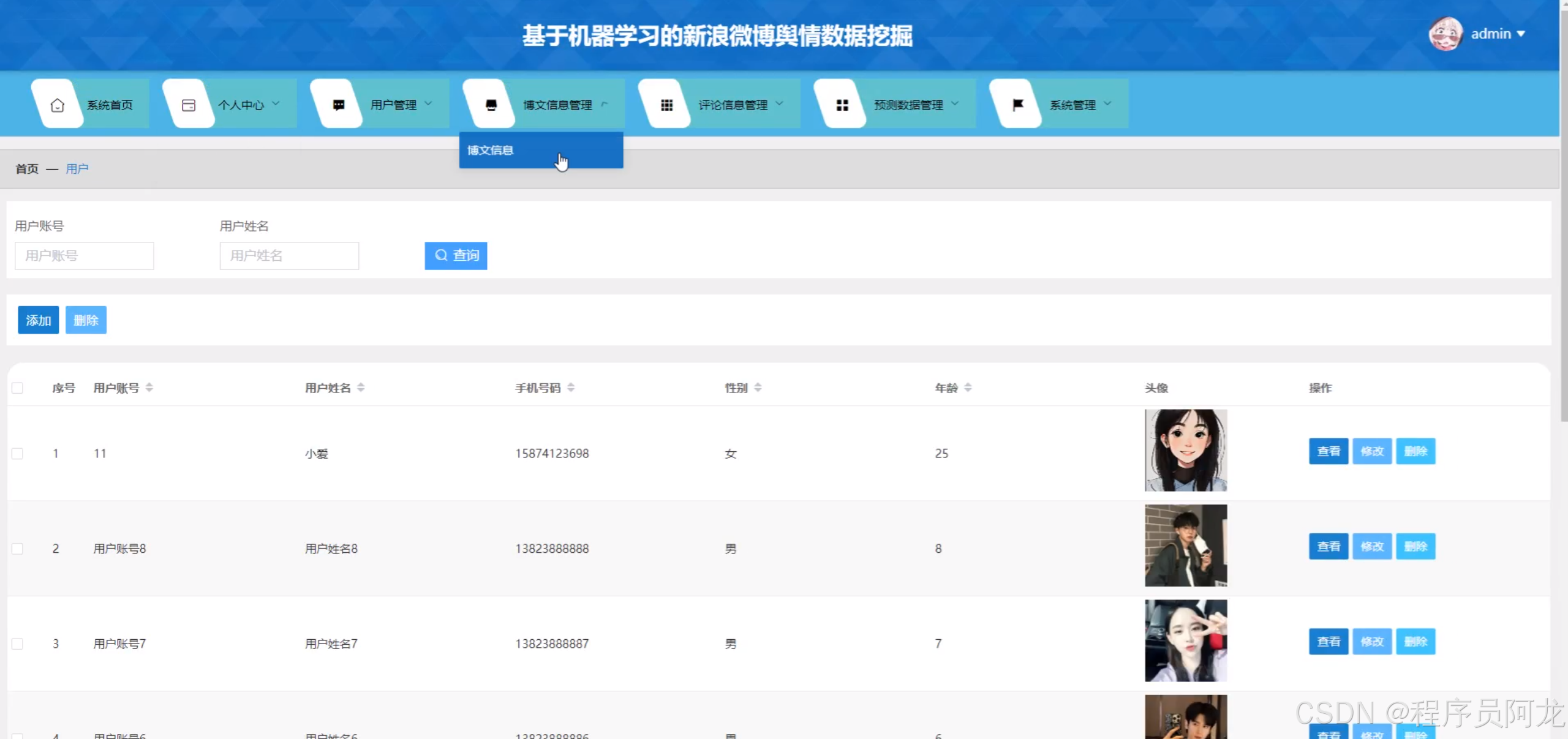
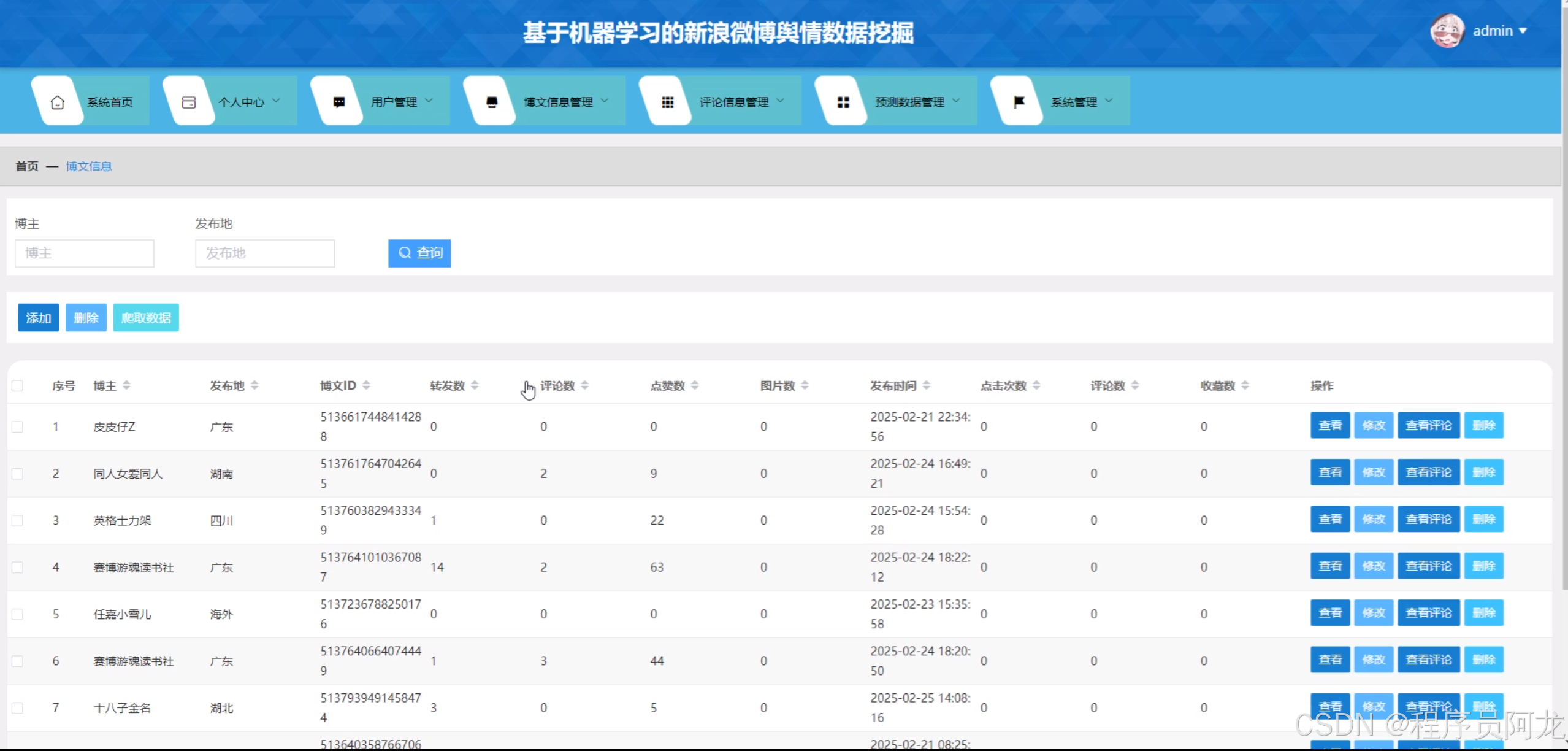
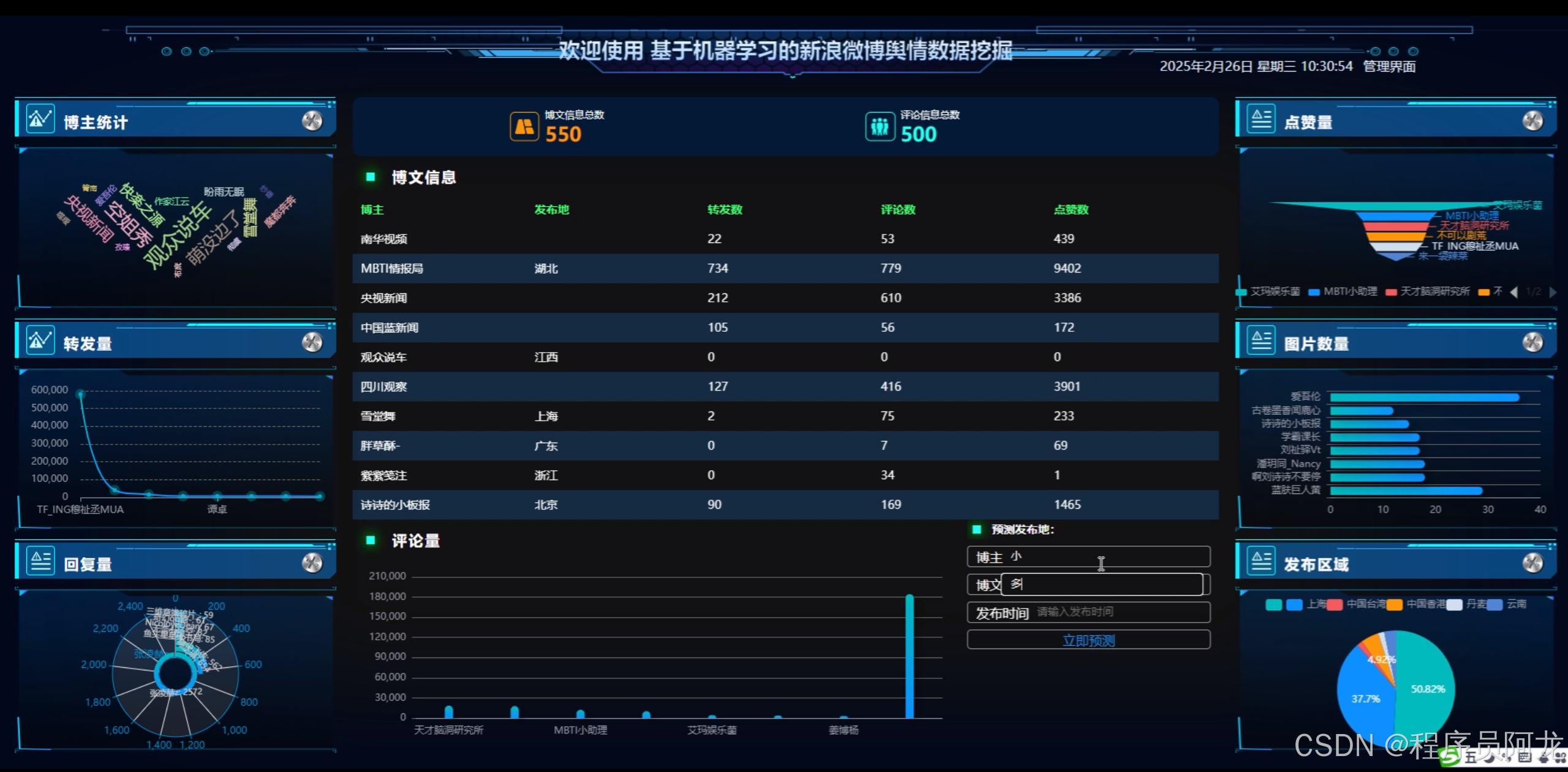
系统实现界面:

Mapper 类:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\\s+"); // 按空格分词
for (String w : words) {
word.set(w);
context.write(word, one); // 输出 <单词, 1>
}
}
}
第二步:Reducer 类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get(); // 累加每个单词的次数
}
context.write(key, new IntWritable(sum)); // 输出 <单词, 总次数>
}
}
✅ 第三步:Driver 主类(任务入口)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0])); // 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
源码获取
文 章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏


















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











