









目录
一.自优化?自判别?从神经网络到CEST-MRI
神经网络处理回归问题的原理是基于训练样本的输入与输出之间的关系,通过调整神经网络的参数来使得神经网络对新的输入数据做出预测,并且使得神经网络输出的预测结果尽可能地准确。
具体来说,回归问题中的目标是预测一个连续值。神经网络可以通过学习输入与输出之间的非线性映射关系,捕获输入和输出之间的复杂关系,并用该关系来为新数据提供预测输出。
在神经网络中,回归问题通常使用具有一个或多个连续输出的输出层,并使用一个适当的损失函数(例如均方误差)来评估预测输出与真实输出之间的误差。为了减少损失函数,神经网络将在训练期间不断调整权重和偏差,并优化模型以最大程度地准确预测输入数据的输出值。
应用神经网络算法,CEST-MRI成像中的扫描参数(即若干次扫描中不同饱和脉冲强度𝐵_1、偏频∆ω的组合)作为神经网络参数进行自动优化,同时将目标物质与CEST效应有关的参数(即比例浓度𝑓_b、交换速率𝑘_b、横向弛豫速率𝑅_2b)和可以表征预设物质组分模型是否符合实际情形的参数(数值拟合的残差均方根值RMSE)作为神经网络输出一并获得。
同时实现扫描参数自动优化、目标物质参数准确计算及物质组分模型可靠性自动判别
二.模拟数据集的构建
拟尝试不同策略的多组(∆ω,𝐵_1)的组合作为神经网络的初始值分别进行训练优化。例如:
①固定𝐵_1=0.6 μT,∆ω在1.4 ppm到4.0 ppm之间以0.2 ppm步进;及固定∆ω=1.7, 1.9, 2.1, 2.3, 2.5, 2.7, 2.9 ppm,𝐵_1在0.3 μT至1.5 μT之间以0.3 μT步进。
②∆ω在1.4 ppm到2.9 ppm之间以0.2 ppm步进,𝐵_1在0.3 μT至1.5 μT之间以0.2 μT步进。
③仿照压缩感知方法在∆ω=1.5~2.9 ppm、𝐵_1=0.3~1.5 μT的范围内进行较无规律的20个点的采样;及固定𝐵_1=0.6 μT,∆ω在1.0 ppm到2.0 ppm之间、3.0 ppm到5.0 ppm之间以0.2 ppm步进。其余固定的采样参数为:饱和脉冲时长为1.5 s,采样重复时间TR为2.0 s。
在模拟采样中,利用𝑅_1𝜌弛豫模型计算出一组𝑅_1𝜌值和相应的一组Z值,并基于实际成像信噪比叠加上标准差在0.002-0.006之间随机取值的高斯白噪声,构成一个数据组。每组用于训练神经网络模型的模拟数据集包含约10万个独立的数据组。
三.神经网络的构建与训练
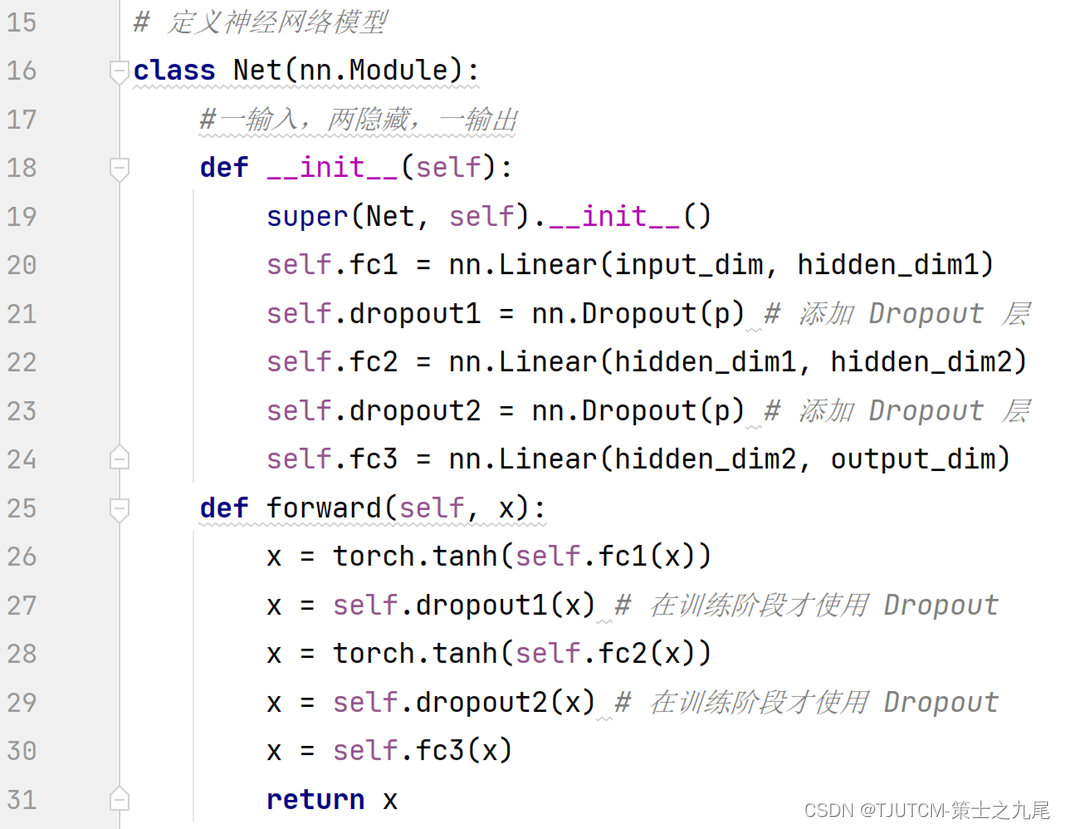
待训练的神经网络是具有一个输入层、一个输出层、多个隐藏层(约10-20个)的前馈神经网络。
神经网络总体架构类似于Perlman等人研究中使用的AutoCEST神经网络架构。
神经网络的前一部分是对CEST数据(Z值)的采集进行模拟。该部分的输入层包括随机生成的各项参数如水的弛豫时间、各种溶质的含量交换速率和弛豫时间、主磁场偏移、叠加在Z值上的随机噪声值等;该部分的节点间传递函数为基于𝑅_1𝜌弛豫模型的计算图,其中可进行优化的节点值为每次采集CEST信号所使用的饱和脉冲偏频值∆ω和强度值𝐵_1;该部分的输出层为模拟采集到的一组Z值。
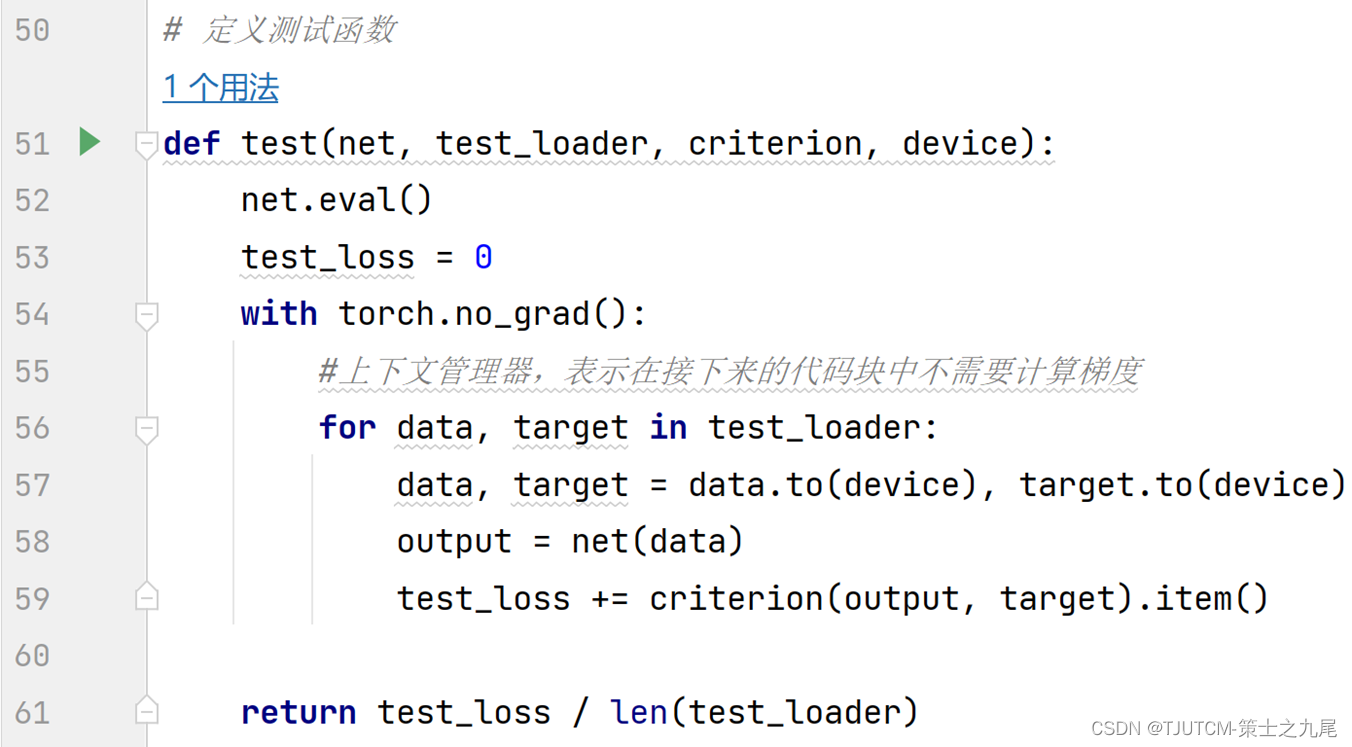
后一部分是基于Z值进行目标溶质CEST参数和RMSE值的计算。该部分的输入层即是前一部分的输出层,该部分的隐藏层包含多层节点,节点之间的传递函数为S型(Matlab中为tansig,pytorch中为tanh)函数。该部分的输出层即为已生成出的目标溶质CEST参数值,和基于gQUCESOP方法模拟计算得到的此种物质背景下的RMSE值。运用误差逆传播法对网络中各节点的权重值进行训练。
四.AutoCEST神经网络框架
整个AutoCEST分为三个子模块。
第一个模块为CEST饱和块(CEST saturation block)。它使用Bloch-McConnell方程的解析解来模拟CEST饱和过程,可以计算出饱和后的水池Mz分量,以及其他溶质的质子交换参数。
第二个模块为自旋动力学模块(Spin dynamics module)。在这个过程中,可以更新翻转角度(FA)和恢复时间(Trec)参数,并计算预期的“ADC”信号。
第三个模块为深度重建网络(Deep reconstruction network)。使用了两个隐藏层,每个隐藏层有300个节点,并且使用tanh激活函数进行激活。
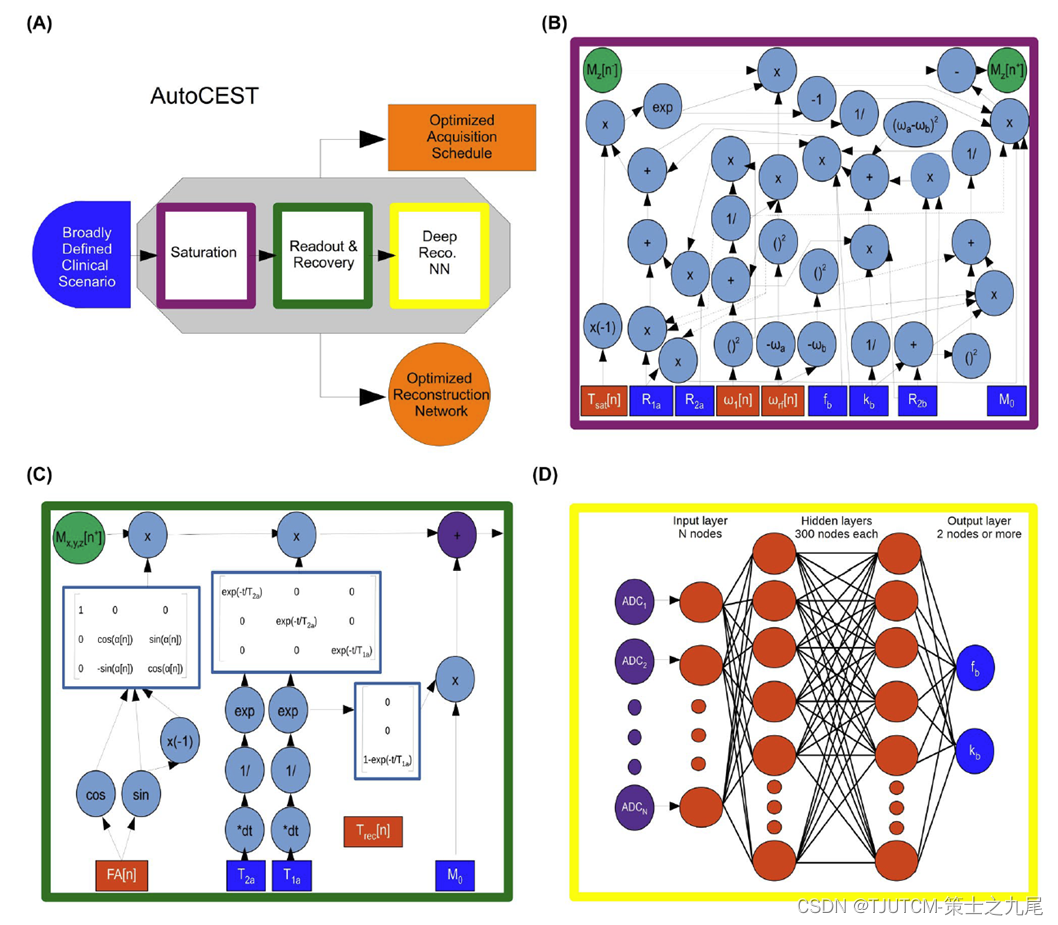
1.CEST饱和块(CEST saturation block)
上图为本模块传递函数使用的BM方程计算图。
下面的蓝色方块表输入:初始磁化强度(M0)、水的弛豫速率(R1a、R2a)、溶质横向弛豫速率(R2b)、交换速率(kb)和比例浓度(fb)。
橙色方块表那些需要随着训练动态更新的参数:饱和时间(Tsat)、饱和频率(ω1)、饱和频率偏移(ωrf)。
本模块最终计算出饱和后的水池Mz分量,以及其他溶质的质子交换参数。这些参数可以用于定量CEST/MT质子交换参数图的重建,从而提高CEST-MRI的灵敏度和特异性。
插曲:怎么将计算图作为传递函数嵌入神经网络中呢?
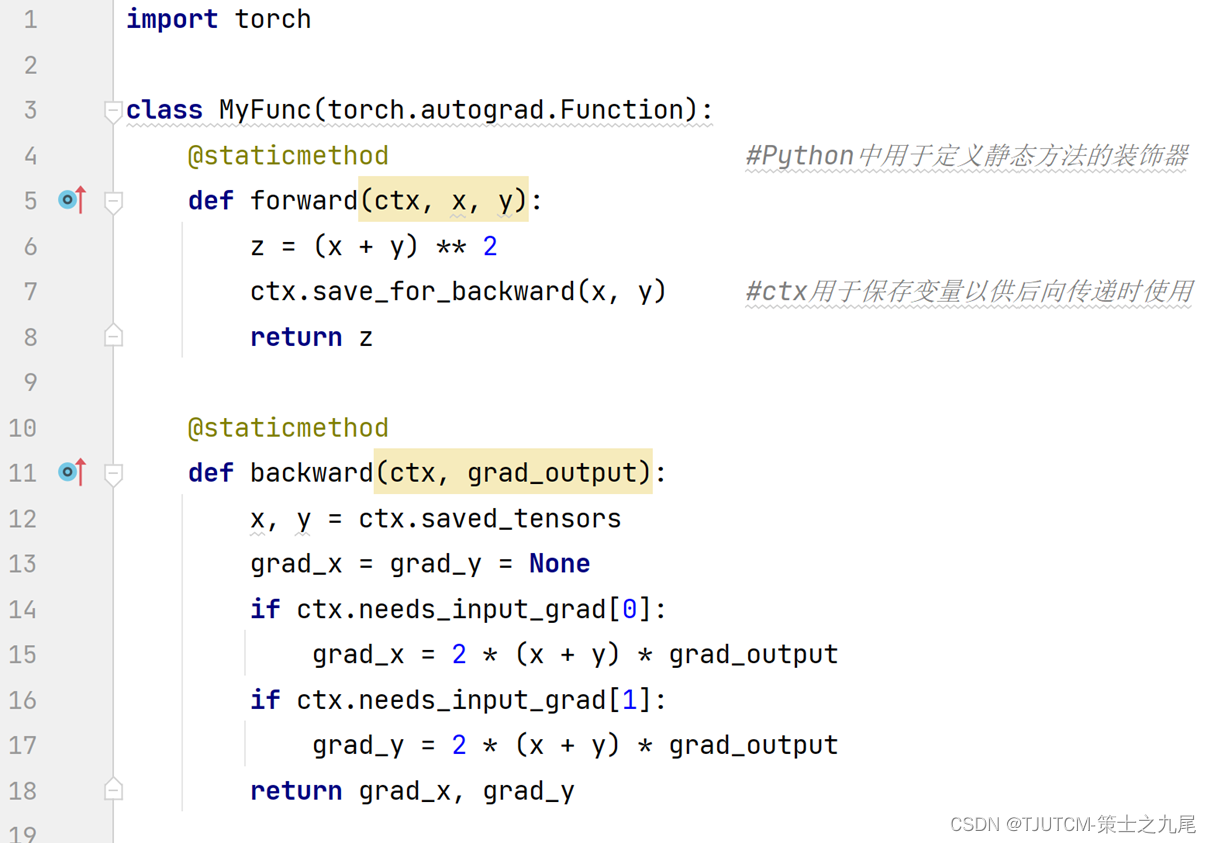
首先,需要定义一个继承自torch.autograd.Function的类,并实现其中的forward和backward方法。
在forward方法中定义计算图的计算过程;而在backward方法中实现计算图的反向传播方法(链式求导)。
最后,在定义神经网络时,可以使用自定义的计算图函数作为层的参数,并将其用作传递函数。
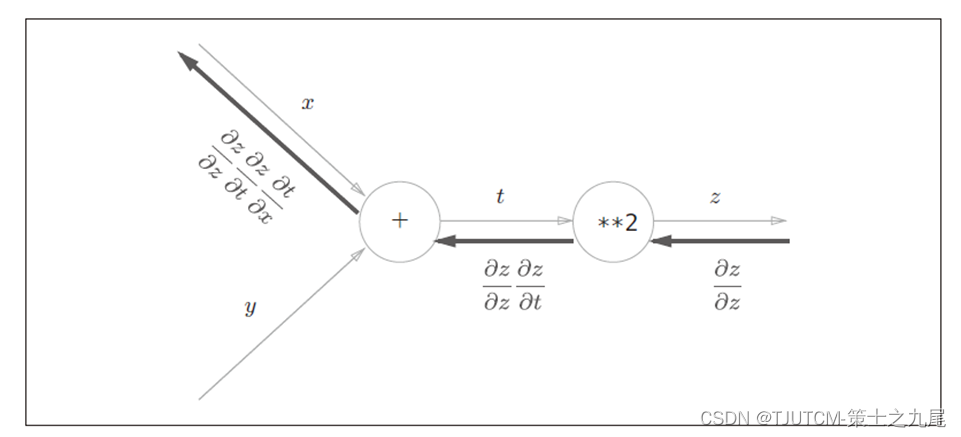
下面以简单的计算图z=(x+y)^2为例,代码如下图所示。

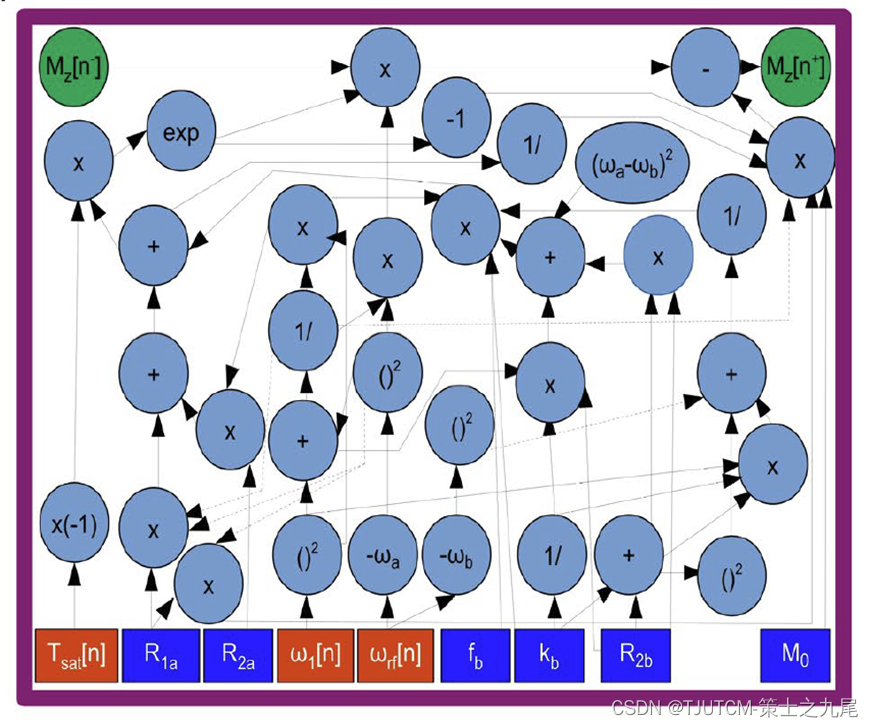
2.自旋动力学模块(Spin dynamics module)
Spin dynamics:指原子核在外部磁场和RF脉冲作用下的演化过程,包括自旋翻转、自旋弛豫等过程。
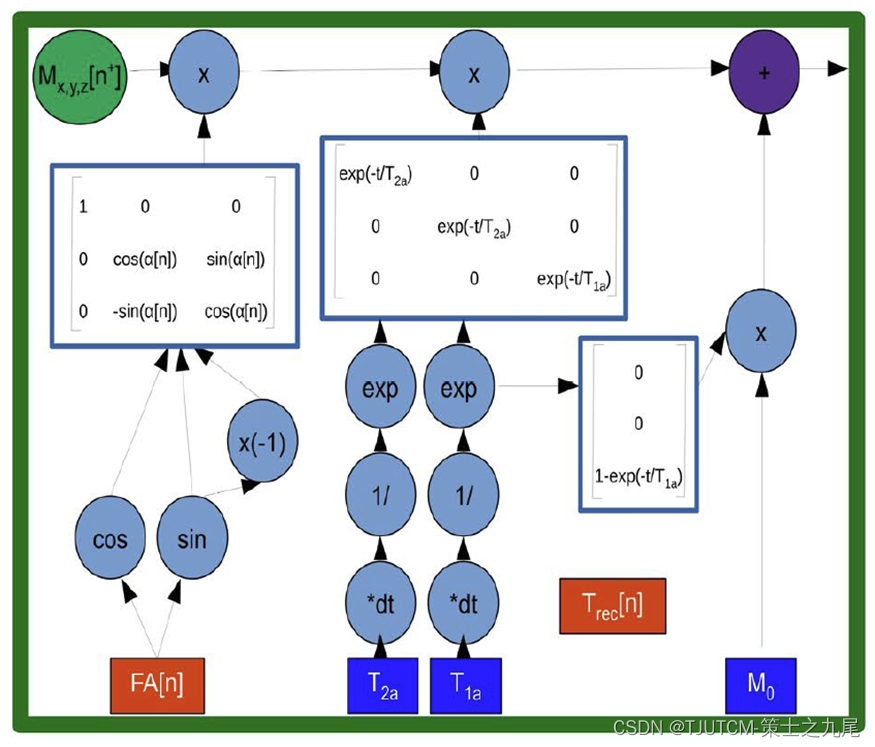
左图为本模块传递函数使用的Bloch方程计算图。
下面的蓝色方块表示输入的水池参数:初始磁化强度(M0)、水的弛豫时间(T1a、T2a)。
橙色方块表示需要随训练动态更新的参数:翻转角度(FA,即磁场中的磁矢量在翻转后与初始方向之间的夹角)和恢复时间(Trec ,即磁共振成像中的两次脉冲之间的时间间隔)。
本模块最终计算出“ADC”信号(自由扩散系数,apparent diffusion coefficient),是一种反映组织水分子自由扩散能力的参数,在第三个模块中被转换为CEST定量参数。这个地位类似于我们的Z值。
3.深度重建网络(Deep reconstruction network)
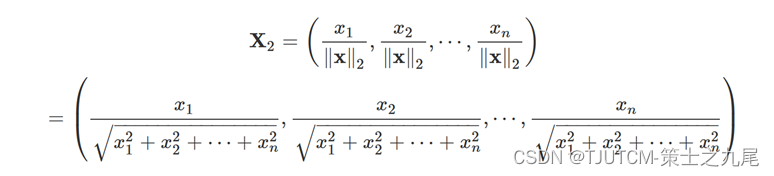
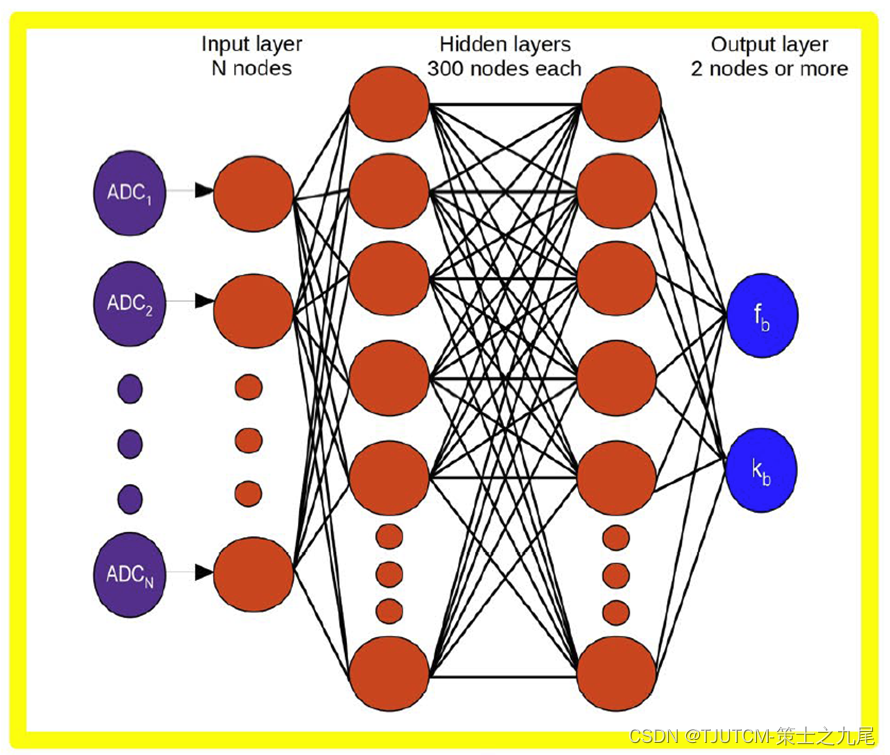
上图为前馈神经网络的示意图。
输入为一组在时间维度上进行二范数归一化的ADC值(为了消除不同时间点的信号强度差异,使得不同时间点的信号可以进行比较和分析),使用了两个(或更多)隐藏层,每个隐藏层有300个节点,并且使用tanh激活函数进行激活。输出即为交换速率(kb)和比例浓度(fb)。
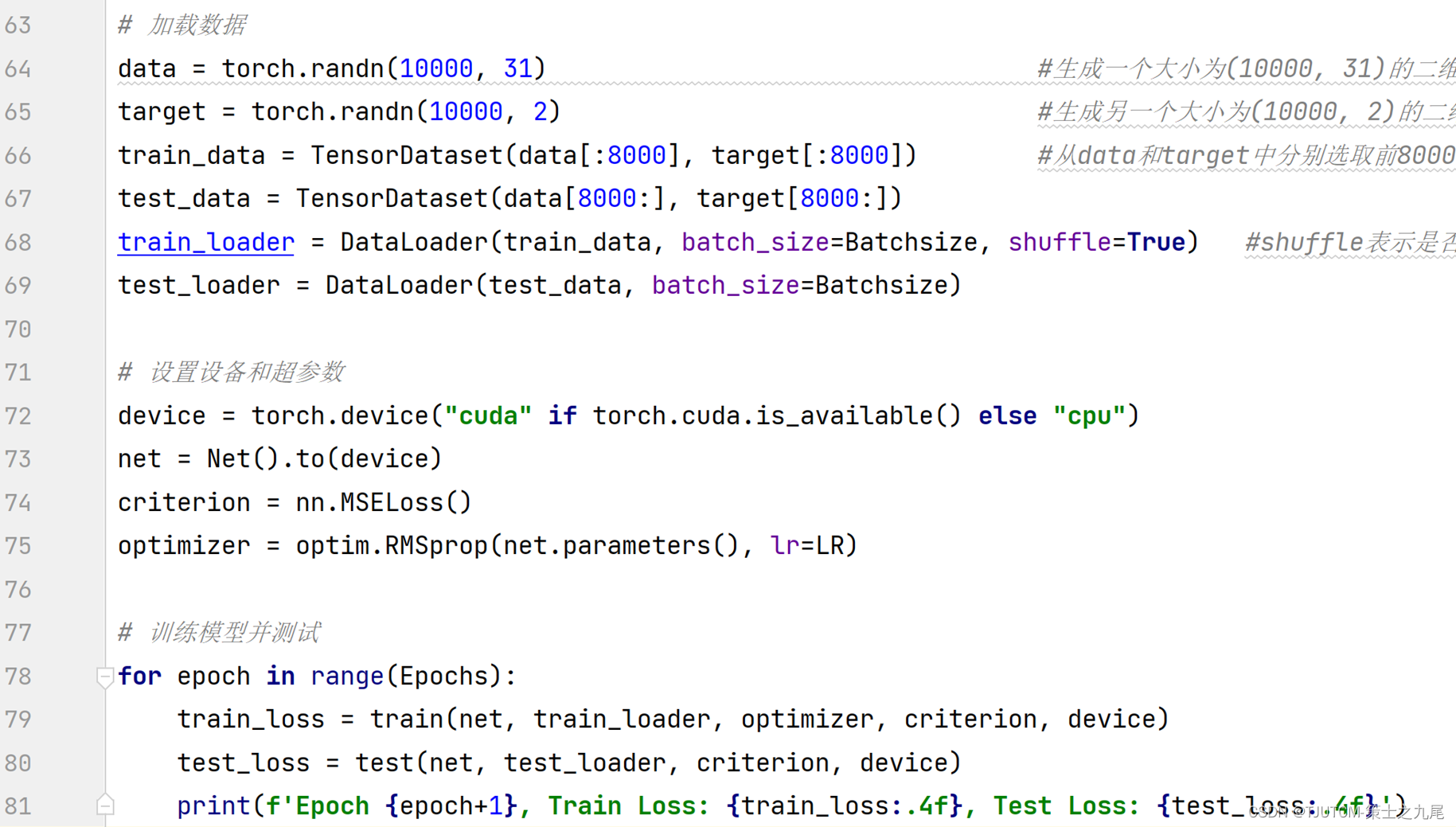
Batchsize=256,Epochs=100。
Epoch:一个epoch 指的是把所有训练数据丢进神经网络一次。
Iteration(step):指的是一批数据要分成几次丢进神经网络。
Batchsize:数据的个数,指的是每次扔进神经网络训练的数据是几个。
例:如果你有100个训练数据,epoch = 10, batchsize = 5, iteration = ?
把100个数据集扔进神经网络训练10次,每次(每个epoch)你要把100个数据集分成20份,每份数据为5个(batch size=5),所以你需要投入20次(iteration)来完成一个epoch
为了进一步促进稳健学习,将白噪声(标准差为0.002)注入到训练数据中。
损失定义为估计的质子交换速率(kb)和比例浓度(fb)与其相应的基准真值之间的均方误差。使用RMSprop算法作为优化器,学习率分别设置为0.001和0.0001。
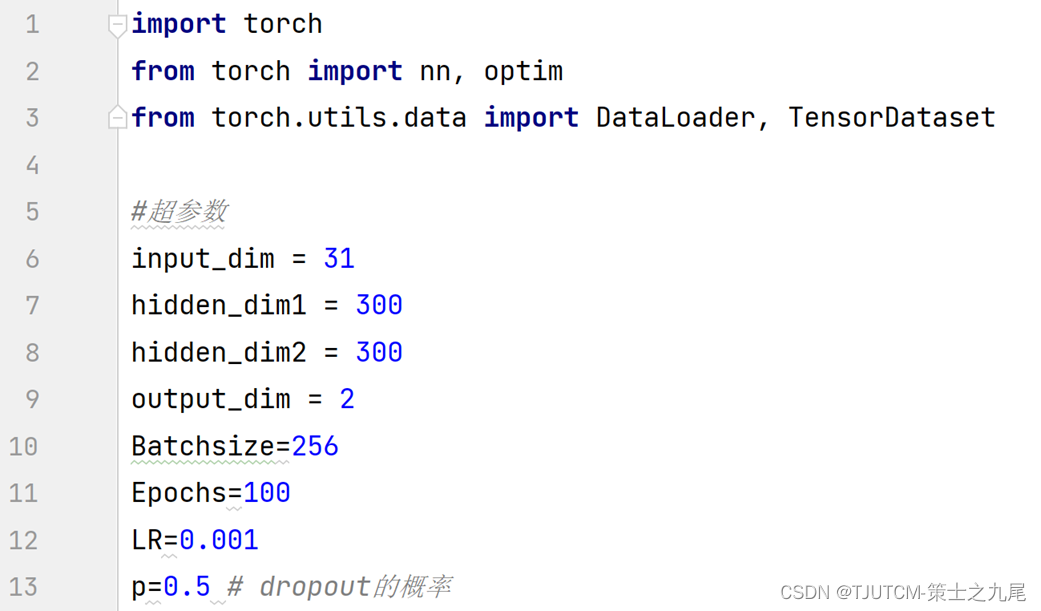
Dropout是一种防止过拟合的技术。
其主要思想是在训练过程中随机地丢弃一些神经元和连接(以一定的概率随机将某些神经元的输出置为零),以降低模型的复杂度,从而提高泛化能力。
训练模式:net.train() √
评估模式:net.eval() ×

















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











