







1. 什么是决策树
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
- 决策树具有极强的解释性
- 程序解释:决策树 就是if...else...的嵌套
- 几何解释:决策树 就是一组平行于轴的超平面的分割
1.1 决策树的学习过程
- 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
- 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树。
- 剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
- 实现决策树的算法包括ID3、C4.5算法等。
1.2 熵(Entropy)
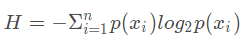
其中,n 为分类数目,熵越大,随机变量的不确定性就越大。
- 当所有类有相等的占比(概率)时,特征的熵值最大
- 因此也可得出:熵表示了数据具有一定的随机性
1.3 条件熵
 ,其中
,其中
条件熵H(Y∣X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy)
1.4 信息增益(Information Gain)
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度。信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差.
一般地,熵H(D)与条件熵H(D|A)之差成为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
2. 决策树算法
2.1 ID3算法
ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。信息熵(entropy)是用来衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。
- 没有剪枝过程,为了去除过渡数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点;
- 信息增益的方法偏向选择具有大量值的属性,也就是说某个属性特征索取的不同值越多,那么越有可能作为分裂属性,这样是不合理的;
- 只可以处理离散分布的数据特征
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。
![]()
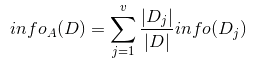
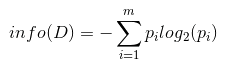
该算法使用了贪婪搜索,从不回溯重新考虑之前的选择情况
3. 单层决策树(Decision stump)
decision stump,决策树桩,也称单层决策树(a one level decision tree),单层也就意味着尽可对每一列属性进行一次判断。

决策树桩,可以说是最简单的分类器了,它的分类原理很简单:1、决定一个阈值。2、大于这个阈值的是第一类,小于这个阈值的是第二类。(等于阈值的情况任意取舍即可)。
4. 剪枝策略
- “剪枝”是决策树学习算法对付“过拟合”的主要手段。可以通过“剪枝”来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合
- 预剪枝,就是将即将发芽的分支“扼杀在萌芽状态”即在分支划分前就进行剪枝判断,如果判断结果是需要剪枝,则不进行该分支划分。有欠拟合风险
- 后剪枝,则是在分支划分之后,通常是决策树的各个判断分支已经形成后,才开始进行剪枝判断。
- 剪枝判断情况:剪枝后决策树模型在测试集验证上得到有效的提升,就判断其需要剪枝,否则不需要。
- 在实际情况中后剪枝策略使用较多。在分支生成后,使用后剪枝策略将冗余的子树及其判别条件直接剪掉,然后使用上个节点中占比最大的类做为最终的分类结果。
Reference
机器学习算法(5)——决策树(ID3、C4.5、CART)_贷款申请样本数据集决策树_菜鸟知识搬运工的博客-CSDN博客
从0到1,直观理解决策树(Decision Tree)模型 - 知乎
【数据分析】决策树案例详解_决策树经典例题及答案_答案Xstar的博客-CSDN博客















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









