







目录
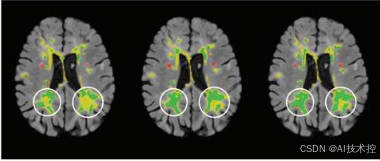
医学图像是现代医学诊断的重要工具,广泛应用于疾病检测、治疗规划和手术辅助。然而,在实际应用中,医学图像常因噪声、伪影、数据丢失等问题导致质量下降,影响诊断的准确性和医疗决策的可靠性。如何高效且精准地修复医学图像,成为了一个重要的研究课题。
1. 医学图像修复的挑战
医学图像修复的目标是从受损或低质量的医学图像中恢复出高质量的原始图像。然而,医学图像修复面临以下挑战:
- 噪声干扰:例如,低剂量CT图像中常见的高噪声会影响影像细节。
- 伪影问题:MRI图像中的运动伪影或金属植入物引起的伪影会导致图像失真。
- 数据缺失:部分医学图像可能因遮挡、扫描不完整或设备故障而缺失部分区域。
- 高分辨率需求:医学图像需要高分辨率以呈现微小病变,为诊断提供可靠依据。
传统方法(如插值方法、基于滤波的去噪算法)在应对这些挑战时效果有限,而基于深度学习的扩散模型为医学图像修复提供了新的可能。
医学图像修复是医学图像处理中的重要任务,旨在从噪声、伪影或缺失区域中恢复高质量的图像。近年来,生成式模型(Generative Models)在这一领域取得了显著进展,变分自编码器(Variational Autoencoders, VAEs)、对抗生成网络(Generative Adversarial Networks, GANs)和扩散模型(Diffusion Models)是其中的三大代表。每种模型都有其独特的原理和优势,在医学图像修复中展现出不同的应用潜力。
本文将深入探讨这三种生成模型的原理,分析它们在医学图像修复中的表现,并对比它们的优劣势,帮助读者更好地理解扩散模型的独特价值。
2. 三种生成模型的原理
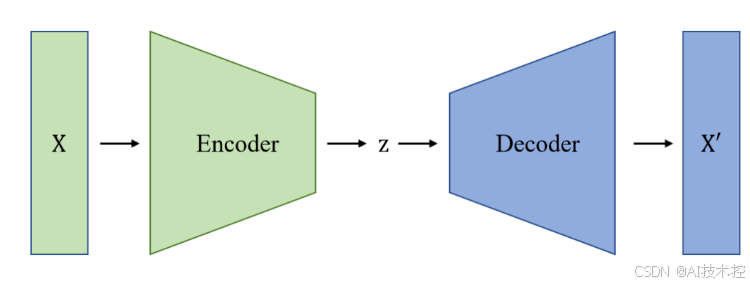
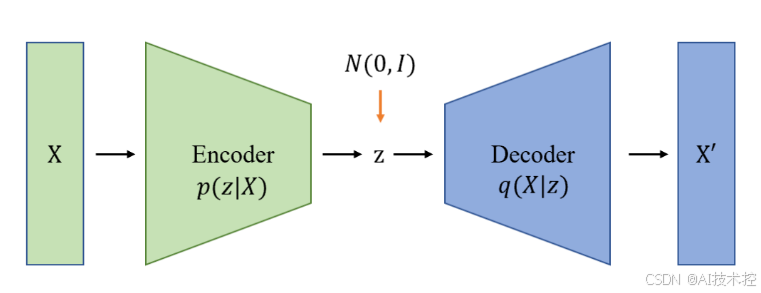
1. 变分自编码器(VAE)
VAE是一种基于概率建模的生成模型,通过编码器和解码器的结构学习数据的隐变量分布,从而生成新样本。
核心原理
- 编码器(Encoder):将输入数据 x 映射到一个潜在表示 z,并假设 z 服从一个简单的分布(如高斯分布)。
- 解码器(Decoder):从潜在变量 z 生成数据 x′,使生成数据尽可能接近原始数据。
- 目标函数:通过最大化证据下界(Evidence Lower Bound, ELBO),同时优化生成数据的重构误差和潜在分布的正则化项:
其中:
- 第一项是重构误差(数据生成的准确性)。
- 第二项是KL散度(约束潜在分布接近先验分布)。
优点
- 生成样本多样性高,能够捕捉数据分布的全局特征。
- 训练稳定,目标函数明确。
缺点
- 生成样本质量通常较低,可能出现模糊的生成图像。
- 难以生成高分辨率的复杂结构。
2. 对抗生成网络(GAN)
GAN是一种基于博弈论的生成模型,通过生成器和判别器的对抗训练,生成高质量的样本。
核心原理
- 生成器(Generator):从随机噪声 z生成数据 x′。
- 判别器(Discriminator):区分生成数据 x′ 和真实数据 x。
- 目标函数:通过对抗训练,使生成器和判别器相互竞争:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2295
2295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











