






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
在数据预处理阶段,对文本数据进行清洗和转换是非常重要的步骤,以确保后续的数据分析和模型训练能够顺利进行。
1. 去除HTML标签
使用Beautiful Soup来提取HTML内容中的纯文本
在Python脚本中,导入Beautiful Soup库以及一个解析器,
使用HTML内容和所选的解析器来创建一个Beautiful Soup对象。
使用Beautiful Soup对象的.get_text()方法来提取纯文本内容,去除所有的HTML标签,只留下纯文本内容。.get_text()方法会递归地遍历HTML文档的所有节点,并将它们的文本内容连接起来。
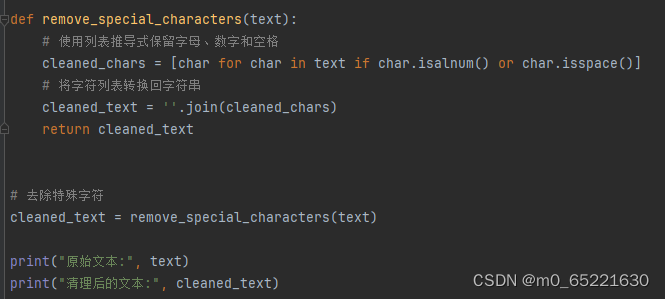
2. 去除特殊字符
特殊字符(如标点符号、非打印字符等)可能会干扰文本分析,因此通常需要在预处理阶段去除或转换为标准字符。想要去除其中的所有非字母数字字符。可以使用列表推导式配合字符串的 isalnum() 方法来实现这个目的。isalnum() 方法会检查一个字符是否是字母或数字,并返回一个布尔值。遍历了字符串 text 中的每个字符 char。对于每个字符,检查它是否是字母、数字或空格。如果是,就将它包含在最终的列表中。然后,使用 join() 方法将列表中的字符连接成一个新的字符串 cleaned_text。cleaned_text 中只包含了原始文本中的字母、数字和空格,而所有的特殊字符都被去除了。
3. 文本转换:将文本转换为统一的编码格式
在文本处理中,确保文本数据的编码格式统一是非常重要的。不同的编码格式可能会导致乱码或数据丢失。UTF-8是目前最常用的编码格式之一,因为它支持广泛的字符集,包括各种语言的字符。
以下用于将指定目录中的所有文本文件转换为UTF-8编码格式。这个脚本会遍历指定目录及其子目录中的所有文件,检查每个文件的编码,并将其转换为UTF-8编码。
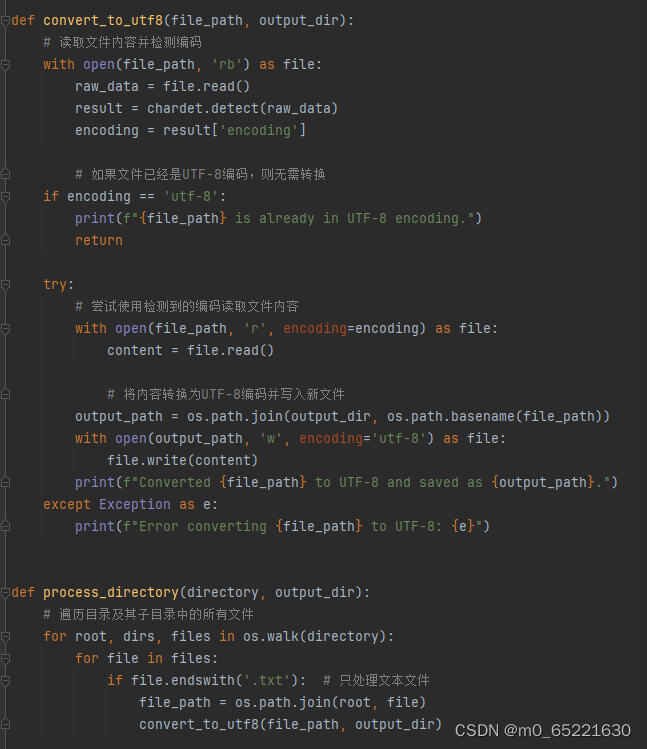
这个脚本首先定义了一个convert_to_utf8函数,该函数负责读取文件、检测其编码、将其转换为UTF-8编码,并将转换后的内容写入新文件。然后,process_directory函数遍历指定目录及其子目录中的所有文本文件,并对每个文件调用convert_to_utf8函数。最后,在__main__部分,设置了要转换的目录和输出目录,并调用process_directory函数来处理这些文件。















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









