






目录
selenium介绍与安装

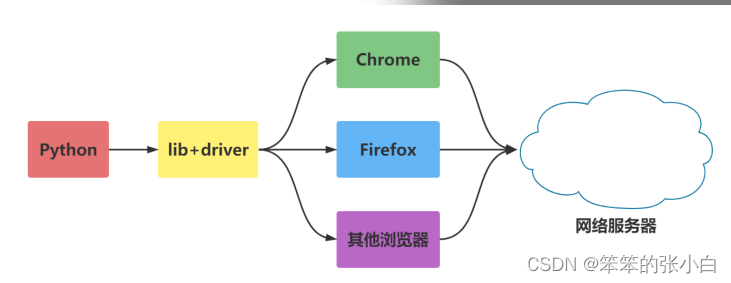
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试 而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自 动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主 流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要 的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方 浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码 中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览 器。
PyPI网站下载 Selenium库 https://pypi.python.org/simple/seleni um ,也可以用第三方管理器 Selenium 官方参考文档:http://selenium-python.readthedocs.i o/index.html
安装
pip install selenium安装Firefox geckodriver
安装firefox最新版本,添加Firefox可执行程序到系统环境变量。记得关闭firefox的自动更新
firefox下载地下:https://github.com/mozilla/geckodriver/releas es 将下载的geckodriver.exe 放到path路径下 D:\Python\python_version\
安装ChromeDriver
http://chromedriver.storage.googleapis.com/index.html
注意 版本号要对应
测试代码
# 导入 webdriver
from selenium import webdriver
# 要想调用键盘按键操作需要引入keys包
from selenium.webdriver.common.keys importKeys
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.Chrome()
# 如果没有在环境变量指定PhantomJS位置
# driver = webdriver.Chrome(executable_path="./phantomjs"))
# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com/")
# 打印网页渲染后的源代码
print(driver.page_source)
# 生成新的页面快照
driver.save_screenshot("python爬虫.png")
# 获取当前url
print(driver.current_url)
# 关闭浏览器
driver.quit()selenium 控制浏览器
最大化窗口
我们知道调用启动的浏览器不是全屏的,这样不会影响脚本的执 行,但是有时候会影响我们“观看”脚本的执行。
browser = webdriver.Chrome()
url= 'http://www.baidu.com'
browser.get(url)
borwser.maximize_window()设置宽与高
最大化还是不够灵活,能不能随意的设置浏览的宽、高显示?当然 是可以的。
browser = webdriver.Chrome()
url= 'http://www.baidu.com'
browser.get(url)
borwser.set_window_size(500,600)浏览器前进、后退
浏览器上有一个后退、前进按钮,对于浏览网页的人是比较方便 的;对于做web自动化测试的同学来说应该算是一个比较难模拟的 问题 其实很简单,下面看看python的实现方式
browser = webdriver.Chrome()#访问百度首页
first_url= 'http://www.baidu.com'
browser.get(first_url)
time.sleep(2)#访问新闻页面
second_url='http://news.baidu.com'
browser.get(second_url)
time.sleep(2)#返回(后退)到百度首页print "back to %s "%(first_url)
browser.back()
time.sleep(1) #前进到新闻页print "forward to %s"%(second_url)
browser.forward()
time.sleep(2)
browser.quit()
selenium元素定位
对象的定位应该是自动化的核心,要想操作一个对象,首先应该识 别这个对象。 一个对象就是一个人一样,他会有各种的特征(属性),如比我们 可以通过一个人的身份证号,姓名,或者他住在哪个街道、楼层、门牌找到这个人。
对象定位
webdriver提供了对象定位方法
- find_element(type,value)
- find_elements(type,value)
利用 By 类来确定哪种选择方式
from selenium.webdriver.common.by import By
chrome.find_element(by=By.ID,value='su')
By 类的一些属性如下
- ID = "id"
- NAME = "name"
- XPATH = "xpath"
- LINK_TEXT = "link text"
- PARTIAL_LINK_TEXT = "partial link text"
- TAG_NAME = "tag name"
- CLASS_NAME = "class name"
- CSS_SELECTOR = "css selector"
操作元素
前面讲到了不少知识都是定位元素,定位只是第一步,定位之后需 要对这个原素进行操作。 鼠标点击呢还是键盘输入,这要取决于我们定位的是按钮还输入 框。
一般来说,webdriver中比较常用的操作对象的方法有下面几个:
- click 点击对象
- send_keys 在对象上模拟按键输入
- clear 清除对象的内容,如果可以的话
from selenium import webdriver
from selenium.webdriver.chrome.service
import Service
from time import sleep
from selenium.webdriver.common.by import By
def test_element():
# 创建驱动对象
s =Service(executable_path='./chromedriver.exe')
# 创建一个浏览器
driver = webdriver.Chrome(service=s)
# 打个百度
driver.get('https://cn.bing.com/')
sleep(2)
# 获取 搜索框,并输出“学习”
driver.find_element(By.ID,'sb_form_q').send_keys('学习')
sleep(1)
# 获取 搜索按钮,并点击
driver.find_element(By.ID,'search_icon').click()
if __name__ =='__main__':
test_element()selenium定位下拉菜单
包含下拉菜单页面
<html>
<head>
<meta http-equiv="content-type"
content="text/html;charset=utf-8" />
<title>Level Locate</title>
<script type="text/javascript"
src="https://cdn.jsdelivr.net/npm/jquery@1.1
2.4/dist/jquery.min.js"></script>
<link
href="https://cdn.jsdelivr.net/npm/@bootcss/
v3.bootcss.com@1.0.9/dist/css/bootstrap.min.
css" rel="stylesheet" />
</head>
<body>
<h3>Level locate</h3>
<div class="span3 col-md-3">
<div class="well">
<div class="dropdown">
<a class="dropdowntoggle" data-toggle="dropdown"
href="#">Link1</a>
<ul class="dropdownmenu" role="menu" aria-labelledby="dLabel"
id="dropdown1" >
<li><a tabindex="-1"
href="http://www.baidu.com">Action</a></li>
<li><a tabindex="-1"
href="#">Another action</a></li>
<li><a tabindex="-1"
href="#">Something else here</a></li>
<li class="divider">
</li>
<li><a tabindex="-1"
href="#">Separated link</a></li>
</ul>
</div>
</div>
</div>
<div class="span3 col-md-3">
<div class="well">
<div class="dropdown">
<a class="dropdowntoggle" data-toggle="dropdown"
href="#">Link2</a>
<ul class="dropdownmenu" role="menu" aria-labelledby="dLabel" >
<li><a tabindex="-1"
href="#">Action</a></li>
<li><a tabindex="-1"
href="#">Another action</a></li>
<li><a tabindex="-1"
href="#">Something else here</a></li>
<li class="divider">
</li>
<li><a tabindex="-1"
href="#">Separated link</a></li>
</ul>
</div>
</div>
</div>
</body>
<script
src="https://cdn.jsdelivr.net/npm/@bootcss/v
3.bootcss.com@1.0.9/dist/js/bootstrap.min.js
"></script></html>选中元素
from selenium import webdriver
from selenium.webdriver.chrome.service
import Service
from selenium.webdriver.common.by import By
import os
from time import sleep
def test_down_menu():
# 创建一个驱动
s =Service(executable_path='./chromedriver.exe')
# 创建浏览器
driver = webdriver.Chrome(service=s)
# 设置方位的文件地址
file_path = 'file:///'+os.path.abspath('./html/test01.html')
# 访问页面
driver.get(file_path)
# 定位父级元素
driver.find_element(By.LINK_TEXT,'Link1').click()
# 找到要移动的位置
menu = driver.find_element(By.LINK_TEXT,'Action')
# 做一个移动光标的动作
# 定义一个动作在driver 移动到menu的位置 执行动作
webdriver.ActionChains(driver).move_to_element(menu).perform()
# sleep(2)
# 定位子级元素
menu.click()
# 睡眠2秒
sleep(2)
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
test_down_menu()selenium 层级定位

窗口的定位
对于一个现代的web应用,经常会出现框架(frame) 或窗口 (window)的应用,这也就给我们的定位带来了一个难题。 有时候我们定位一个元素,定位器没有问题,但一直定位不了,这 时候就要检查这个元素是否在一个frame中,seelnium webdriver 提供了一个switch_to_frame方法,可以很轻松的来解决这个问题
多层框架或窗口的定位: driver.switch_to.frame()
frame.html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>frame</title>
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/jquery@1.12.4/dist/jquery.min.js"></script>
<link href="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstrap-combined.min.css"
rel="stylesheet" />
</head>
<body>
<div class="row-fluid">
<div class="span10 well">
<h3>frame</h3><iframe id="f1" src="inner.html" width="1500" , height="1200"></iframe>
</div>
</div>
</body>
<script src="https://cdn.jsdelivr.net/npm/@bootcss/v3.bootcss.com@1.0.8/dist/js/bootstrap.min.js"></script></html>
</html>inner.html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>inner</title>
</head>
<body>
<div class="row-fluid">
<div class="span6 well">
<h3>inner</h3><iframe id="f2" src="https://cn.bing.com/" width="1400" height="1100"></iframe>
</div>
</div>
</body>
</html>switch_to_frame()
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
import os
from time import sleep
def select_frame():
# 创建驱动
s = Service(executable_path='./chromedriver.exe')
# 创建浏览器
driver = webdriver.Chrome(service=s)
file_path = 'file:///' + os.path.abspath('./html/outer.html')
# 打开网页
driver.get(file_path)
# 切换frame
driver.switch_to.frame('f1')
driver.switch_to.frame('f2')
# 定位元素,输入要搜索的内容
driver.find_element(By.ID,'sb_form_q').send_keys('百战')
# 定位按钮,点击搜索
driver.find_element(By.ID,'search_icon').click()
sleep(3)
driver.quit()
if __name__ =='__main__':
select_frame()selenium 处理下拉框

在爬取数据时,有时数据太多,而官网提供了筛选功能select标 签,像这样的数据,我们只需要定位元素,点击即可。
drop_down.html
<html>
<body>
<select id="ShippingMethod" onchange="updateShipping(options[selectedIndex]);" name="ShippingMethod">
<option value="12.51">UPS Next Day Air ==> $12.51</option>
<option value="11.61">UPS Next Day Air Saver ==> $11.61</option>
<option value="10.69">UPS 3 Day Select ==> $10.69</option>
<option value="9.03">UPS 2nd Day Air ==> $9.03</option>
<option value="8.34">UPS Ground ==> $8.34</option>
<option value="9.25">USPS Priority Mail Insured ==> $9.25</option>
<option value="7.45">USPS Priority Mail ==> $7.45</option>
<option value="3.20" selected="">USPS First Class ==> $3.20</option>
</select>
<select id="ShippingMethod2" onchange="updateShipping(options[selectedIndex]);" name="ShippingMethod">
<option value="12.51">UPS Next Day Air ==> $12.51</option>
<option value="11.61">UPS Next Day Air Saver ==> $11.61</option>
<option value="10.69">UPS 3 Day Select ==> $10.69</option>
<option value="9.03">UPS 2nd Day Air ==> $9.03</option>
<option value="8.34">UPS Ground ==> $8.34</option>
<option value="9.25">USPS Priority Mail Insured ==> $9.25</option>
<option value="7.45">USPS Priority Mail ==> $7.45</option>
<option value="3.20" selected="">USPS First Class ==> $3.20</option>
</select>
</body>
</html>from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import os
def choose_option():
# 创建驱动
s = Service('./chromedriver.exe')
# 创建浏览器对象
driver = webdriver.Chrome(service=s)
# 访问页面
# 设置页面地址
file_path = 'file:///' + os.path.abspath('./html/test02.html')
driver.get(file_path)
# 定位下拉框里面选项
sleep(2)
driver.find_element(By.XPATH,'//select[@id="ShippingMethod"]/option[@value="10.69"]').click()
sleep(2)
driver.find_element(By.XPATH,'//select[@id="ShippingMethod2"]/option[@value="9.25"]').click()
# 关闭浏览器
sleep(5)
driver.quit()
if __name__ == '__main__':
choose_option()selenium处理弹窗

有时,页面可能要弹窗口。只需要去定位弹窗上的“确定”按钮即可
- switch_to 焦点集中到页面上的一个警告(提示) a
- ccept() 接受警告提示
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>This is a page</title>
</head>
<body>
<div id = "container">
<div style="font: size 30px;">Hello,Python Spider</div>
</div>
</body>
<script>
alert('这个是测试弹窗')
</script>
</html>from lib2to3.pgen2 import driver
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from time import sleep
import os
def test_windows():
# 创建驱动对象
s = Service('./chromedriver.exe')
# 创建浏览器
driver = webdriver.Chrome(service=s)
# 访问页面
# 设置页面地址
file_path = 'file:///' + os.path.abspath('./html/test03.html')
driver.get(file_path)
sleep(3)
# 定位弹出窗口,并点击
driver.switch_to.alert.accept()
sleep(3)
driver.quit()
if __name__ =='__main__':
test_windows()selenium拖拽元素

要完成元素的拖拽,首先需要指定被拖动的元素和拖动目标元素, 然后利用 ActionChains 类来实现,ActionChains用于定制动作。 通过ActionChains对象中的perform()执行动作,
html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>jQuery UI Draggable - Auto-scroll</title>
<link rel="stylesheet" href="http://code.jquery.com/ui/1.12.1/themes/base/jquery-ui.css">
<style>
#draggable, #draggable2, #draggable3 { width: 100px; height: 100px; padding: 0.5em; float: left; margin: 0 10px 10px 0; }
body {font-family: Arial, Helvetica, sans-serif;}
table {font-size: 1em;}
.ui-draggable, .ui-droppable {background-position: top;}
</style>
<script src="https://code.jquery.com/jquery-1.12.4.js"></script>
<script src="https://code.jquery.com/ui/1.12.1/jquery-ui.js"></script>
<script>
$( function() {
$( "#draggable" ).draggable({ scroll: true });
$( "#draggable2" ).draggable({ scroll: true, scrollSensitivity: 100 });
$( "#draggable3" ).draggable({ scroll: true, scrollSpeed: 100 });
} );
</script>
</head>
<body>
<div id="draggable" class="ui-widget-content">
<p>Scroll set to true, default settings</p>
</div>
<div id="draggable2" class="ui-widget-content">
<p>scrollSensitivity set to 100</p>
</div>
<div id="draggable3" class="ui-widget-content">
<p>scrollSpeed set to 100</p>
</div>
<div style="height: 5000px; width: 1px;"></div>
</body>
</html>python
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import os
def test_drop():
# 创建驱动对象
s = Service('./chromedriver.exe')
# 创建浏览器
driver = webdriver.Chrome(service=s)
# 访问页面
# 设置页面地址
file_path = 'file:///' + os.path.abspath('./html/test04.html')
driver.get(file_path)
# 定位要拖拽的元素
div1 = driver.find_element(By.ID,'draggable')
div2 = driver.find_element(By.ID,'draggable2')
div3 = driver.find_element(By.ID,'draggable3')
# 开始拖拽
# 定义事件
sleep(2)
webdriver.ActionChains(driver).drag_and_drop(div1,div2).perform()
for i in range(10):
webdriver.ActionChains(driver).drag_and_drop_by_offset(div3,10,10).perform()
sleep(0.5)
# 关闭浏览器
sleep(3)
driver.quit()
if __name__ =='__main__':
test_drop()selenium调用js方法

有时候我们需要控制页面滚动条上的滚动条,但滚动条并非页面上 的元素,这个时候就需要借助js是来进行操作
一般用到操作滚动条的会两个场景:
- 1 要操作的页面元素不在当前页面范围,无法进行操作,需要拖动滚动条
- 2 注册时的法律条文需要阅读,判断用户是否阅读的标准是:滚动条是否拉到最下方
调用js的方法
execute_script(script, *args)滚动条回到顶部:
js="document.getElementById('id').scrollTop=0"
driver.execute_script(js)滚动条拉到底部
js="document.documentElement.scrollTop=10000"
driver.execute_script(js)可以修改scrollTop 的值,来定位右侧滚动条的位置,0是最上面, 10000是最底部
以上方法在Firefox和IE浏览器上上是可以的,但是用Chrome浏览 器,发现不管用。Chrome浏览器解决办法:
js = "document.body.scrollTop=0"
driver.execute_script(js)横向滚动条
js = "window.scrollTo(100,400)"
driver.execute_script(js)selenium 等待元素

- 网速慢
- AJAX请求数据
- 调试
强制等待
使用 time.sleep
作用:当代码运行到强制等待这一行的时候,无论出于什么原因, 都强制等待指定的时间,需要通过time模块实现
优点:简单
缺点:无法做有效的判断,会浪费时间
隐式等待
chrome.implicitly_wait(time_num)
到了一定的时间发现元素还没有加载,则继续等待我们指定的 时间,如果超过了我们指定的时间还没有加载就会抛出异常, 如果没有需要等待的时候就已经加载完毕就会立即执行
优点: 设置一次即可
缺点:必须等待加载完成才能到后续的操作,或者等待超时才能进 入后续的操作
显示等待
from selenium.webdriver.support.wait import WebDriverWait
指定一个等待条件,并且指定一个最长等待时间,会在这个时 间内进行判断是否满足等待条件,如果成立就会立即返回,如 果不成立,就会一直等待,直到等待你指定的最长等待时间, 如果还是不满足,就会抛出异常,如果满足了就会正常返回
优点:专门用于对指定一个元素等待,加载完即可运行后续代码
缺点:多个元素都需要要单独设置等待
url = 'https://www.guazi.com/nj/buy/'
driver = webdriver.Chrome()
driver.get(url)
wait = WebDriverWait(driver,10,0.5)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'next')))
print(driver.page_source)selenium 参数使用

包括无头模式,代理模式,绕过检测
from selenium.webdriver.chrome.service import Service
from selenium.webdriver import Chrome,ChromeOptions,DesiredCapabilities
from time import sleep
def test_headless():
# 设置参数,将浏览器隐藏起来(无头浏览器)
options = ChromeOptions()
options.add_argument('--headless')
# 设置驱动
service = Service('./chromedriver')
# 启动Chrome浏览器
driver = Chrome(service=service,options=options)
# 访问页面
driver.get('https://www.baidu.com')
# 打印代码
print(driver.page_source)
# 关闭浏览器
driver.quit()
def test_proxy1():
# 设置参数,给浏览器设置代理
options = ChromeOptions()
# options.add_argument('--proxy-server=http://ip:port')
options.add_argument('--proxy-server=http://221.199.36.122:35414')
# 设置驱动
service = Service('./chromedriver')
# 启动Chrome浏览器
driver = Chrome(service=service,options=options)
# 访问页面 "134.195.101.16",
driver.get('http://httpbin.org/get')
# 打印代码
print(driver.page_source)
# 关闭浏览器
driver.quit()
def test_proxy2():
from selenium.webdriver.common.proxy import ProxyType,Proxy
# 设置参数,给浏览器设置代理
ip = 'http://113.76.133.238:35680'
proxy = Proxy()
proxy.proxy_type = ProxyType.MANUAL
proxy.http_proxy = ip
proxy.ssl_proxy = ip
# 关联浏览器
capabilities = DesiredCapabilities.CHROME
proxy.add_to_capabilities(capabilities)
# 设置驱动
service = Service('./chromedriver')
# 启动Chrome浏览器
driver = Chrome(service=service,desired_capabilities=capabilities)
# 访问页面 "134.195.101.16",
driver.get('http://httpbin.org/get')
# 打印代码
print(driver.page_source)
# 关闭浏览器
driver.quit()
def test_find():
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
chrome = Chrome(chrome_options=options)
chrome.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => false
})
"""
})
chrome.get('http://httpbin.org/get')
info = chrome.page_source
print(info)
sleep(20)
if __name__ =='__main__':
# test_headless()
# test_proxy1()
# test_proxy2()
test_find()Selenium实战案例

from selenium.webdriver.chrome.service import Service
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
from lxml import etree
def spider_huya():
# 创建一个驱动
service = Service('./chromedriver.exe')
# 创建一个浏览器
driver = Chrome(service=service)
# 设置隐式等待
driver.implicitly_wait(5)
# 访问网址
driver.get('https://www.huya.com/g/lol')
count = 1
while True:
# print('获取了第%d页' % count)
# count += 1
# 提取数据
e = etree.HTML(driver.page_source)
names = e.xpath('//i[@class="nick"]/@title')
person_nums = e.xpath('//i[@class="js-num"]/text()')
# 打印数据
# for n,p in zip(names,person_nums):
# print(f'主播名:{n} 人气:{p}')
# 找到下一页的按钮
# try:
# next_btn = driver.find_element(By.XPATH,'//a[@class="laypage_next"]')
# next_btn.click()
# except Exception as e:
# break
if driver.page_source.find('laypage_next') == -1:
break
next_btn = driver.find_element(By.XPATH,'//a[@class="laypage_next"]')
next_btn.click()
# 关闭浏览器
driver.quit()
if __name__ == '__main__':
spider_huya()
















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











