







一、了解VIT结构
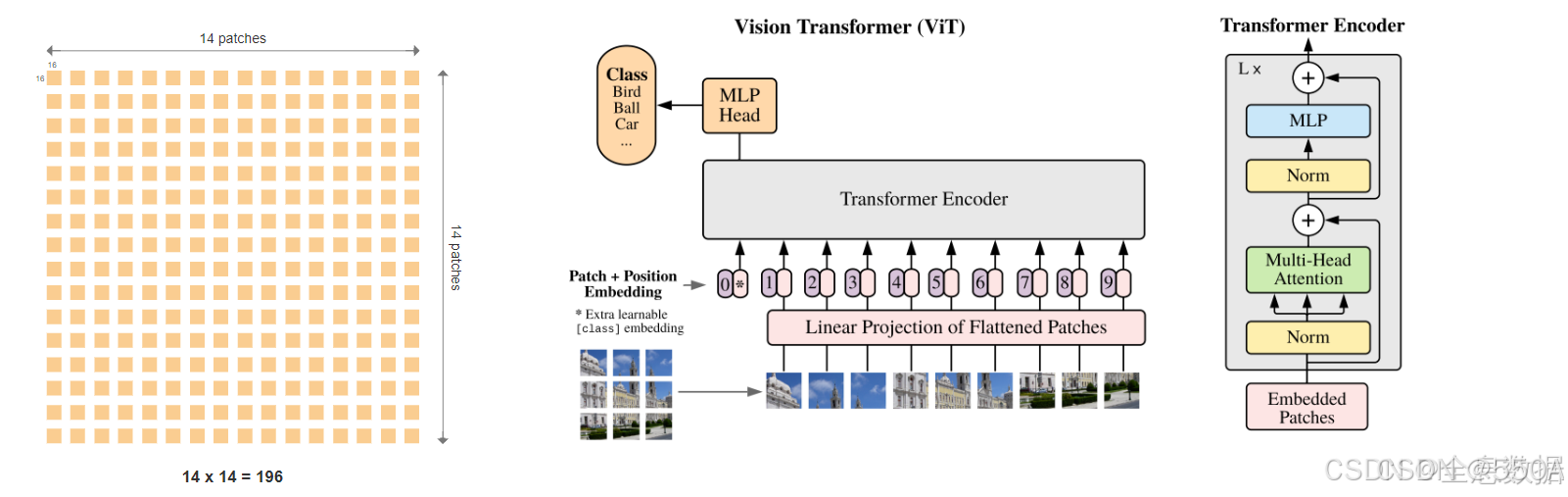
vit提出了对于图片完全采用transformer结构而不是CNN的方法,通过将图片分为patch,再将patch展开输入编码器(grid_size网格大小),最后用MLP将输出转化为对应类预测。
详细信息可以看下面这个分享:
vit提出了对于图片完全采用transformer结构而不是CNN的方法,通过将图片分为patch,再将patch展开输入编码器(grid_size网格大小),最后用MLP将输出转化为对应类预测。
详细信息可以看下面这个分享:
 3938
3938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























