






AI算力是支撑人工智能发展的关键资源,对于推动技术进步和应用场景的扩展具有重要作用。近年来,中国各省市在AI算力方面投入大量资源,以提升国内人工智能领域的竞争力
随着AI的不断发展,学术界对此的研究不断深入,以“AI”为主题的文章逐年增长,本次分享的数据是中国各省、城市AI算力数据。
一、中国各省市AI算力数据简介
数据根据中国海关数据库显卡HS编码筛选统计
数据时间:2000-2024年,因中国海关数据库未发布2015至2016年的数据,因此该年份数据存在缺失
数据范围:中国各省、城市
数据格式:Excel
原始来源:中国海关数据库
二、数据指标
| 年份 | 省份 | 城市 |
| 进口数量 | 进口金额 | 进口数量对数 |
| 进口金额对数 |
三、数据概览
中国各省AI算力数据概览(2000-2024年)
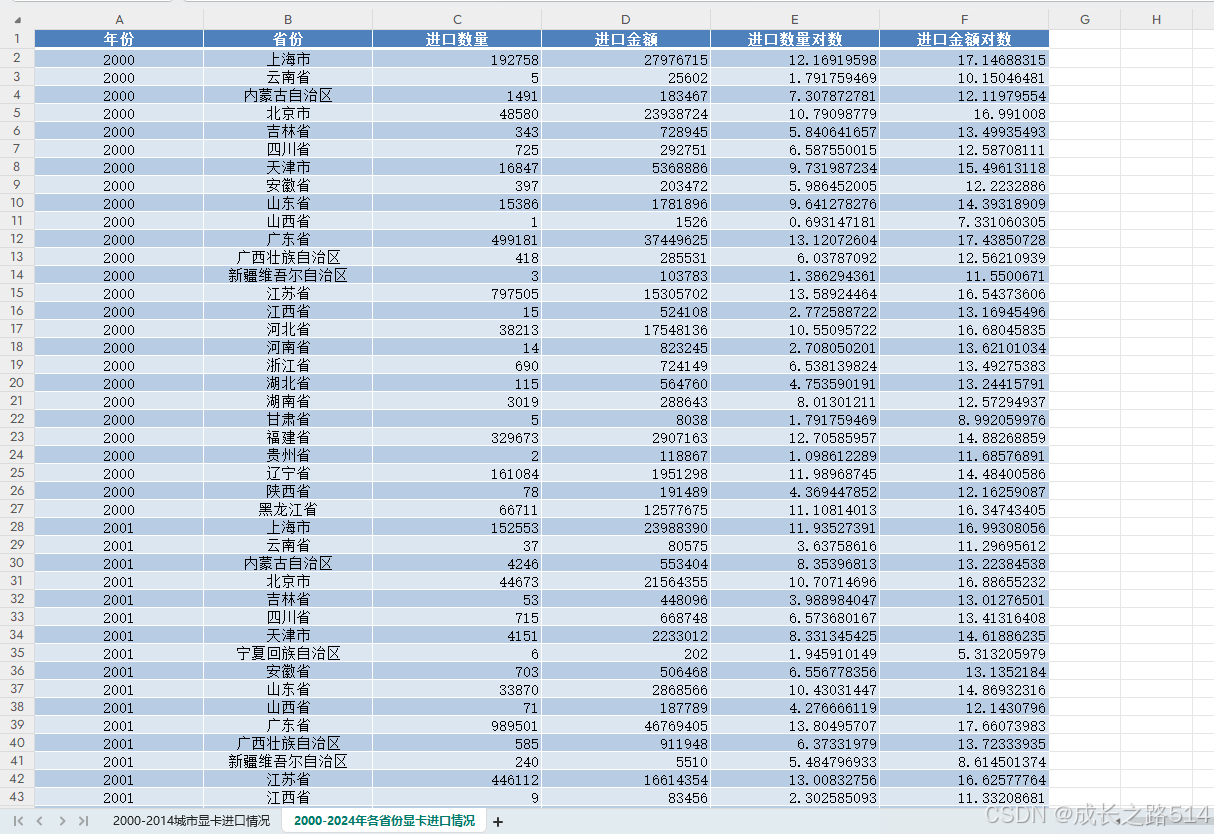
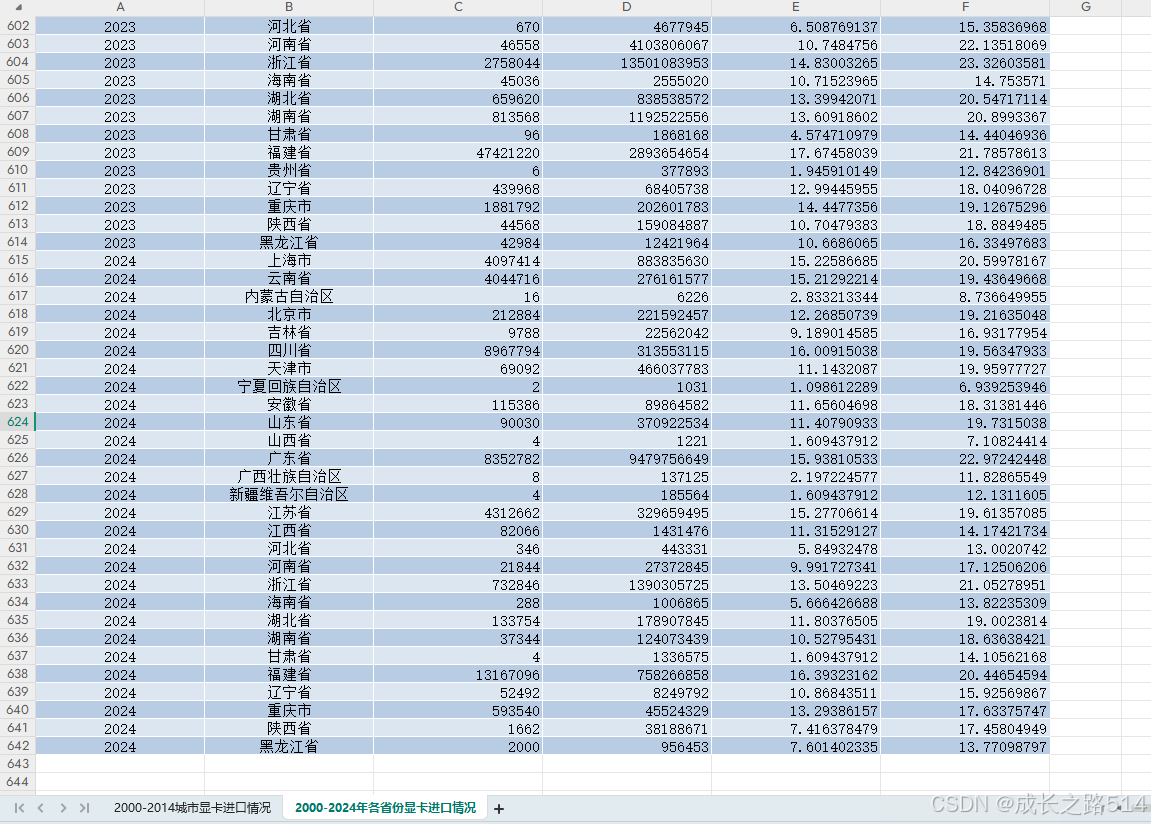
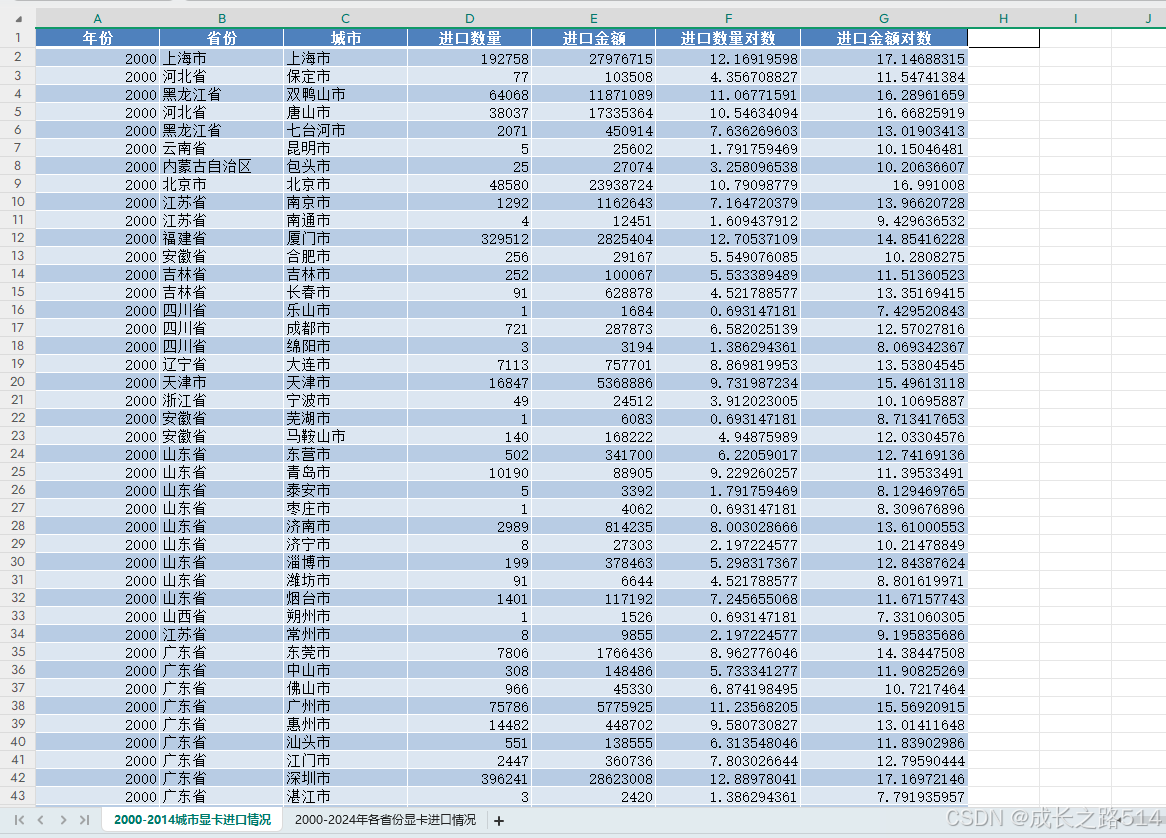
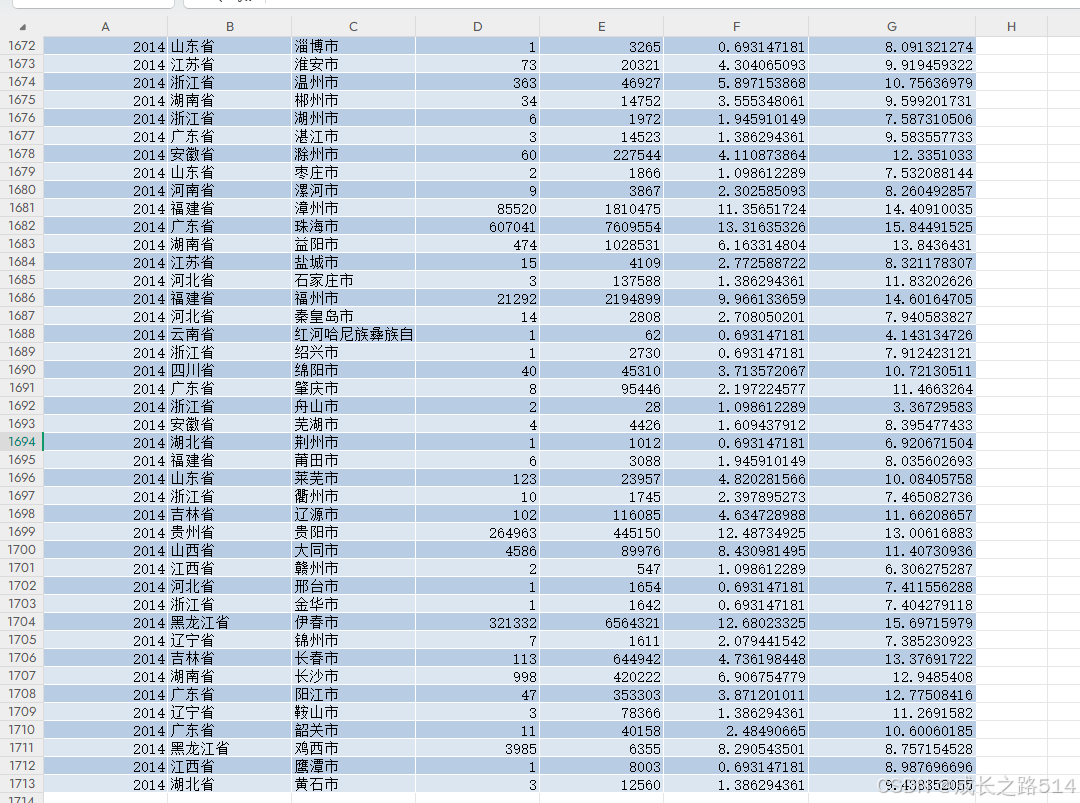
中国各城市AI算力数据概览(2000-2014年)
四、下载链接:https://download.csdn.net/download/m0_65541699/90287214


















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











