







DFP算法是一种数值优化算法,用于在多元函数中求解最小值点。DFP代表Davidon-Fletcher-Powell,是由Davidon, Fletcher和Powell等人在1960年代提出的。
DFP算法的基本思路是通过构造一个近似的海森矩阵来模拟目标函数的局部二次特性,并使用这个矩阵来计算每个迭代步的搜索方向和步长。其核心思想是在每一次迭代中,利用之前的迭代信息来更新海森矩阵,以得到更好的搜索方向和步长。
下面是DFP算法的步骤:
-
初始化。选择初始点 x_0,初始近似海森矩阵 H_0,迭代计数器 k=0。
-
计算梯度。计算目标函数在当前点的梯度向量 g_k=f'(x_k)。
-
判断终止条件。如果满足一定的停止准则(例如梯度的大小小于某个阈值或迭代次数达到预设值等),则停止迭代,输出当前点 x_k。
-
计算搜索方向。计算搜索方向 p_k,满足 p_k=-H_k g_k。
-
选择步长。使用一维搜索方法(如Armijo规则)选择步长 alpha_k,满足 f(x_k+alpha_k p_k)<f(x_k)。
-
更新迭代点。更新迭代点 x_{k+1}=x_k+alpha_k p_k。
-
更新海森矩阵。根据迭代点的变化和梯度的变化,更新近似海森矩阵 H_{k+1}。
-
更新迭代计数器。将迭代计数器加1,返回步骤2。
重复执行步骤2到8,直到满足终止条件为止。
以下是一个简单的Python实现DFP算法的示例代码:
import numpy as np
def dfp(func, grad, x0, max_iter=1000, tol=1e-6):
n = len(x0)
H = np.eye(n)
x = x0.copy()
for k in range(max_iter):
g = grad(x)
if np.linalg.norm(g) < tol:
break
p = -H @ g
alpha = backtracking_line_search(func, grad, x, p)
s = alpha * p
x_next = x + s
y = grad(x_next) - g
rho = 1 / (y.T @ s)
H = (np.eye(n) - rho * s.reshape(-1, 1) @ y.reshape(1, -1)) @ H @ (np.eye(n) - rho * y.reshape(-1, 1) @ s.reshape(1, -1)) + rho * s.reshape(-1, 1) @ s.reshape(1, -1)
x = x_next
return x
其中,func表示目标函数,grad表示目标函数的梯度,x0表示初始点,max_iter表示最大迭代次数,tol表示梯度的大小的阈值。
在上述代码中,我们首先初始化海森矩阵 H 为单位矩阵,并复制初始点 x0。然后,在迭代过程中,我们计算梯度 g,判断终止条件是否满足。如果终止条件不满足,则计算搜索方向 p,选择步长 alpha,更新迭代点 x_next,计算梯度的变化量 y,以及更新海森矩阵 H。最后,更新当前点 x。重复执行上述步骤直到满足终止条件为止。在搜索方向的计算中,我们使用了矩阵乘法运算 @,而在海森矩阵的更新中,我们使用了向量的外积运算 reshape(-1, 1) @ reshape(1, -1)。
需要注意的是,在以上代码中,我们使用了一个名为 backtracking_line_search 的函数来实现一维搜索。该函数需要在外部定义,它的输入参数包括目标函数、目标函数梯度、当前点、搜索方向,它的输出是合适的步长。在实现中,我们可以使用Armijo规则等一维搜索算法来实现 backtracking_line_search 函数。
假设我们要使用DFP算法来求解以下函数的最小值:
![]()
该函数的梯度为:
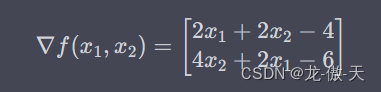
我们可以使用以下Python代码来实现DFP算法:
import numpy as np
def f(x):
return x[0]**2 + 2*x[1]**2 + 2*x[0]*x[1] - 4*x[0] - 6*x[1]
def grad(x):
return np.array([2*x[0] + 2*x[1] - 4, 4*x[1] + 2*x[0] - 6])
x0 = np.array([0, 0])
x_opt = dfp(f, grad, x0)
print("最小值点:", x_opt)
print("最小值:", f(x_opt))
在上述代码中,我们首先定义了目标函数 f 和梯度函数 grad。然后,我们选择初始点 (0, 0),并使用 dfp 函数来求解最小值点。最后,我们输出最小值点和最小值。
下面是一个使用Python和Matplotlib库来可视化DFP算法的示例代码。我们仍然使用上一问中的函数
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def f(x):
return x[0]**2 + 2*x[1]**2 + 2*x[0]*x[1] - 4*x[0] - 6*x[1]
def grad(x):
return np.array([2*x[0] + 2*x[1] - 4, 4*x[1] + 2*x[0] - 6])
def dfp(func, grad, x0, max_iter=1000, tol=1e-6):
n = len(x0)
H = np.eye(n)
x = x0.copy()
x_list = [x]
for k in range(max_iter):
g = grad(x)
if np.linalg.norm(g) < tol:
break
p = -H @ g
alpha = backtracking_line_search(func, grad, x, p)
s = alpha * p
x_next = x + s
y = grad(x_next) - g
rho = 1 / (y.T @ s)
H = (np.eye(n) - rho * s.reshape(-1, 1) @ y.reshape(1, -1)) @ H @ (np.eye(n) - rho * y.reshape(-1, 1) @ s.reshape(1, -1)) + rho * s.reshape(-1, 1) @ s.reshape(1, -1)
x = x_next
x_list.append(x)
return x_list
def backtracking_line_search(func, grad, x, p, alpha=1, rho=0.5, c=0.1):
while func(x + alpha * p) > func(x) + c * alpha * grad(x) @ p:
alpha = rho * alpha
return alpha
x0 = np.array([0, 0])
x_list = dfp(f, grad, x0)
x1 = np.linspace(-5, 5, 100)
x2 = np.linspace(-5, 5, 100)
X1, X2 = np.meshgrid(x1, x2)
Y = f([X1, X2])
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X1, X2, Y, cmap='coolwarm', alpha=0.8)
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('Y')
x_list = np.array(x_list)
ax.plot(x_list[:, 0], x_list[:, 1], f(x_list.T), color='black', linewidth=2)
plt.show()
在上述代码中,我们首先定义了目标函数 f 和梯度函数 grad。然后,我们选择初始点 (0, 0),并使用 dfp 函数来求解最小值点,并将所有迭代点记录在 x_list 中。最后,我们使用Matplotlib库来绘制函数的3D图像。



















 6340
6340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











