




本地部署AI大模型使用Ollama框架:
官方网址:Ollama
点击:Download进行下载
安装一直点击下一步
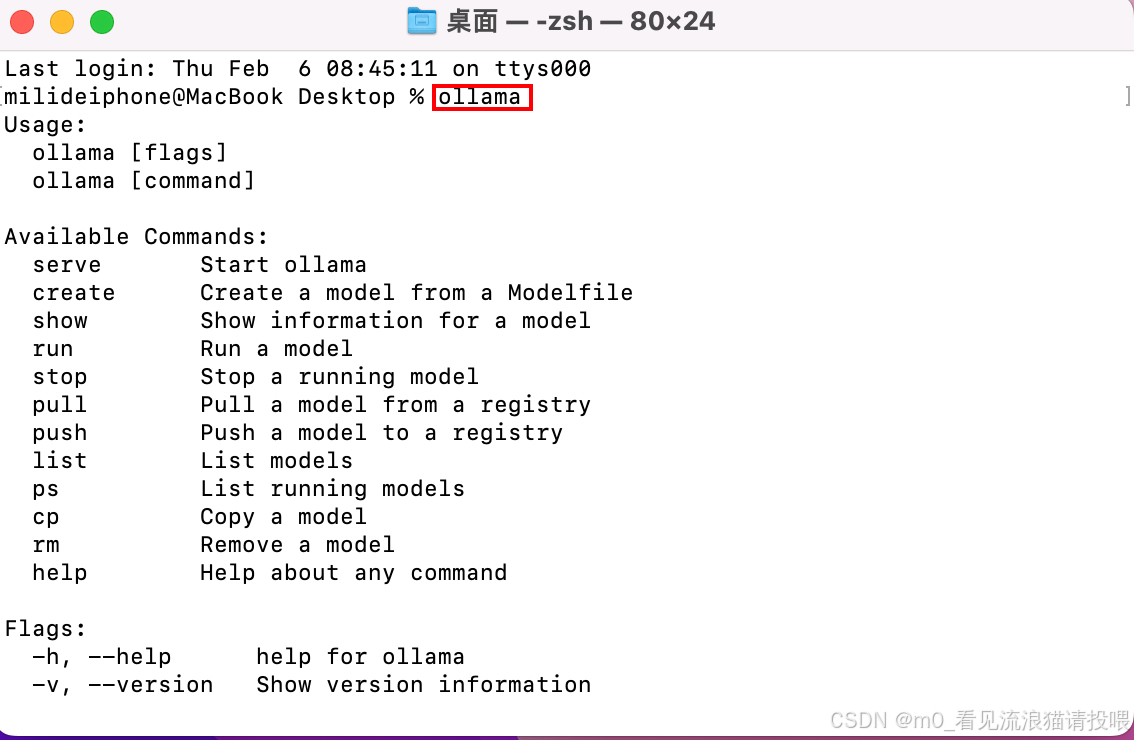
在终端输入ollama命令查看即安装成功
回到Ollama官网
搜索框输入:deepseek-r1
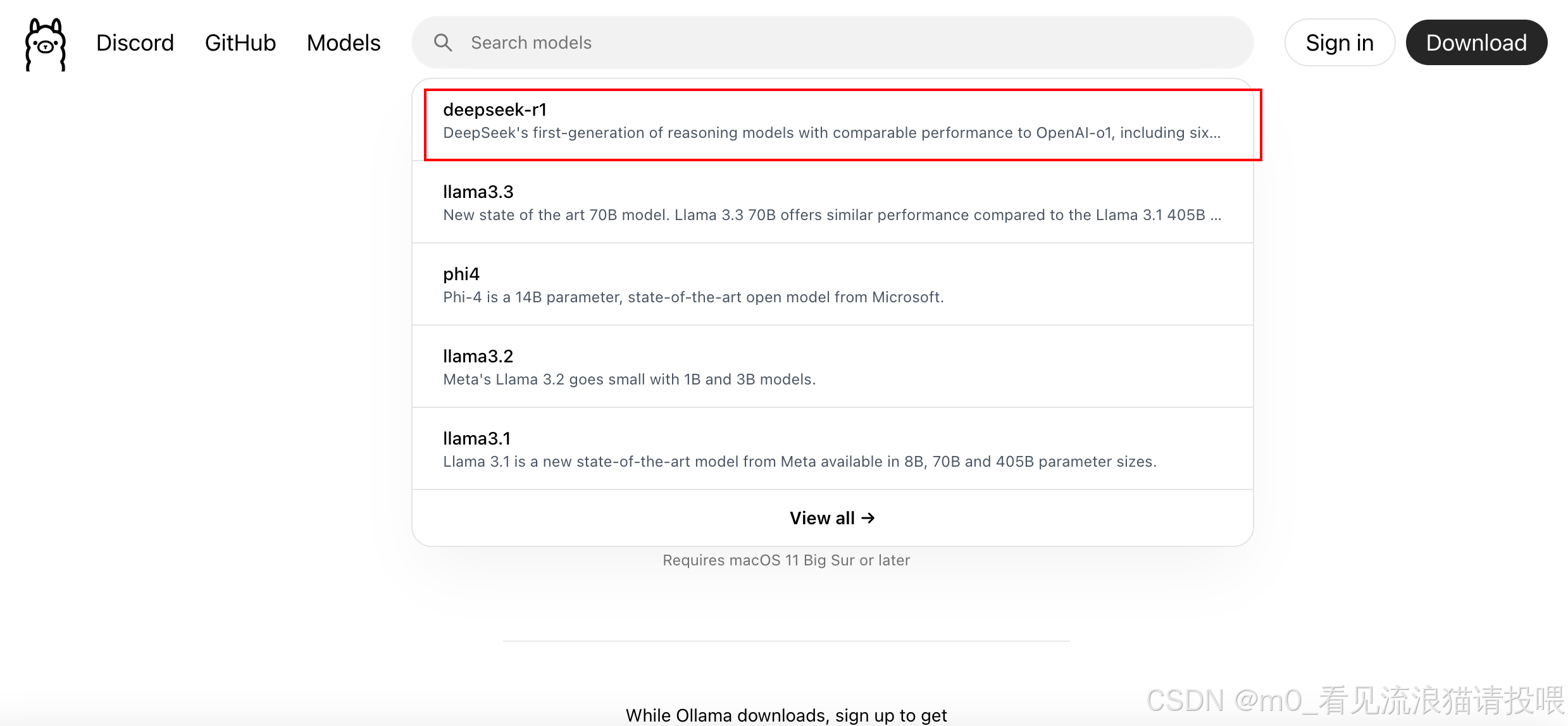
根据电脑配置选择相对应的AI大模型
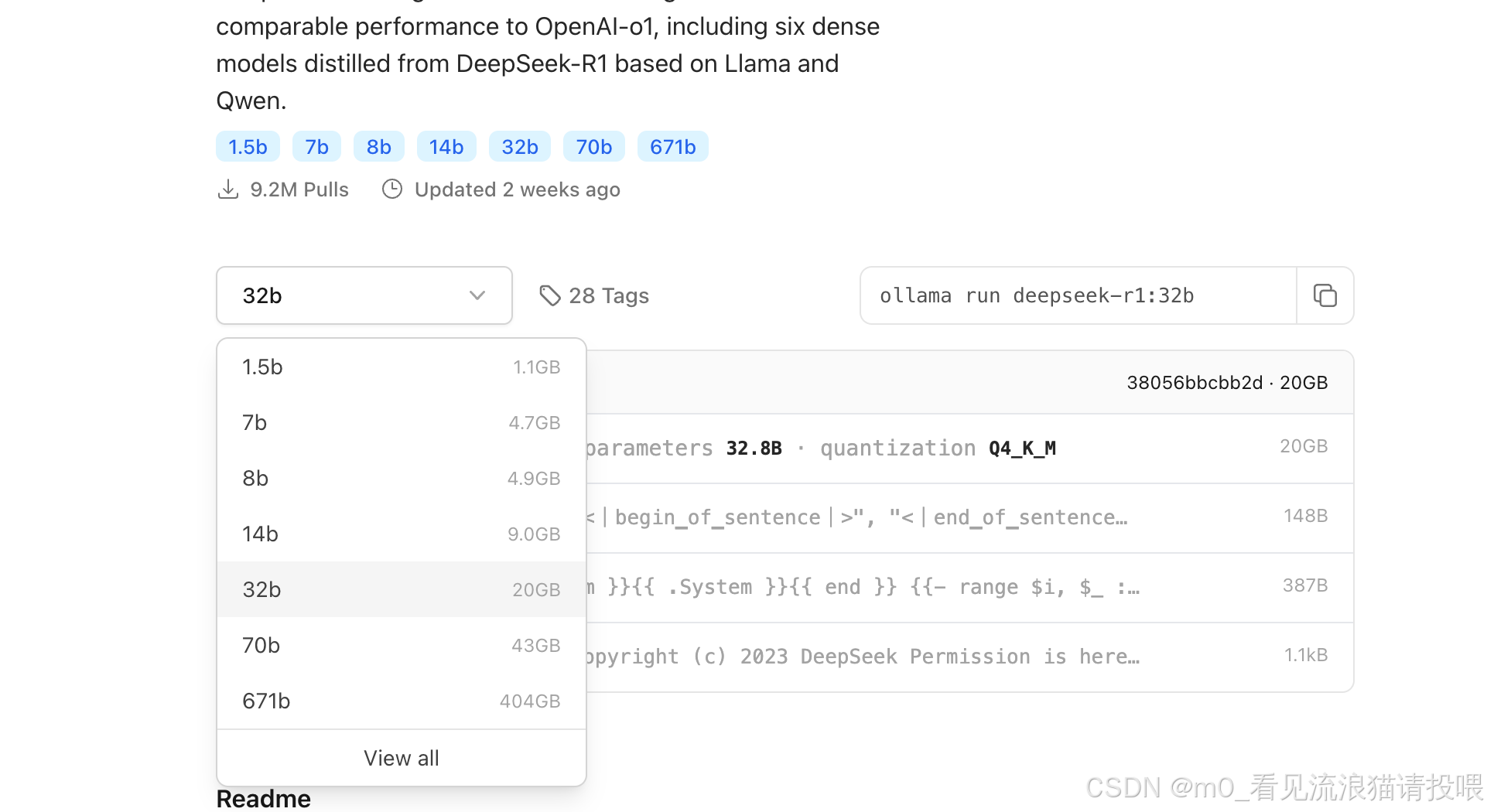
这里我拉取的是7b的大模型
在终端输入:ollama run deepseek-r1:7b
如果下载中断可以用:

下载成功后:
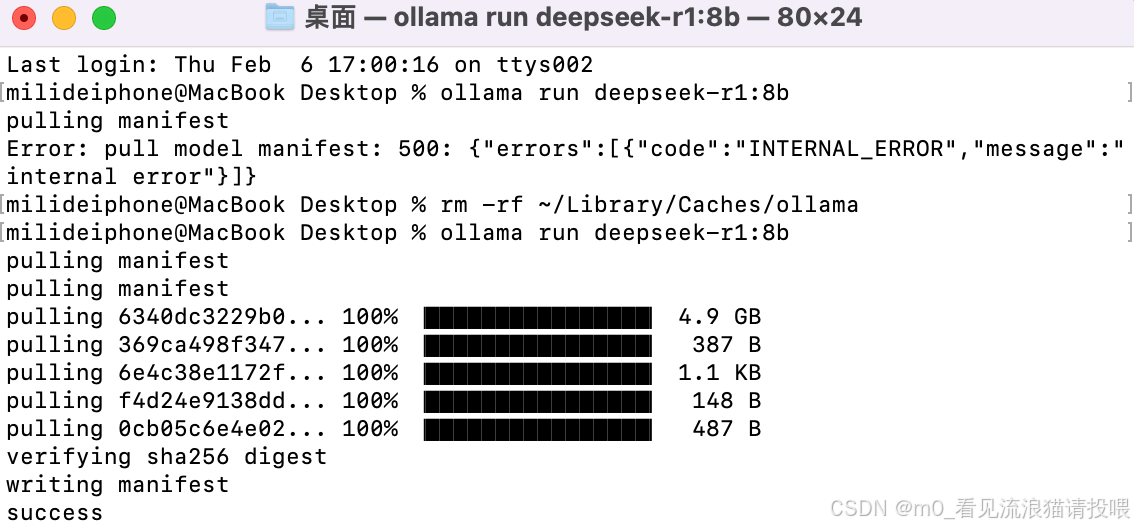
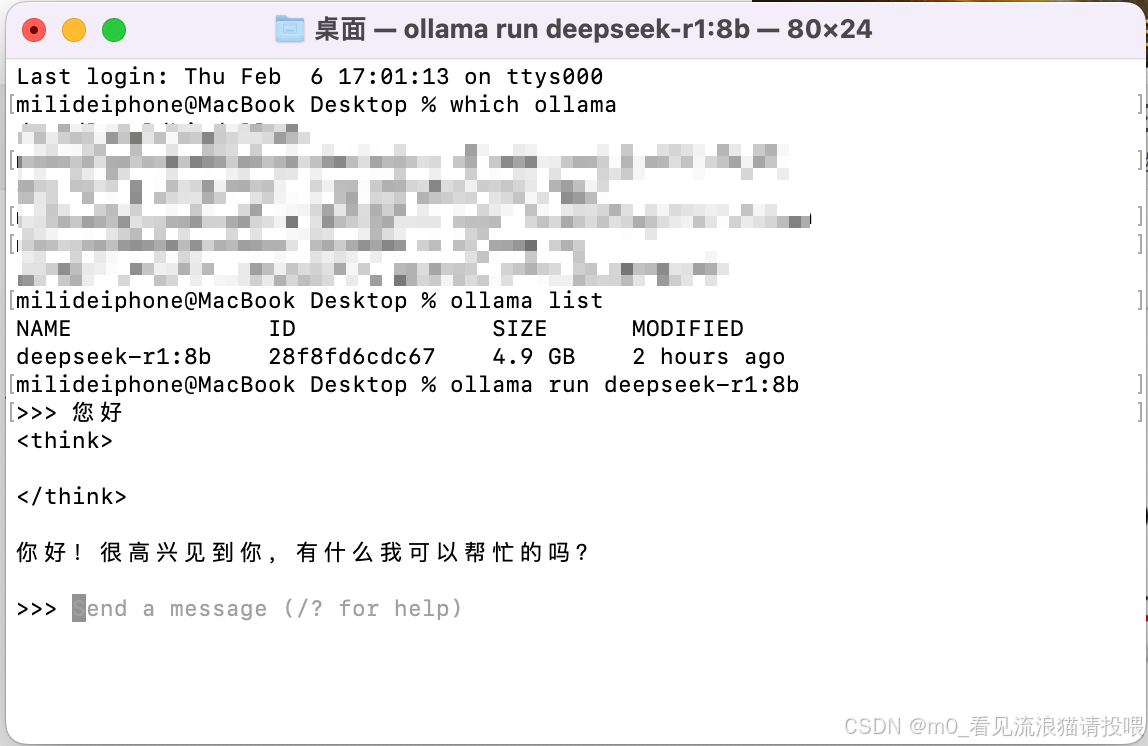
下载完成之后,使用ollama list查看拉取到模型

再输入指令:ollama run 模型名 启动大模型

最后:可以使用AI啦
运行在浏览器上面:
可以使用Google Chrome浏览器的
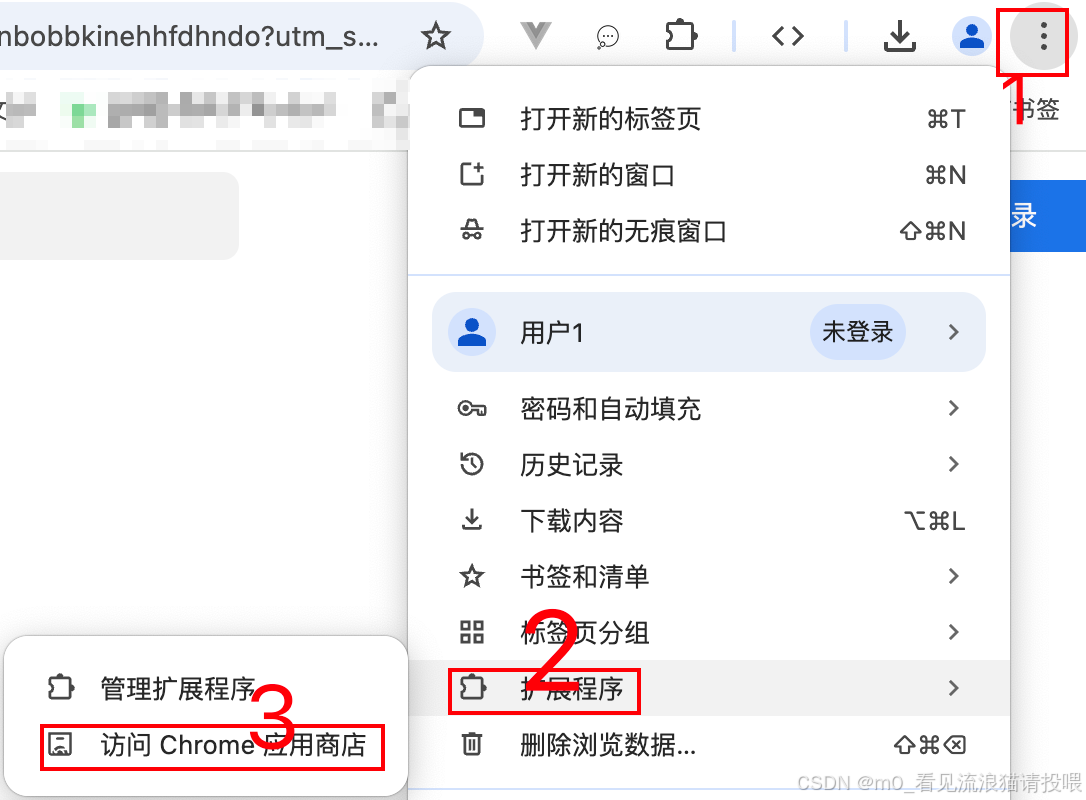
搜索Page Assist
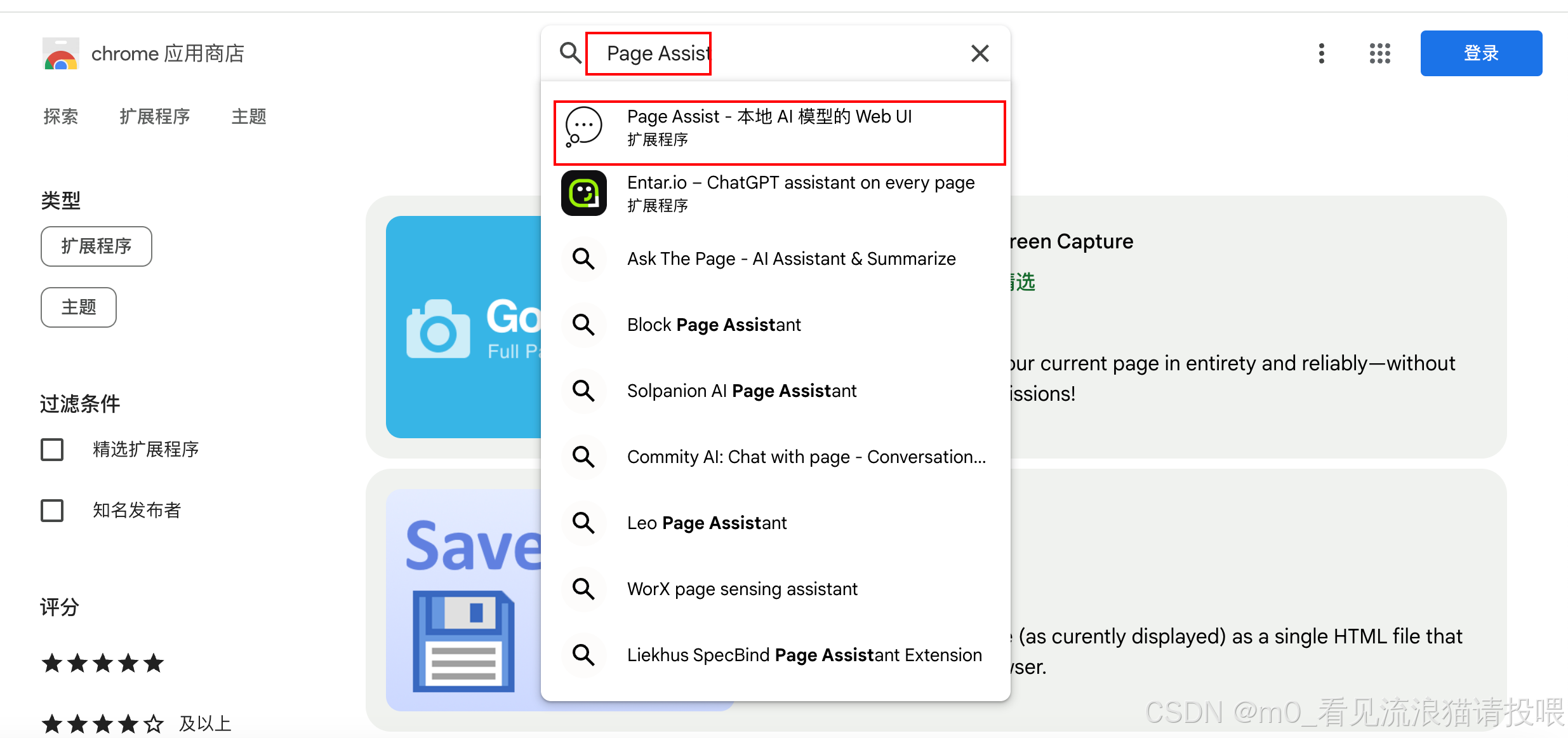
下载
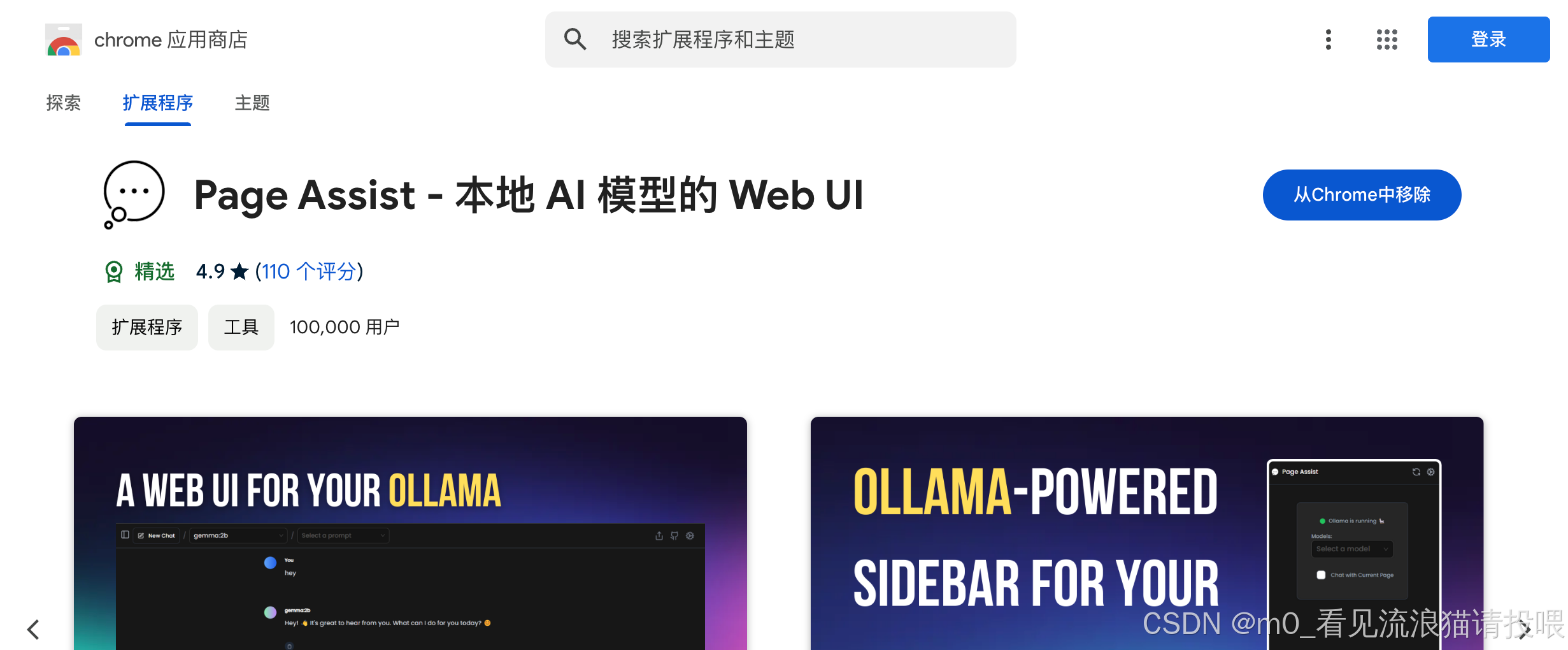
下载完成后程序拓展坞打开:
在浏览器使用命令:Ctrl+Shift+L 打开
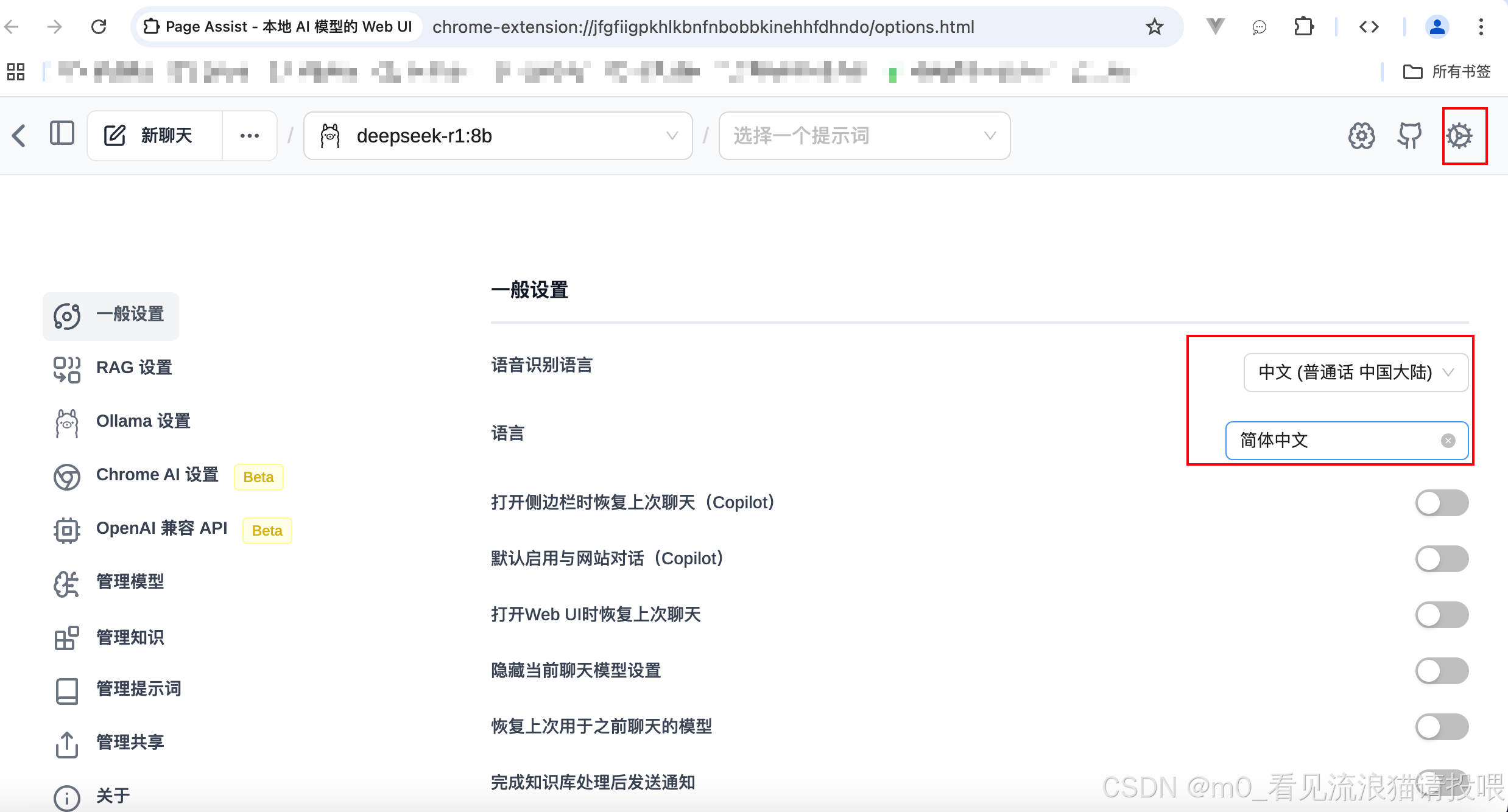
在设置中选择我们下载的模型:
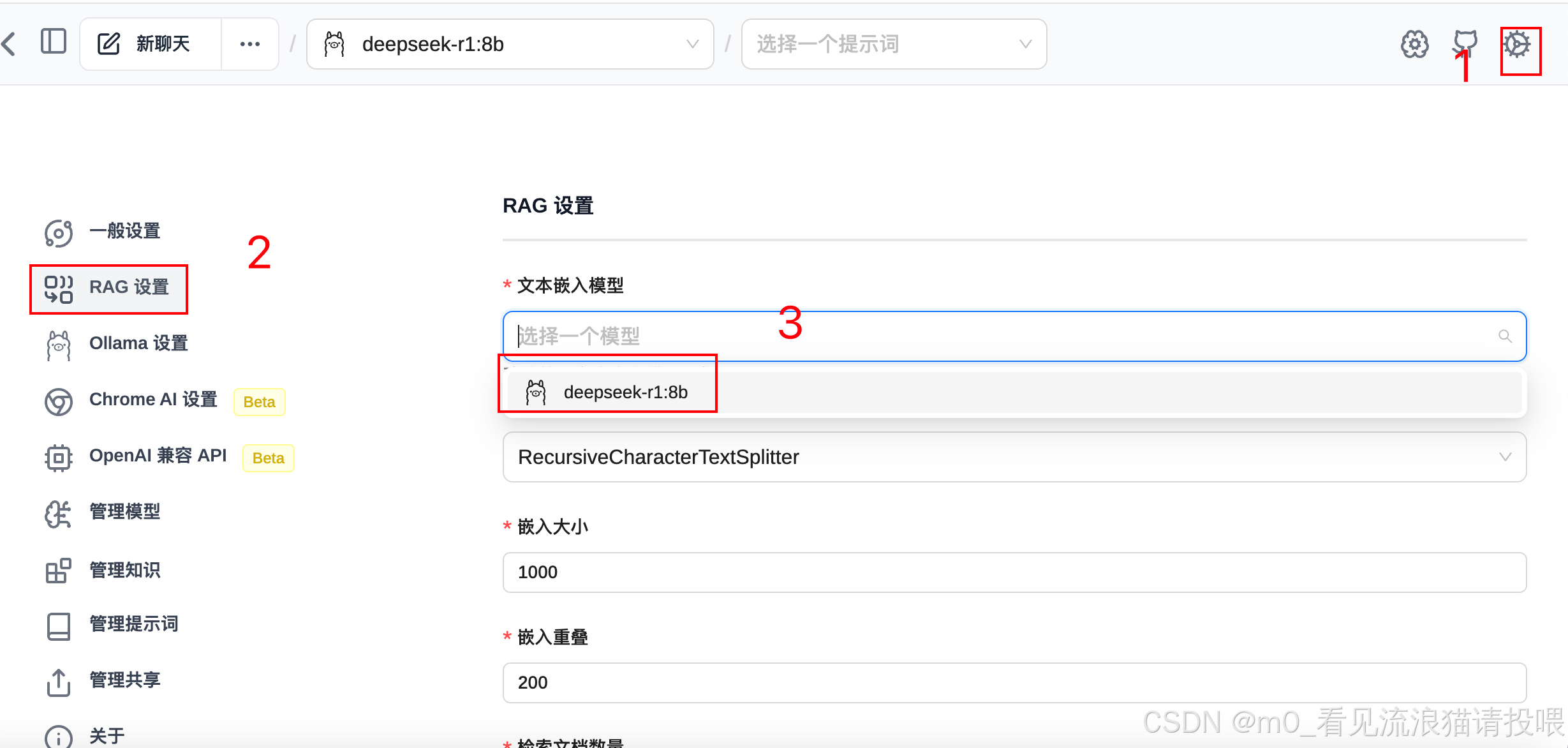
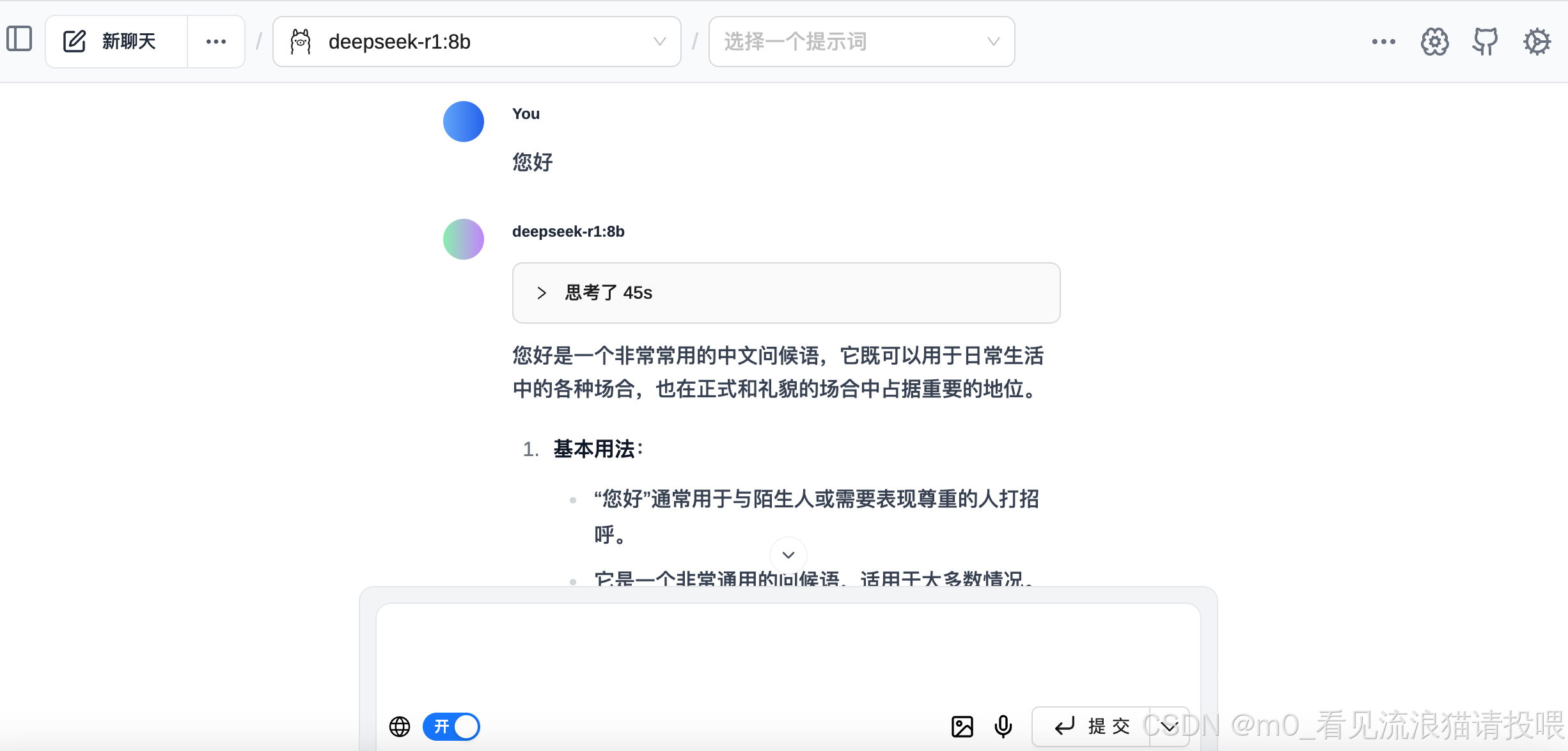
最后可以使用DeepSeek啦

















 3万+
3万+



 到【灌水乐园】发言
到【灌水乐园】发言








