







论文原文地址:https://openreview.net/pdf?id=YicbFdNTTy
代码地址:https://github.com/google-research/vision_transformer
Pytorch版本代码:https://github.com/lucidrains/vit-pytorch
目录
ViT代码复现——以Pytorch-VIT为例(包括部分运行结果)
第五步:使用 Hugging Face 加载 ViT 模型进行图像分类
论文翻译
AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
一张图片胜过16X16个单词:用于大规模图像识别的变换器
摘要
虽然Transformer架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们表明,这种对CNN的依赖是没有必要的,并且直接应用于图像补丁序列的纯Transformer可以在图像分类任务中表现得非常好。当对大量数据进行预训练并传输到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTab等)时,与最先进的卷积网络相比,Vision Transformer(ViT)可以获得出色的结果,同时训练所需的计算资源少得多。
1 介绍
基于自我注意力的架构,特别是Transformers(Vaswani等人,2017),已成为自然语言处理(NLP)的首选模型。主要的方法是在大型文本库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlin et al,2019)。得益于Transformers的计算效率和可扩展性,训练参数超过100 B的前所未有规模的模型已成为可能(Brown et al,2020; Lepikhin et al,2020)。随着模型和数据集的增长,仍然没有表现饱和的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位(LeCun等人,1989; Krizhevsky等人,2012; He等人,2016)。受NLP成功的启发,多部作品尝试将类似CNN的架构与自我注意力结合起来(Wang等人,2018; Carion等人,2020),其中一些完全取代了卷积(Ramachandran等人,2019; Wang等人,2020 a)。后一种模型虽然理论上有效,但由于使用专门的注意力模式,尚未在现代硬件加速器上有效扩展。因此,在大规模图像识别中,经典的ResNet类架构仍然是最先进的(Mahajan等人,2018; Xie等人,2020; Kolesnikov等人,2020)。
受NLP中Transformer扩展成功的启发,我们尝试将标准Transformer直接应用于图像,并且修改尽可能少。为此,我们将图像分割为补丁,并提供这些补丁的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像补丁的处理方式与标记(单词)相同。我们以监督的方式训练模型进行图像分类。
当在没有强正规化的ImageNet等中等规模数据集上进行训练时,这些模型的准确性较同等规模的ResNet低几个百分点。这种看似令人沮丧的结果可能是意料之中的:变形者缺乏CNN固有的一些归纳偏差,例如翻译等方差和局部性,因此在数据量不足时无法很好地概括。
然而,如果模型在更大的数据集(14 M-300 M张图像)上训练,情况就会发生变化。我们发现大规模训练胜过归纳偏见。当以足够大的规模进行预训练并转移到具有更少数据点的任务时,我们的Vision Transformer(ViT)可以获得出色的结果。当在公共ImageNet-21 k数据集或内部JFT-300 M数据集上进行预训练时,ViT在多个图像识别基准上接近或超越了最新水平。特别是,最佳模型在ImageNet上的准确率为88:55%,在ImageNet-ReaL上的准确率为90:72%,在CIFAR-100上的准确率为94:55%,在包含19个任务的VTAB套件上的准确率为77:63%。
2 相关工作
Vaswani等人(2017年)提出了Transformers用于机器翻译,此后已成为许多NLP任务中的最先进方法。基于Transformer的大型模型通常在大型数据库上进行预训练,然后针对手头的任务进行微调:BERT(Devlin等人,2019)使用去噪自我监督预训练任务,而GPT工作线使用语言建模作为其预训练任务(Radford等人,2018; 2019; Brown等人,2020)。
对图像天真地应用自我注意力需要每个像素关注每个其他像素。由于像素数的二次成本,这无法扩展到现实的输入大小。因此,为了在图像处理的环境中应用变形金刚,过去已经尝试过几种近似。Parmar等人(2018)仅在每个查询像素的局部社区中应用自我注意力,而不是在全球范围内应用。这种局部多头点积自我注意块可以完全取代卷积(Hu等人,2019; Ramachandran等人,2019; Zhao等人,2020)。在另一项工作中,Sparse Transformers(Child等人,2019)采用可扩展的全球自我注意力逼近,以便适用于图像。衡量注意力的另一种方法是将其应用于不同大小的块(Weissenborn等人,2019),在极端情况下仅沿着单个轴应用(Ho等人,2019; Wang等人,2020 a)。许多这些专门的注意力架构在计算机视觉任务上展示了有希望的结果,但需要复杂的工程才能在硬件加速器上有效实施。
与我们最相关的是Cordonnier等人(2020)的模型,该模型从输入图像中提取大小为2 x 2的补丁,并在顶部应用完全的自我注意力。该模型与ViT非常相似,但我们的工作进一步证明,大规模预训练使vanilla Transformers能够与最先进的CNN竞争(甚至更好)。此外,Cordonnier等人(2020)使用了2 x 2像素的小补丁大小,这使得该模型仅适用于小分辨率图像,而我们也可以处理中分辨率图像。
人们对将卷积神经网络(CNN)与自我注意形式相结合也很感兴趣,例如通过增强图像分类的特征图(Bello等人,2019)或通过使用自我注意力进一步处理CNN的输出,例如用于对象检测(Hu等人,2018; Carion等人,2020),视频处理(Wang等人,2018; Sun等人,2019),图像分类(Wu等人,2020)、无监督对象发现(Locatello等人,2020)或统一文本视觉任务(Chen等人,2020 c; Lu等人,2019; Li等人,2019)。
最近的另一个相关模型是图像GPT(iGPT)(Chen等人,2020 a),它在降低图像分辨率和色彩空间后将变形金刚应用于图像像素。该模型以无监督的方式作为生成模型进行训练,然后可以对生成的表示进行微调或线性探索以获得分类性能,从而在ImageNet上实现72%的最高准确率。
我们的工作增加了越来越多的论文,这些论文以比标准ImageNet数据集更大的规模探索图像识别。使用额外的数据源可以在标准基准上实现最先进的结果(Mahajan等人,2018; Touvron等人,2019; Xie等人,2020)。此外,Sun等人(2017)研究了CNN性能如何随着数据集大小而变化,Kolesnikov等人(2020); Djolonga等人(2020)对来自ImageNet-21 k和JFT-300 M等大规模数据集的CNN迁移学习进行了实证探索。我们也关注后两个数据集,但训练Transformers,而不是之前作品中使用的基于ResNet的模型。
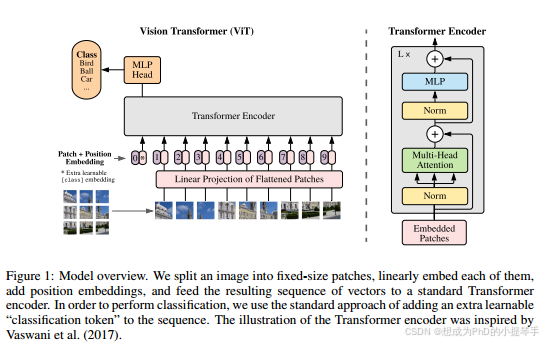
图1:模型概述。我们将图像分割成固定大小的补丁,线性嵌入其中的每个补丁,添加位置嵌入,并将生成的载体序列提供给标准的Transformer编码器。为了执行分类,我们使用标准方法,即向序列添加额外的可学习的“分类标记”。Transformer编码器的插图受到Vaswani等人(2017)的启发。
3 方法
在模型设计中,我们尽可能遵循最初的Transformer(Vaswani等人,2017)。这种故意简单设置的一个优点是,可扩展的NLP Transformer架构及其高效实现几乎可以立即使用。
3.1 VISION TRANSFORMER (ViT)
图1描述了该模型的概述。标准Transformer接收令牌嵌入的1D序列作为输入。为了处理2D图像,我们将图像![]() 重塑为一系列扁平化的2D补丁
重塑为一系列扁平化的2D补丁![]() ,其中(H, W)是原始图像的分辨率,C是通道数量,(P, P)是每个图像补丁的分辨率,
,其中(H, W)是原始图像的分辨率,C是通道数量,(P, P)是每个图像补丁的分辨率,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









