







文章来源:基于深度学习的小目标检测基准研究进展 (ejournal.org.cn)

本文仅用于学术分享,如有侵权,请联系后台作删文处理
文章目录
摘要
小目标检测是计算机视觉中极具挑战性的任务。它被广泛应用于遥感、交通、国防军事和日常生活等领域。相比其他视觉任务,小目标检测的研究进展相对缓慢。制约因素除了学习小目标特征的内在困难,还有小目标检测基准,即小目标检测数据集的稀缺以及建立小目标检测评估指标的挑战。为了更深入地理解小目标检测,本文首次对基于深度学习的小目标检测基准进行了全新彻底的调查。系统介绍了现存的35个小目标数据集,并从相对尺度和绝对尺度(目标边界框的宽度或高度、目标边界框宽高的乘积、目标边界框面积的平方根)对小目标的定义进行全面总结。重点从基于交并比及其变体、基于平均精度及其变体以及其他评估指标这3方面详细探讨了小目标检测评估指标。此外,从锚框机制、尺度感知与融合、上下文信息、超分辨率技术以及其他改进思路这5个角度对代表性小目标检测算法进行了全面阐述。与此同时,在6个数据集上对典型评估指标(评估指标+目标定义、评估指标+单目标类别)下的代表性小目标检测算法进行性能的深入分析与比较,并从小目标检测新基准、小目标定义的统一、小目标检测新框架、多模态小目标检测算法、旋转小目标检测以及高精度且实时的小目标检测这6个方面指出未来可能的发展趋势。希望该综述可以启发相关研究人员,进一步促进小目标检测的发展。
引言
小目标检测是计算机视觉中的一项重要任务。它指的是定位并识别图像或视频中尺寸较小的目标。小目标检测在学术界和现实世界应用广泛,如无人机场景分析、智能交通、军事侦察监视与日常生活等。本文主要关注基于深度学习的小目标检测基准(数据集和评估指标)的研究进展。为了完整性和更好的可读性,本文也包括了一些其他相关工作。
与其他视觉任务相比,小目标检测发展相对缓慢。我们认为制约因素有:(1)小目标数据集的稀缺;(2)建立小目标评估指标的挑战;(3)学习小目标特征的内在困难。
深度学习作为一种数据驱动技术,离不开各种数据集。在深度学习时代的目标检测的整个发展过程中,数据集不仅在模型训练中发挥了关键作用,而且还是评估和验证检测器性能的通用标准。因此,数据集在一定程度上推动了深度学习在小目标检测中取得成功。然而,与通用目标检测相比,针对小目标检测的数据集仍然稀缺。除了小目标数据集,小目标检测的评估指标也至关重要,图1为小目标检测算法在小目标数据集上评估示意图。通过性能好坏与否的反馈,以指导小目标检测算法的进一步改进。可以说,评估指标是连接小目标检测算法与小目标数据集的桥梁。
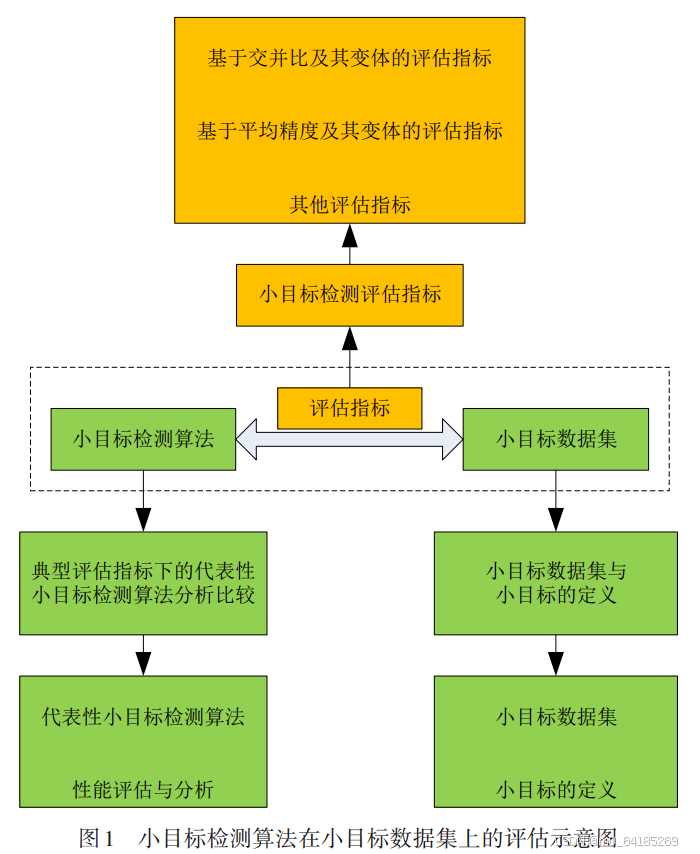
小目标数据集和小目标检测评估指标对基于深度学习的小目标检测器至关重要。此外,小目标检测算法的研究对推动小目标检测的发展也大有裨益。与大目标、中等目标相比,小目标更难被准确检测。这是由于小目标检测的几大困难。首先,小目标分辨率低,特征不足;其次,目标尺度跨度大,多尺度并存;再次,小目标样本很少,即生成的小尺寸锚框数量不足以匹配小目标以及成功匹配真值的实例数量不足;最后,小目标的类别不平衡。对于小目标,大多数锚框与真值的重叠度较低或没有重叠,这将带来大量的负例,而锚框与真值匹配达到预定阈值的正例则很少,这导致了两类的极度不平衡,进一步加大了检测小目标的难度。
为了解决这些困难,研究人员提出了一系列的工作。文献[1]通过一阶段、二阶段与多阶段的分类方法来阐述小目标检测。文献[2]从多尺度特征学习、数据增强、训练策略、基于上下文的检测和基于生成对抗网络的检测5个方面综述现有的基于深度学习的小目标检测方法。在此基础上,其他文献添加了新的分类方法来阐述小目标检测,如文献[3]中的无锚机制、文献[4]中的改善定位精度和感兴趣区域池化层设计、文献[5]中的锚框机制以及基于损失函数的策略。文献[6]从光学遥感图像、合成孔径雷达图像以及红外图像小目标检测这3个方面系统总结了领域内的代表性小目标检测方法。文献[7]针对小目标检测的难点给出了相应解决方案:改进小目标特征图、结合小目标上下文信息、增加小目标训练样本、改善小目标前景和背景类不平衡。此外,文献[8]基于深度学习框架,从多尺度表示、上下文信息、超分辨率、区域建议这4个方面对深度学习时代小目标检测方法进行阐述。表1给出了国内外学者对基于深度学习的小目标检测算法的总结与对比。

上述综述从算法分类的角度对小目标检测展开调查,以推动深度学习技术引领的小目标检测发展。然而,它们存在一定的局限性。首先,不同分类方法之间存在一定的重叠;其次,它们对小目标数据集和小目标定义探讨不够深入;最后,它们都缺乏对小目标检测评估指标的具体阐述。
不同于上述综述采用的方法分类视角,本文首次从基准(数据集和评估指标)的角度对基于深度学习的小目标检测展开全面调查。我们希望该综述可以为视觉社区提供及时的回顾,并启发相关研究者,以进一步促进小目标检测的发展。
本文贡献总结如下:(1)全面调查小目标数据集与小目标的定义;(2)深入阐述小目标检测评估指标;(3)剖析代表性小目标检测算法;(4)评估与分析典型评估指标下算法的性能;(5)指出未来小目标检测的潜在发展方向。
小目标数据集与小目标定义
小目标数据集
小目标数据集不仅能为数据驱动的深度学习算法提供足够的数据,还可以建立不同检测算法性能比较的平台。因此,它在小目标检测中起着不可或缺的作用。本节基于不同的应用场景(如遥感图像、交通标志与交通灯检测、行人检测、人脸检测、合成孔径雷达(Synthetic Aperture Radar,SAR)图像和红外图像、日常生活、其他等)总结了35个小目标数据集。图2给出了不同应用场景中一些小目标的示例图。对于每一个应用场景中的小目标数据集,我们按照时间顺序来介绍。

1)遥感图像
- SODA-A[9]。为了促进航空场景中小目标检测的发展,文献[9]构建了一个大规模的小目标检测数据集SODA-A。该数据集包含2 510幅高分辨率航空图像以及9个类别的800 203个目标实例。此外,该数据集中的目标具有不同的位置和方向,并且目标较为密集。
- SDOTA[10]。SDOTA是一个自建的数据集。它包含4个类别的1 508幅图像和227 656个目标实例。数据集中大多数是小于50个像素的小目标。此外,对于小型车辆类别,很多实例都小于10个像素。
- SDD[10]。SDD来自DOTA数据集和DIOR数据集。它包括5个类别的12 628幅航空图像和343 961个标注实例。涵盖的5个类别分别是车辆、飞机、船舶、风车和游泳池。
- DIOR[10,11]。DIOR是一个用于评估光学遥感目标检测的大规模数据集。它包括20个类别的23 463幅图像和190 288个目标实例。数据集中每个实例都由专家使用水平边界框标注。
- AI-TOD[12]。该数据集专注检测航空图像中的微小目标。它共有8个类别的700 621个目标实例,涵盖28 036幅尺寸为800×800像素的图像。该数据集中目标的平均大小约为12.8个像素,远小于现有的航空图像目标检测数据集。数据集AI-TOD-v2[13]对AI-TOD的标注进行了精确修复,重标注后的实例数为752 745。
- UAVDT[14]。UAVDT是一个具有挑战性的大规模无人机检测和跟踪数据集。由于无人机拍摄视角的高度较高,因此该数据集中的目标通常很小。特别地,数据集中27.5%的目标像素小于400,相当于一帧图像的0.07%。它包含80 000幅图像和841 500个目标实例。
- DOTA[15]。它是一个大规模航空图像目标检测数据集。它包含18个类别和11 268幅图像中的1 793 658个实例。该数据集中包含不同形状、方向和尺寸的目标。训练、测试和验证集的比例分别为1/2,1/3,1/6。
- Stanford Drone Dataset[16]。该数据集是一个大型数据集,包含在真实的大学校园中移动和交互的各类目标的图像和视频。训练和验证集包含69 673幅图像,测试集包含53 224幅图像。
- DLR 3k Munich Dataset[17]。这是一个用于车辆检测的数据集。它包含20幅超大图像。10幅用于训练,10幅用于测试。有14 235辆车通过边界框手动标注。
2)交通标志与交通灯检测
- SODA-D[9]。文献[9]为了促进自动驾驶场景中小目标检测的发展,构建了一个大规模小目标检测数据集SODA-D。该数据集包含24704幅高质量交通图像以及9个类别的277 596个目标实例。此外,该数据集在位置、天气、时间、拍摄视角和场景方面具有丰富的多样性。
- Bosch Small Traffic Lights[18]。该数据集包含13427幅分辨率为1280×720像素的图像,其中大约有24000个带标注的交通灯。每个交通灯实例都使用红绿灯的边界框以及当前灯的状态来标注。
- Tsinghua-Tencent 100K(TT100K)[19]。TT100K是一个真实的交通标志检测数据集,包含100000幅图像中的30000个交通标志实例,涵盖45个常见的中文交通标志。它的每个实例都使用边界框和实例级掩码进行注释。
- German Traffic Sign Detection Benchmark(GTSDB)[20]。GTSDB是一个包含农村、城市和高速公路驾驶等场景的图像数据集,其中大多数交通标志只出现一次。该数据集中交通标志尺寸的最长边在16到128像素之间。
- LISA Traffic Sign Dataset[21]。它包含6 610个视频帧中的49个US交通标志和7 855个标注。每个交通标志都标注了大小、类型、位置等。其尺寸介于6×6与167×168像素。
3)行人检测
- TinyPerson[22]。文献[22]提出的TinyPerson数据集促进了远距离、大背景下的微小目标检测的发展。它包含5个类别的72 651个标注实例和1 610幅图像(训练和验证图像分别为794幅和816幅)。
- TinyCityPersons[22]。为量化绝对尺寸减小对性能的影响,文献[22]对CityPersons进行4×4下采样,以构建数据集TinyCityPersons。EuroCity Persons[23]。文献[23]从12个欧洲国家的31个城市的移动车辆上收集了该数据集的图像。它含有47 300幅图像,并提供了大量准确和详细的城市场景中行人以及其他骑手的注释(约238 200个实例)。
- CityPersons[24]。文献[24]在Cityscapes[25]基础之上构建了CityPersons数据集。它是在27个城市、3个季节和多种天气条件下,由常见人群组成的行人检测数据集。在含有30个类别的总共5 000幅图像中,有大约35000个行人实例标注和大约13 000个忽略区域的标注。
- Caltech[26]。Caltech是流行的行人检测数据集,包含250000帧,共有约350000个标注的边界框。训练集和测试集包含的实例数分别为19200和155000。
4)人脸检测
- WIDER FACE[27]。- WIDER FACE是一个面向精确人脸检测的大规模数据集,其中人脸在尺度、姿态、遮挡、表情、外观和光照等方面存在显著差异。它由32 203幅图像和393 703个标记的人脸组成。该数据集基于60
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









