






一、线性回归算法的基本介绍
线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。
线性回归算法分类:一元线性回归(y = kx +b )、多元线性回归(y=k1x1+k2x2+k3x3+b)
基础的API:LinearRegression
# 1. 导入数据包
from sklearn.linear_model import LinearRegression
# 2. 准备数据
x = [[160], [166], [172], [174], [180]]
y = [[56.3], [60.6], [65.1], [68.5], [75]]
# 3. 实例化模型
lr = LinearRegression()
lr.fit(x, y)
# 4. 预测
print(lr.predict([[163]]))这是最简单的API,接下来通过一个案例来深入了解线性回归
二、波士顿房价案例
1. 导入数据
该数据已经内置 不用下载 直接导包进行 但如果版本过高可能需要自己下载,接下来导入的数据在下面的步骤都需要用到。实例化数据对象就可以使用了 这里我用变量bs接收,需要注意的是这个数据官方已经把他分好了数据部分(data),和目标部分(target)并且由字典封装,我们调用就可以,不用自己进行特征提取。
# 1. 准备数据
from sklearn.datasets import load_boston
bs=load_boston()2. 数据集划分
将数据集划分成训练集和测试集两部分,其中训练集用来训练模型,测试集用来测试模型和模型评分,同时训练集和测试集又分成特征和目标两部分,分别为 x_train、x_test、y_train、y_test。x表示特征,y表示目标,train表示训练集,test表示目标。
参数:bs.data就是特征值,bs.target是目标值,test_size是划分多少数据为测试集,一般为百分之二十或三十,random_state是一个随机数种子,随机获取数据为测试集
# 2. 数据预处理-划分数据集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(bs.data,bs.target,test_size=0.2,random_state=22)3. 特征预处理
这里的预处理是将数据标准化,让数据分布在均值为0方差为1的标准正态分布内,防止量纲问题影响数据的鲁棒性,去量纲大的特征对量纲小的特征的影响,一般回归问题会将数据标准化,而分类问题会将数据归一化,归一化是将数据映射到0~1的区间内。

# 3. 特征预处理
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)fit_transform是两个函数合成一个,fit函数是求出数据的平均值和方差,而transform是将数据转化为均值为0,方差为1的数据。这里只需要对x_train也就是训练集的特征值使用fit函数,因为我们要将训练集的平均值和方差用在测试集上才能对比模型之后的预测正确率。
4. 模型训练
模型训练有最简单的方式就是直接使用默认方式的正规方程法,这里我准备了四个方式来训练模型 分别是: 正规方程法 梯度下降算法 L1正则算法 L2正则算法 ,接下来分别介绍
5. 正规方程法
线性回归算法的k和b需要取得一个合适值,让这条回归线更好的契合数据的分布,而损失函数就是用来算预测值和真实值的差距,这种差距越小,k和b取值越好,如何让损失函数的值最小呢,首先我们要知道损失函数有几种,分别是最小二乘法和 MSE,MAE等,都是求数据在假定的回归方程上面的值与真实值之间的差距,那么要使这个差距最小,就要对k求导,让导函数等于0,这个时候就能找到最小值,也就找到了最好的k和b,当然k可以有很多个,这个时候就要求偏导。但是不用害怕,机器学习内置了算法,我们只要调用API就行,如果需要了解算法的底层,可以去查看相应的API解析。
#正规方程法
from sklearn.linear_model import LinearRegression
lr = LinearRegression(fit_intercept=True)
lr.fit(x_train,y_train)
print(lr.coef_)
print(lr.intercept_)参数fit_intercept是设置是否需要偏置值b,coef表示k,intercept表示b,这里的fit不是求平均值和方差了,而是模型训练。
6. 梯度下降法
梯度下降算法是设置一个初始的权重值w和一个下降速率a,然后取损失函数梯度的反方向,求损失函数在权重w的导数,然后让初始权重减去 a和这个导数的乘积来迭代权重值w,这样权重w就会一步一步减小,直到导数趋近于0

#梯度下降算法
from sklearn.linear_model import SGDRegressor
sr=SGDRegressor(learning_rate='constant',eta0=0.01)
sr.fit(x_train,y_train)
print(sr.coef_)
print(sr.intercept_)eta0表示学习速率,constant表常数速率,可以设置变化速率
7. L1 正则化
L1和L2正则化都是在梯度下降的基础上的,但是作用是防止模型过拟合的,它的原理是在损失函数后加一个L1或者L2范数。
L1:
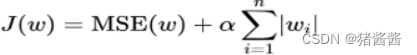
L2:
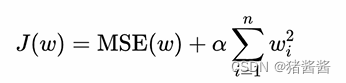
正则化L1
from sklearn.linear_model import Lasso
l=Lasso(alpha=0.005,normalize=True)
l.fit(x_train,y_train)
print(lp.coef_)
print(lp.intercept_)
参数alpha表示下降速率,normalize表示是否正则化
8. L2正则化
# 正则化L2
from sklearn.linear_model import Ridge
r = Ridge(alpha=0.005,normalize=True)
r.fit(x_train,y_train)
print(r.coef_)
print(r.intercept_)
9. 模型预测
# 模型预测
# 预测L1正则化
# predict=l.predict(x_test)
# 预测L2正则化
# predict=r.predict(x_test)
# 预测正规方程法
# predict=lr.predict(x_test)
# 预测梯度下降算法
predict=sr.predict(x_test)10. 模型评估
这里使用MSE评估方法,也就是均方差,mean_squared_error
# 6. 模型评估
from sklearn.metrics import mean_squared_error
# 6.1 L1正则化评估
# err_l1 = mean_squared_error(y_test,predict)
# print(err_l1)
# 6.2 L2正则化评估
# err_l2 = mean_squared_error(y_test,predict)
# print(err_l2)
# 6.3 正规方程法评估
# err_lr = mean_squared_error(y_test,predict)
# print(err_lr)
# 6.4 梯度下降算法评估
err_sgd = mean_squared_error(y_test,predict)
print(err_sgd)














 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









