






👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
波长变量筛选的方法主要有相关系数法,逐步回归法,无信息变量消除法(UVE),遗传算法(genetic algorithm,GA)等,其中无信息变量消除法的研究和应用在国内的报道较少。无信息变量消除算法是新的变量筛选方法,该算法最初由Centner等人提出来,并用于NIR光谱数据,其目的是为了减少最终PLS模型中包含的变量数,降低模型的复杂性,改善PLS模型,还与其它相关方法进行了比较,UVE方法得到的结果的SEP最小。
无信息变量消除(Variable Elimination with No Information,VENI)是一种在概率推理和图模型领域,特别是贝叶斯网络中应用广泛的技术。其目的是通过消除(或归纳整合)网络中的部分变量,来简化推理问题,进而降低计算复杂度。这种方法尤其适用于处理条件独立性丰富的场景,比如在概率图模型中利用条件独立关系来减少查询变量时所需的计算量。以下是关于无信息变量消除法的研究及其实现的一个概括性文档框架:
概述
目的:无信息变量消除的主要目标是在不丢失关于感兴趣变量(查询变量)的信息的前提下,从模型中移除不直接影响查询结果的变量,从而简化推理过程。
应用场景:此方法广泛应用于机器学习、数据挖掘、人工智能等领域中的概率推理,特别是在处理复杂概率网络的高效查询和诊断问题时。
基本原理
条件独立性:贝叶斯网络中一个核心概念是条件独立性,即给定某些变量后,其他变量间的依赖关系可以被切断。这是VENI算法能有效减少计算复杂度的基础。
消除顺序:选择一个有效的变量消除顺序至关重要。通常,应优先消除那些具有高连接度但对查询结果贡献较小的变量,减少后续计算的复杂性。
消息传递与归纳:消除一个变量的过程涉及将其邻接节点间的所有概率信息合并(即消息传递),然后通过求和或乘积操作(取决于节点类型)来消除该变量,形成新的条件概率分布。
实现步骤
- 定义问题:明确贝叶斯网络结构、条件概率表、查询变量和证据变量。
- 确定消除顺序:基于网络结构和查询需求,决定一个最优或次优的变量消除顺序。
- 消息传递:对于每个变量,根据其在消除顺序中的位置,依次计算并传递消息给其邻居,这些消息反映了在考虑其他已消除变量的条件下,关于该变量的信息。
- 消除变量:在所有与待消除变量相关联的消息传递完成后,执行归纳操作,消除该变量,更新剩余变量间的条件概率。
- 递归执行:重复步骤3至4,直至所有非查询变量均被消除。
- 计算答案:最后,根据剩余的条件概率分布计算查询变量的概率。
算法优化
- 最优消除顺序搜索:使用启发式方法(如最小剩余弧或最短路径)寻找最优的变量消除顺序。
- 剪枝技术:实施如约简因子图或早期终止规则来减少不必要的计算。
- 并行化与分布式处理:鉴于消息传递的独立性,可以利用并行计算资源加速算法执行。
实现示例
实现无信息变量消除法通常涉及编程语言中的数据结构设计(如邻接表表示贝叶斯网络)、算法编码(消息传递和消除步骤的循环)以及性能优化(如使用高效的数据结构和并行计算)。示例代码可能会用到Python等高级语言,结合NumPy等库进行高效的矩阵操作,或直接使用专门的图形模型工具包如PGM或Pyro等,这些工具包通常内置了对VE算法的支持。
结论
无信息变量消除法是处理复杂概率推理问题的有效策略,通过智能化地利用条件独立性,显著减少了计算负担,提升了大规模概率网络的查询效率。其应用价值在于促进了一系列需要高效概率推理任务的实现,如在医疗诊断、推荐系统、风险管理等多个领域的决策支持系统中。未来的研究方向可能包括进一步优化算法性能、扩展到更复杂网络模型(如动态贝叶斯网络)以及结合新兴的机器学习技术进行自动化优化。
📚2 运行结果
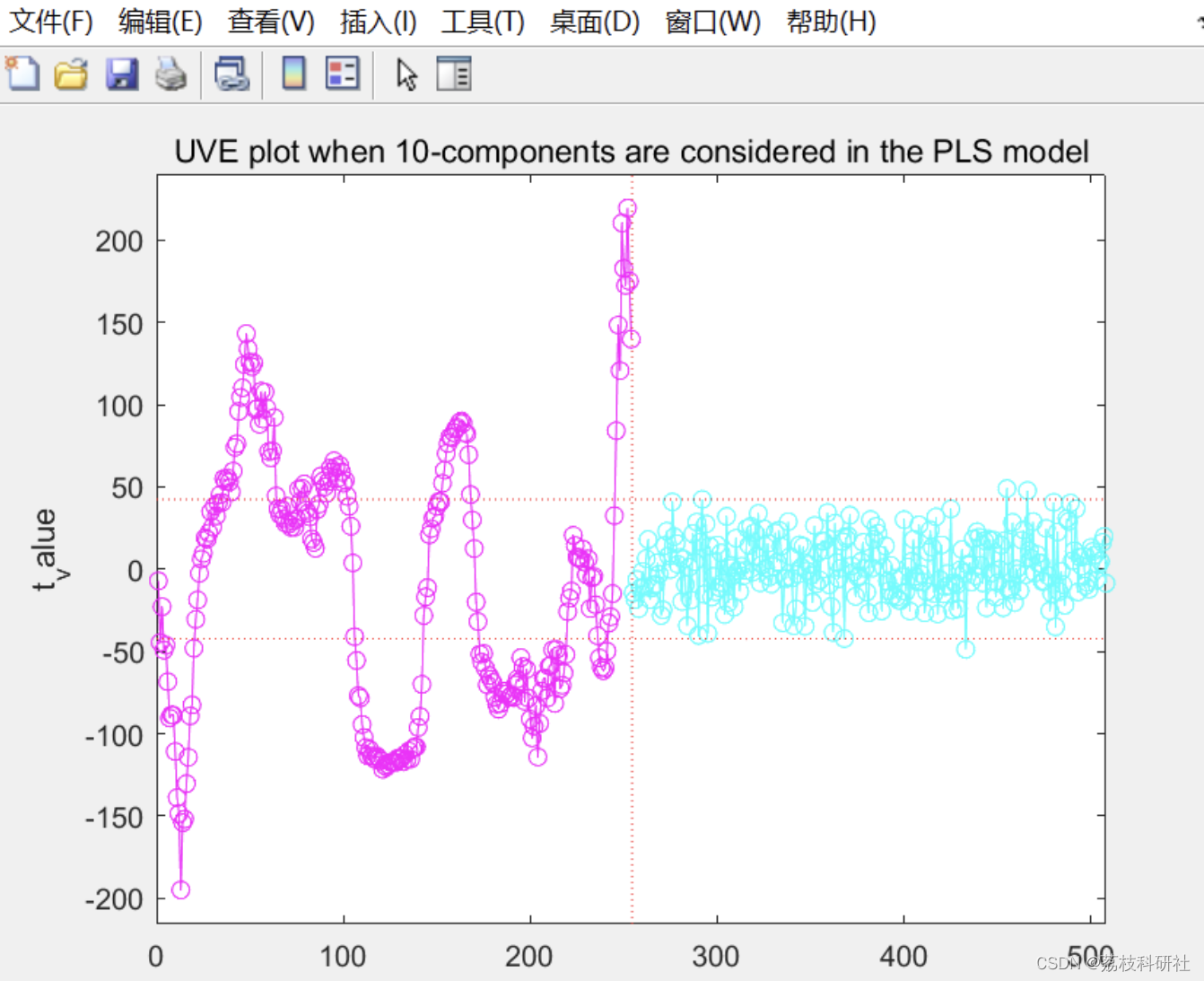
部分代码:
clear all
clc
%% 训练集/测试集产生
load('RAW.mat');
RAW1=RAW(:,:);
RAW=RAW1(:,1:254);
LLL=RAW1(:,255);
[oo, pp]=size(RAW);
temp = randperm(oo);%训练集和预测集按照3:1分类
P_train = RAW(temp(1:300),:);
T_train = LLL(temp(1:300),:);
P_test = RAW(temp(301:end),:);
T_test = LLL(temp(301:end),:);
X=RAW(:,:);
y=LLL(:,:);
%% 无信息变量消除法实现
[mean_b,std_b,t_values,var_retain,RMSECVnew,Yhat,E]=plsuve(X,y,10,400,254);%10是最佳因子数,400是留一法的次数,一般取样本数,254是加入的随机噪声的波段数,可以取等值也就是样本波段数,其他的参
部分代码:
clear all
clc
%% 训练集/测试集产生
load('RAW.mat');
RAW1=RAW(:,:);
RAW=RAW1(:,1:254);
LLL=RAW1(:,255);
[oo, pp]=size(RAW);
temp = randperm(oo);%训练集和预测集按照3:1分类
P_train = RAW(temp(1:300),:);
T_train = LLL(temp(1:300),:);
P_test = RAW(temp(301:end),:);
T_test = LLL(temp(301:end),:);
X=RAW(:,:);
y=LLL(:,:);
%% 无信息变量消除法实现
[mean_b,std_b,t_values,var_retain,RMSECVnew,Yhat,E]=plsuve(X,y,10,400,254);%10是最佳因子数,400是留一法的次数,一般取样本数,254是加入的随机噪声的波段数,可以取等值也就是样本波段数,其他的参
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]陈媛媛,王志斌,王召巴.基于无信息变量消除法与岭极限学习机的新型变量选择方法:以CO气体浓度反演为例(英文)[J].光谱学与光谱分析,2017,37(01):299-305.















 1789
1789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









