







这是上一篇的继续,代码部分的实现。富文本编辑器太难用转markdown了。
我写的这个应该是网上能找到的最全最详细的了。
(别问,问就是写之前在各种网站找过)
代码设计
实验整体设计
首先读入图像,然后创建SIFT对象并获取关键点和描述子,使用detectAndCompute函数获取关键点和特征描述符。然后进行关键点匹配,创建一个暴力匹配器,返回DMatch对象列表,每个DMatch对象表示关键点的一个匹配结果,尝试所有匹配从而找到最佳匹配。其中,distance属性表示距离,距离越小匹配值越高。
print("Reading images ...")
left = cv2.imread(img1_path)
right = cv2.imread(img2_path)
print("Computing keypoints and descriptors ...")
sift = mysift.MySift()
left_kp, left_feature = sift.detectAndCompute(left, None)
right_kp, right_feature = sift.detectAndCompute(right, None)
print("Matching keypoints ...")
matcher = cv2.BFMatcher()
feature_match = matcher.knnMatch(left_feature, right_feature, k=2)
应用比例测试选择要使用的匹配结果,并将其记录到good_points和good_matches中,绘制关键点匹配图像,存储到./middle_res/before.jpg中。根据筛选出的点重新确定关键点坐标,H为转换矩阵,status为mask掩码,标注出内点与外点。
for m1, m2 in feature_match:
if m1.distance < 0.75*m2.distance:
good_points.append((m1.queryIdx, m1.trainIdx))
good_matches.append([m1])
match_img = cv2.drawMatchesKnn(left, left_kp, right, right_kp, good_matches, None, flags=2)
middle_res_path = "./middle_res/before" + img_seq + ".jpg"
cv2.imwrite(middle_res_path, match_img)
print(f" matching image is {middle_res_path}")
left_good_kp = np.float32([left_kp[i].pt for (i, _) in good_points])
right_good_kp = np.float32([right_kp[i].pt for (_, i) in good_points])
H, status = cv2.findHomography(right_good_kp, left_good_kp, cv2.RANSAC, 5.0)
计算图片的尺寸。计算左侧图像与右侧图像V分量的比例,计算左侧与右侧掩码。最后合并左图与右图,裁剪掉右侧的黑边,并将输出图像写入./result/ouputn.jpg。
left_height = left.shape[0]
left_width = left.shape[1]
right_width = right.shape[1]
mix_height = left_height # mix_height = max(l_h, r_h)
mix_width = left_width + right_width
left_mask_img = np.zeros((mix_height, mix_width, 3))
bright_k = func.compute_ratio_V(left, right)
'''
计算mask, 具体代码见3.3
'''
right_mask_img = right_mask_img * right_mask
mix_img = left_mask_img + right_mask_img
rows, cols = np.where(mix_img[:, :, 0] != 0)
output_img = mix_img[min(rows):max(rows), min(cols):max(cols), :]
result_path = "./result/output" + img_seq + ".jpg"
cv2.imwrite(result_path, output_img)
SIFT部分
该部分代码量较大,因此不列出全部代码。只介绍一些关键函数。
detectAndCompute函数
为了测试简便, 我将detectAndCompute函数的参数设为与opencv类似的形式。该函数相当于sift算法的main函数,直接调用该函数,即可得到关键点与描述符。
为加快处理速度,首先将彩色图转化为灰度图,修改数据类型,将图像扩大2倍。然后进行高斯模糊,认为原图的模糊程度为0.5,需要将其模糊到1.6。由于已经将图像扩大了一倍,所以模糊程度为2*0.5,故需要进行高斯模糊的σ为
sigma_diff = np.sqrt((self.sigma ** 2) - ((2 * self.assumed_blur) ** 2))
然后计算高斯金字塔,根据高斯金字塔计算DOG金字塔。在DOG尺度空间内找到极值点,并将其相关信息存储到kp_info中。遍历kp_info,对于其中的每一个极值点,再次进行精确定位,并计算特征点的方向角度,增加辅方向,返回一组关键点。将该组关键点从基础图像坐标转换为输入图像坐标(通过将相关属性减半),并全部加入关键点集keypoints中。由于增加了许多辅方向,关键点中可能会存在一些重复项,需要对重复项进行排序和删除。最后,生成描述符,并返回关键点与描述符。
image = cv2.GaussianBlur(init_img, (0, 0), sigmaX=sigma_diff, sigmaY=sigma_diff)
print(f" image shape is {image.shape}")
gaussian_imgs = self.buildGaussianPyramid(image)
dog_imgs = self.buildDoGPyramid(gaussian_imgs)
kp_info = self.findScaleSpaceExtrema(dog_imgs)
keypoints = []
for kp in kp_info:
local_result = self.adjustLocalExtrema(kp, dog_imgs)
if local_result is not None:
keypoint, local_index = local_result
kps_or = self.calcOrientationHist(keypoint, local_index, kp[0], gaussian_imgs)
for kp_or in kps_or:
if self.double_img_size:
kp_or.pt = 0.5 * np.array(kp_or.pt)
kp_or.size *= 0.5
kp_or.octave = (kp_or.octave & ~255) | ((kp_or.octave - 1) & 255)
keypoints.append(kp_or)
keypoints = removeDuplicateSorted(keypoints)
descriptors = self.calcSIFTDescriptors(keypoints, gaussian_imgs)
createInitialImage函数
该函数将图像转换为float32存储方式,并将图像转换为灰度图,然后将图像扩大2倍。此处需要将图像扩大2倍的原因为,最开始建立高斯金字塔时,要预先模糊输入图像作为第0个组的第0层图像。这相当于丢弃了最高的空域的采样率,因此需要先将图像尺寸扩大一倍生成-1组。
image = img_uint8_to_float32(img)
grey_img = color_to_grey_img(image)
if self.double_img_size:
bigger_img = cv2.resize(grey_img, (0, 0), fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
return bigger_img
else:
return grey_img
buildGaussianPyramid 函数
该函数的作用为构建高斯金字塔。
首先计算高斯金字塔的组数,此处需要减2,以防止降采样过程中得到过小的图像。
octaves_num = int(np.log2(min(image.shape[0], image.shape[1])) - 2)
然后调用computeGaussianKernel函数得到高斯核,根据高斯核生成高斯图像,创建尺度空间金字塔,每一层都需要根据计算出的kernel进行计算。
gaussian_kernels = self.computeGaussianKernel()
gaussian_imgs = []
next_octave_base = image
for i_octave in range(octaves_num):
octave_image = [next_octave_base]
for gaussian_sigma in gaussian_kernels[1:]:
next_octave_base = cv2.GaussianBlur(next_octave_base, (0, 0), sigmaX=gaussian_sigma,
sigmaY=gaussian_sigma)
octave_image.append(next_octave_base)
gaussian_imgs.append(octave_image)
next_octave_base = octave_image[-3]
next_octave_base = cv2.pyrDown(next_octave_base)
return np.array(gaussian_imgs)
上面代码中红框框出的部分为-3,因为降采样时,高斯金字塔一组的初始图像来自于前一组的倒数第3张图像。不妨设当前组数为o,当前组内层数为s,为了使每组具有S层DOG图像,高斯图像每组应有S+2个图像,因此s的取值范围为1~S+2。因此每组倒数第3张图像即为第S张图像,一组的初始图像等于前一组的倒数第3张图像,公式如下:
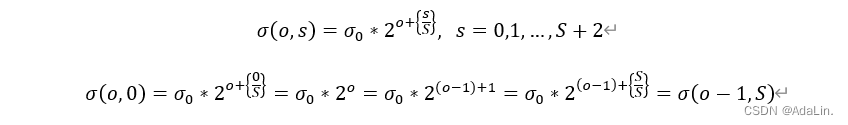
computeGaussianKernel函数
不同组相同层的组内尺度坐标σ(s)相同。若DOG图像组内层数为S,则高斯核数应为S+3,因为DOG图像是高斯图像两层相减得到的。从3.2.3的公式中可以看出,高斯核中的相邻两个数相差k=2^{1/S}倍。因此循环计算需要在前一个的基础上模糊的σ即可。
gaussian_intervals_num = self.num_intervals + 3
gaussian_kernels = np.zeros(gaussian_intervals_num)
gaussian_kernels[0] = self.sigma
# σ(o, s) = σ_0 * 2^{s/S} , s = 0, 1, ... ,S+2
k = 2 ** (1 / (gaussian_intervals_num - 3)) # k = 2^{1/S}
sigma_previous = self.sigma
for s in range(1, gaussian_intervals_num):
sigma_new = k * sigma_previous
gaussian_kernels[s] = np.sqrt(sigma_new ** 2 - sigma_previous ** 2)
sigma_previous = sigma_new
return gaussian_kernels
尺度空间里的每一层的图像(除了第1层)都是由其前面一层的图像和一个相对σ的高斯滤波器卷积生成,而不是由原图和对应尺度的高斯滤波器生成的,这一方面是因为没有“原图”,输入图像I(x,y)已经是尺度为σ=0.5的图像了;另一方面是由于如果用原图计算,那么相邻两层之间相差的尺度实际上非常小,这样会造成在做高斯差分图像的时候,大部分值都趋近于0,以致于后面很难检测到特征点。
buildDoGPyramid 函数
该函数作用为计算DOG图像金字塔。DOG图像使用相邻的两个高斯图像做差即可。
for gaussian_octave_image in gaussian_imgs:
dog_octave_image = []
for i_internal in range(len(gaussian_octave_image) - 1):
img_diff = cv2.subtract(gaussian_octave_image[i_internal], gaussian_octave_image[i_internal + 1])
dog_octave_image.append(img_diff)
dog_imgs.append(dog_octave_image)
findScaleSpaceExtrema 函数
该函数的作用为初步探测极值点,邻域为同层的8个点、上层的9个点、下层的9个点,共26个点。使用两层循环,处理每个组以及每个组中的层之间的DOG图像,获得关键点。
for i_octave in range(len(dog_imgs)):
dog_octave_img = dog_imgs[i_octave]
for i_interval in range(len(dog_octave_img) - 2):
img1 = dog_octave_img[i_interval]
img2 = dog_octave_img[i_interval + 1]
img3 = dog_octave_img[i_interval + 2]
for i in range(self.image_border_width, img1.shape[0] - self.image_border_width):
for j in range(self.image_border_width, img1.shape[1] - self.image_border_width):
if self.isScaleSpaceExtrema(img1, img2, img3, i, j):
kp_info.append([i_octave, i_interval, i, j])
如代码中框出的部分,边缘区域的5个像素范围不用来被检测关键点。
该函数非常耗时,需要若干小时才能得到全部极值点。
isScaleSpaceExtrema 函数
该函数在findScaleSpaceExtrema函数中被调用,参数为img1, img2, img3, i, j;作用为判断img2的(i, j)位置的点是否是3.2.6中提到的极值点。
该函数唯一值得一提的是阈值计算。阈值threshold用于判断DOG图像中像素值的绝对值是否足够大。此处阈值的选取参考了opencv的实现方式。将像素可能的最大值乘以(0.5*const_threshold)/(num_intervals)作为阈值,小于该阈值的点不能被当作关键点。此处的num_intervals为3,const_threshold为0.04,像素可能的最大值为255。
threshold = np.floor(0.5 * self.const_threshold / self.num_intervals * 255)
adjustLocalExtrema 函数
该函数作用为精确定位特征点,实现方法基于Lowe论文的第四部分,参数均按照Lowe论文中建议的参数设置,也部分参考了opencv的实现方式。
进行5次调整尝试,每次都计算出该点的梯度、二阶导数,得到hessian矩阵。然后使用线性回归得到调整的值xr,xc,xi。如果调整的像素小于0.5,表示已经收敛,可以直接退出尝试。否则,将调整像素大小加到原本的值中,并判断是否超出cube范围,然后进行下次尝试。如果超出范围,直接返回None,表明该处不存在极值点。如果进行完5次尝试仍未收敛,也表明此处不存在极值点,直接返回None。
如果存在极值点,则更新极值点处的函数值,然后消除边缘响应。首先保证行列式的值大于0,因为行列式等于0说明有为0的特征值,小于0说明两个特征值为一正一负,不符合对特征值描述函数变化快慢的性质的要求。然后判断变换响应,Lowe的论文中建议将r设为10。最后将得到的关键点信息整理,按照opencv中的格式进行存储。
if det <= 0 or r * (tr * tr) >= ((r + 1) ** 2) * det:
return None
keypoint = cv2.KeyPoint()
keypoint.pt = ((j + xc) * (1 << i_octave),
(i + xr) * (1 << i_octave))
keypoint.octave = i_octave + i_img * (1 << 8) + int(round((xi + 0.5) * 255)) * (1 << 16)
keypoint.size = self.sigma * (2 ** ((i_img + xi) / np.float32(self.num_intervals))) * (1 << (i_octave + 1))
keypoint.response = abs(contr)
如红框部分所示,此处应为i_octave+1,因为输入图像被扩大了,是原来的2倍。
calcOrientationHist 函数
该函数的作用为计算梯度方向直方图。这里也部分参考了opencv的实现方式,因为高斯分布的概率函数99.7%位于3个标准差内,因此这里只统计3σ之内的,即radius为3σ。在计算kpt.size时,使用了相对于第0层扩大一倍后的初始图象,因此需要乘0.5,再除以2^(i_o)。
scale = 1.5 * keypoint.size * 0.5 / (1 << i_octave)
x_center = round(keypoint.pt[0] / (1 << i_octave))
y_center = round(keypoint.pt[1] / (1 << i_octave))
radius = round(3 * scale)
使用36个方向的直方图,并使用调整后的关键点所在的dog图像层,此处不可以使用调整前的。
使用双重循环对位于关键点周围3σ范围内的点进行统计,计算其一阶导数,高斯加权,并存储。使用高斯加权可以使离关键像素较远的pixel影响较小。
for i in range(-radius, radius + 1):
y = y_center + i
if y < 0 or y >= gaussian_img.shape[0] - 1:
continue
for j in range(-radius, radius + 1):
x = x_center + j
if x <= 0 or x >= gaussian_img.shape[1] - 1:
continue
dx = gaussian_img[y, x + 1] - gaussian_img[y, x - 1]
dy = gaussian_img[y - 1, x] - gaussian_img[y + 1, x]
weight = np.exp((i * i + j * j) * -1.0 / (2 * scale * scale))
grad_collect.append([dx, dy, weight])
对于刚才存储的grad_collect,遍历统计邻域中的所有像素,计算直方图,将其梯度从360映射到36个bin中,通过取余实现循环处理。然后计算平滑后的直方图,使用了36个bin,每个bin代表10度,需要对峰值位置进行插值。最接近每一个峰值的直方图上的3个值拟合成抛物线。
for dx, dy, weight in grad_collect:
# 邻域中的所有像素
grad_orientation = np.rad2deg(np.arctan2(dy, dx))
histogram_index = int(round(grad_orientation * 36 / 360))
# 通过取余实现循环处理
raw_hist[histogram_index % 36] += np.sqrt(dx * dx + dy * dy) * weight
for n in range(36):
smooth_hist[n] = (raw_hist[n - 2] + raw_hist[(n + 2) % 36]) / 16 + (
raw_hist[n - 1] + raw_hist[(n + 1) % 36]) / 4 + 3 * raw_hist[n] / 8
最后为每个辅方向创建一个关键点。辅方向为大于0.8倍主方向的所有bin,Lowe在论文中提到,这些额外的关键点在实际应用中显著有助于检测稳定性,因此该步骤是不可或缺的。辅方向除角度外,所有参数均与原关键点相同。
calcSIFTDescriptors 函数
该函数的作用为计算生成描述子。描述符对关键点邻域的信息进行编码,Lowe提出当梯度方向直方图是44维时,SIFT,描述符具有很高的区分度。与3.2.9中不同,此处的每个梯度直方图有8个方向,一个方向代表45度。因此,每个描述符的大小为448=128,直方图宽度为4。将特征点附近邻域划分成44个子区域,每个子区域的尺寸为3σ,σ为当前特征点的尺度值。考虑到实际计算时,需要采用双线性插值,因此计算的图像区域应大于4;考虑到旋转,应再乘根号2。半径为图像区域除以2,即为
r
a
d
i
u
s
=
3
σ
∗
(
4
+
1
)
∗
√
2
/
2
radius=3σ*(4+1)*√2/2
radius=3σ∗(4+1)∗√2/2
对于每个关键点,先提取当前特征点的所在层/组/尺度,并算出角度,计算出半径radius。同时,也应确保半径小于图像斜对角线长度。
hist_width = 1.5 * scale * keypoint.size
radius = round(hist_width * np.sqrt(2) * (window_width + 1) * 0.5)
radius = min(radius, np.sqrt(gaussian_image.shape[0] ** 2 + gaussian_image.shape[1] ** 2))
使用两层循环,对上述radius范围内的所有点进行计算。为保持旋转不变性,需要先将坐标轴旋转为关键点方向,然后把邻域区域的原点从中心位置移到该区域的左下角(即加0.5倍的window_width),减0.5是为了进行坐标平移。
row_rot = col * sin_angle + row * cos_angle
col_rot = col * cos_angle - row * sin_angle
row_bin = (row_rot / hist_width) + 0.5 * window_width - 0.5
col_bin = (col_rot / hist_width) + 0.5 * window_width - 0.5
然后进行差分求梯度,计算x和y的一阶导数。这里省略了分母2,是因为没有分母不影响后面的归一化。分别计算梯度幅值、梯度辐角与高斯加权函数,并存储。
dx = gaussian_image[window_row, window_col + 1] - gaussian_image[window_row, window_col - 1]
dy = gaussian_image[window_row - 1, window_col] - gaussian_image[window_row + 1, window_col]
gradient_magnitude = np.sqrt(dx * dx + dy * dy)
gradient_orientation = np.rad2deg(np.arctan2(dy, dx)) % 360
weight = np.exp(
exp_scale * ((row_rot / hist_width) ** 2 + (col_rot / hist_width) ** 2))
row_list.append(row_bin)
col_list.append(col_bin)
magnitude_list.append(weight * gradient_magnitude)
orientation_list.append((gradient_orientation - angle) * bins_per_rad)
根据上面计算出的梯度幅值、梯度辐角、高斯加权函数的值,再次遍历,此处的实现也参考了opencv的实现思路。取三维坐标的整数部分,判断在448区域中属于哪个正方体。然后再取小数部分。将0-360度以外的角度按照圆周循环调整至0-360。
row_bin_floor = np.floor(row_bin).astype(int)
col_bin_floor = np.floor(col_bin).astype(int)
orientation_bin_floor = np.floor(orientation_bin).astype(int)
row_fraction = row_bin - row_bin_floor
col_fraction = col_bin - col_bin_floor
orientation_fraction = orientation_bin - orientation_bin_floor
if orientation_bin_floor < 0:
orientation_bin_floor += num_bins
if orientation_bin_floor >= num_bins:
orientation_bin_floor -= num_bins
按照三线性插值法,计算像素对正方体的8个顶点的贡献大小。
r1 = magnitude * row_fraction
r0 = magnitude - r1
rc11 = r1 * col_fraction
rc10 = r1 - rc11
rc01 = r0 * col_fraction
rc00 = r0 - rc01
rco111 = rc11 * orientation_fraction
rco110 = rc11 - rco111
rco101 = rc10 * orientation_fraction
rco100 = rc10 - rco101
rco011 = rc01 * orientation_fraction
rco010 = rc01 - rco011
rco001 = rc00 * orientation_fraction
rco000 = rc00 - rco001
得到像素点在三维直方图中的索引。
ori_plus = (orientation_bin_floor + 1) % num_bins
histograms[row_bin_floor + 1, col_bin_floor + 1, orientation_bin_floor] += rco000
histograms[row_bin_floor + 1, col_bin_floor + 1, ori_plus] += rco001
histograms[row_bin_floor + 1, col_bin_floor + 2, orientation_bin_floor] += rco010
histograms[row_bin_floor + 1, col_bin_floor + 2, ori_plus] += rco011
histograms[row_bin_floor + 2, col_bin_floor + 1, orientation_bin_floor] += rco100
histograms[row_bin_floor + 2, col_bin_floor + 1, ori_plus] += rco101
histograms[row_bin_floor + 2, col_bin_floor + 2, orientation_bin_floor] += rco110
histograms[row_bin_floor + 2, col_bin_floor + 2, ori_plus] += rco111
最后进行归一化,将大于0.2的元素设置为0.2。为避免累计误差,使用0.2乘平方和开方值,得到反归一化阈值。再次遍历数组,将大于阈值的元素替换为阈值,进行归一化,并将浮点数转化为整型。由于要将数据保存到uint8中,因此需要乘512。
thr = np.linalg.norm(descriptor_vector) * descriptor_max_value
descriptor_vector[descriptor_vector > thr] = thr
# 从float32转化到 unsigned char
descriptor_vector /= max(np.linalg.norm(descriptor_vector), self.float_epsilon)
descriptor_vector = np.round(512 * descriptor_vector)
descriptor_vector[descriptor_vector < 0] = 0
descriptor_vector[descriptor_vector > 255] = 255
descriptors.append(descriptor_vector)
图像融合部分
compute_ratio_V 函数
该函数的作用为计算左图与右图的V分量的比例。将两幅图像从RGB转为HSV,然后拆分出V分量,计算V分量的和,返回二者比例。
def compute_ratio_V(left, right):
right_hsv = cv2.cvtColor(right, cv2.COLOR_BGR2HSV)
right_v = computeV(right_hsv)
left_hsv = cv2.cvtColor(left, cv2.COLOR_BGR2HSV)
left_v = computeV(left_hsv)
bright_k = left_v / right_v
return bright_k
偏移量offset
以左图为基准,将右图进行仿射变换。检测变换后的右图的非零值,并取出最小的非零值所在的列,记为min_index。再算出该图中最大非零值所在的列,记为max(col)。
right_mask_img = cv2.warpPerspective(right, H, (mix_width, mix_height))
zero_test = np.nonzero(right_mask_img)
min_index = zero_test[0][0]
row, col = np.where(right_mask_img[:, :, 0] == 0)
print(max(col))
将offset初始化为600,判断计算出的V分量比例。若两幅图V分量差别不大,则将offset设置为40;否则,计算如果max(col)离左图边界太近或者超出了左图边界,如下图情况所示:

此时需要采用左侧第一个非零值min_index来计算offset,将左图的left_width与min_index的差乘0.15作为0ffset。
如果max(col)距离左图边界较远,说明右侧没有黑边,如下图情况所示:

此时的掩码left_width与max(col)的差的0.2倍。
offset = 600
if 0.95 < bright_k < 1.05:
offset = 40
elif max(col) > (left_width - 400):
zero_test = np.nonzero(right_mask_img)
min_index = zero_test[0][0]
offset = (left_width - min_index) * 0.15
else:
offset = (left_width - max(col)) * 0.2 + 1
offset = int(offset)
print(offset)
掩码mask
将left_width-2*offset到left_width区域的范围作为过渡区域。过渡区域左侧,采用左图的值,将左图掩码设置为1,右图掩码设置为0。过渡区域右侧,采用右图的值,将左侧掩码设置为0,右侧掩码设置为1。在过渡区域处,左侧掩码的值从1到0逐渐变化,右侧掩码的值从0到1逐渐变化,从而使两幅图像的融合比较平滑不突兀。计算出掩码后,将其变为3通道的,并将左图与右图分别与其掩码相乘。
barrier = left_width - offset
mask = np.zeros((mix_height, mix_width))
mask[:, barrier - offset:barrier + offset] = np.tile(np.linspace(1, 0, 2 * offset), (mix_height, 1))
mask[:, :barrier - offset] = 1
left_mask = np.stack((mask, mask, mask), axis=2)
left_mask_img[0:left_height, 0:left_width, :] = left
left_mask_img = left_mask_img * left_mask
mask2[:, barrier - offset:barrier + offset] = np.tile(np.linspace(0, 1, 2 * offset), (mix_height, 1))
mask2[:, barrier + offset:] = 1
right_mask = np.stack((mask2, mask2, mask2), axis=2)
right_mask_img = right_mask_img * right_mask
最后将得到的两幅图像相加,并裁剪掉右侧的黑边即可。
mix_img = left_mask_img + right_mask_img
rows, cols = np.where(mix_img[:, :, 0] != 0)
output_img = mix_img[min(rows):max(rows), min(cols):max(cols), :]
result_path = "./result/output" + img_seq + ".jpg"
cv2.imwrite(result_path, output_img) # 写入文件
实验结果
SIFT算法中间结果
查看SIFT中间过程中得到的DOG图像,可以看出DOG图像中能显示出原图的轮廓特征。在同组的DOG图像中,得到的图像中的轮廓线会随层数增大而变得更加明显;在不同组的DOG图像中,随组数增大,DOG图像的轮廓线变得越来越粗,看到的细节越来越少,可以体现出人在距离目标由近到远时目标在视网膜上的形成过程,从而使SIFT特征具有尺度不变性。
这里使用的原始图像为left1.jpg图像,下面列出的6个图像为不同组不同层的DOG图像:



将图像中探测到的关键点绘制到图像上,用彩色圆圈圈出的即为关键点。部分区域如下图所示:

关键点匹配结果
将得到的左图与右图的SIFT特征点进行匹配,匹配结果存储在middle_res文件夹中。其中,left1与right1图像的匹配结果如下图所示:
 查看其比较明显的山头位置,可以看出这里虽然有错配的部分点,但整体结果还是非常好的。
查看其比较明显的山头位置,可以看出这里虽然有错配的部分点,但整体结果还是非常好的。

图像融合结果
图像融合前需要先根据匹配结果做仿射变换,然后判断其融合方式,选择合适的offset进行融合。
如下图所示,第一对图像的左图与右图的V分量差别不大,因此融合时可以使offset较小,以更多地保留图像信息,并且可以尽可能避免出现重影现象。原图与乘上掩码mask得到的图像如下图所示:

将左侧图像与右侧图像相加,并裁剪掉右侧黑边,得到的最终结果为

由于left_width左侧基本全部采用了左图,并未采用右图与左图融合,因此最终结果的山头处、长城处均未出现重影,过渡区域十分自然。
放大查看图像的细节,两幅图片过渡区域的山脊、下面的一条小山路也都没有出现错位的现象,整体拼接效果较好。下图展示了融合区域的两处细节

实验总结
算法优缺点与适用范围
特征点寻找
本次实验使用的寻找特征点的SIFT算法的优缺点已经在2.1节中介绍过了。我实现的SIFT的算法的主要缺点为计算速度过慢,计算一张图片需要若干小时,要等待很长时间。如果将其中的一些步骤改为并行处理,运算速度可能会大大提升。
图像融合方法
由于没有找到合适的光照处理方法,最终我没有处理光照,只是调整了图像的融合方法,根据带拼接图像的特点判断合适的过渡区域大小。这样做的优点是不处理光照也可以得到比较自然的图像,过渡区域几乎看不出拼接痕迹,整体效果还不错。当两侧图像亮度接近时,过渡区域尽可能小,以避免重合部分过多出现重影。但缺点在于,当两侧图像V分量之和接近,整体光照不同时,该方法并不能很好的判断并给出最优的offset。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









