









深度学习无监督磁共振重建方法调研
- An autoencoder based formulation for compressed sensing reconstruction(MRI,2018)
- Solving Inverse Problems in Imaging via Deep Dictionary Learning(IEEE Access2022)
- Reconstructing multi-echo magnetic resonance images via structured deep dictionary learning(Neurocomputing,2020)
- Arterial spin labeling MR image denoising and reconstruction using unsupervised deep learning (NMR in Biomedicine)
- SelfCoLearn: Self-supervised collaborative learning for accelerating dynamic MR imaging(arXiv2022)
最近因为研究需要,对无监督的磁共振重建方法做了一些调研。所谓无监督磁共振重建,是专门针对于深度学习方法的,因为基于神经网络的深度学习的网络参数需要学习,无论是学习直接进行重建的网络,还是学习稀疏编码域从而辅助压缩感知算法进行优化,都通过 降采样-全采样数据对来训练网络参数。传统的压缩感知方法本身就不是机器学习,所以也不存在监督不监督了(当然非要分的话也是无监督的)。
An autoencoder based formulation for compressed sensing reconstruction(MRI,2018)
这应该是比较早的基于神经网络的无监督重建方法。本文提出了一种基于自编码器的无监督自适应压缩感知MRI重建方法。
基于自编码器的压缩感知优化
对传统的字典学习,变换域学习等方法的压缩感知重建公式可以表示为:

或者

其中
P
P
P代表了对于图片Patch的提取操作,
z
z
z代表了字典的index,也就是说,图片patch被转换到用稀疏的index
z
z
z表示的稀疏域。
本文则将基于字典的稀疏域改成了基于自编码器隐空间的稀疏域:
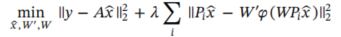
对于其中
W
W
W代表了编码器,
W
′
W'
W′代表了解码器,
ϕ
\phi
ϕ代表了激活函数,可以看出其形式和上面字典学习的表示是很像的,除此之外,对于
z
z
z稀疏性的约束也就转换成了对于
ϕ
(
W
P
i
x
^
)
\phi(WP_i\hat x)
ϕ(WPix^)的稀疏性约束,将其加入损失函数可以得到:
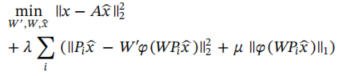
压缩感知问题求解方法
对于上面得到的损失函数,需要优化的变量比较多,可以选择直接对
W
′
W'
W′和
W
W
W,以及
x
^
\hat x
x^进行交替优化,如下:

但是作者认为这样的优化方法比较低效,因此选择采用了分裂Bregman算法对优化目标进行拆解,首先引入代理变量
z
i
=
ϕ
(
W
P
i
x
^
)
z_i=\phi(WP_i\hat x)
zi=ϕ(WPix^)的代理变量和Bregman松弛变量
b
b
b,将问题转换为将转换成如下形式:

然后问题被分解为四个步骤,后续步骤就是分裂Bregman方法,不做赘述。
实验结果&总结
作者对比了字典学习(DL)和转换域学习(TL)的方法,以及直接通过自编码器学习降采样-全采样数据对进行训练(来自于别的文章的结果,并非在实验数据训练),直接输出全采样的结果的方式。
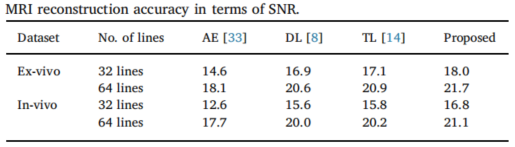
综合来说,本文除了使用分裂Bregman算法进行训练外,基本上就是用自编码器替换了字典学习中的字典,但是自编码器的好处是不需要额外的正交约束(SVD等)也不需要额外的查询匹配算法(OMP等),除此之外通过对神经网络的设计,需要学习的参数远少于学习整个字典或转换域从而避免过拟合。时间上和DL和TL相差无几,和直接输出结果的方法(AE)相比差了数量级。本文可以看作是使用神经网络进行无监督重建的先驱了。
Solving Inverse Problems in Imaging via Deep Dictionary Learning(IEEE Access2022)
上面那篇文章作者作为通讯作者的另一篇文章。我后读的,但是实际上逻辑是在下一篇文章之前。这篇文章号称是首先将深度字典学习应用到生成问题上(个人存疑)。相比下文还更简单了(因为不再考虑multi-echo了)所以我不再解读。实验方法也类似(子问题迭代求解,主要使用Matlab,挺慢)。
贴一个实验结果:

Reconstructing multi-echo magnetic resonance images via structured deep dictionary learning(Neurocomputing,2020)
这篇文章实际上就是深度字典学习在multi-echo(或者说多对比度图像,比如同时对T1和T2的图像进行重建)时的应用。(和上一篇的通讯作者相同,同一课题组的一系列研究)
Multi-echo图像重建
和单词扫描(single-echo)类似,multi-echo的图像也可以表示为如下形式,其中
y
i
y_i
yi和
x
i
x_i
xi就是不同echo的扫描和重建结果,
R
R
R为mask,
F
F
F为傅里叶变换,
η
\eta
η为噪声:
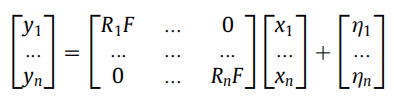
应用压缩感知理论,引入稀疏域
Φ
\Phi
Φ后表示为:

和single-echo不同的是,multi-echo采集的图像往往结构上是类似的,因此研究一般假设其稀疏基
α
\alpha
α具有相同的support,也就是倾向于在相同的地方取非0值,表示在优化目标上,就是把传统的CS优化目标的稀疏约束
∣
∣
α
∣
∣
1
||\alpha||_1
∣∣α∣∣1改变为
∣
∣
[
α
1
α
2
.
.
.
α
n
]
∣
∣
21
||[\alpha_1\,\alpha_2...\alpha_n]||_{21}
∣∣[α1α2...αn]∣∣21(下图应该有误,
α
\alpha
α应该是按列拼接的,可能是缺了转置):
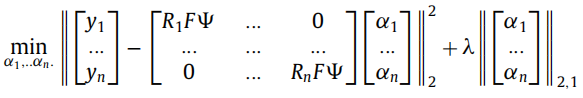
深度字典学习
传统的字典学习(DL),其将图像的patch用字典的键值表示,并对键进行稀疏约束(可以参考我的这篇博客),而深度字典学习则更进一步,将字典扩展到多层的情况,并施加费县下层,从而丰富了语义表示,如下所示:
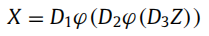
对应地,其压缩感知优化目标也就变成了:
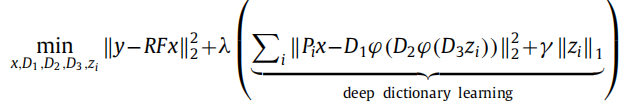
将其和上面的multi-echo情况结合,得到了完整的multi-echo的深度字典学习:
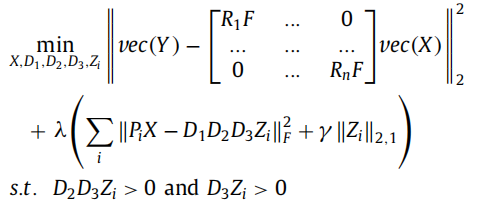
注意这里只是没有写,仍然有非线性层(本文用ReLU,刚好也满足了下面的非负约束)。
然后作者引入代理变量,将上面的优化目标转换为多个子问题,并使用ADMM算法进行求解,详见原文,不再赘述。
实验结果
这里实验的数据和本文上面那篇文章又一样,果然是一个课题组的,作者也是重叠的,哈哈。
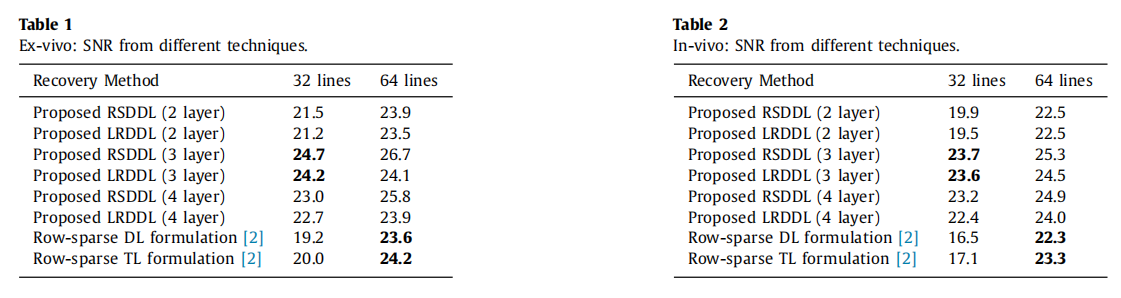
其中RSDDL是按照之前提出的公式,对
Z
Z
Z施加
l
2
,
1
l_{2,1}
l2,1范数的稀疏性优化,LRDDL则是改成采用核范数,从而改为约束低秩性。
Arterial spin labeling MR image denoising and reconstruction using unsupervised deep learning (NMR in Biomedicine)
这篇文章探索了动脉自旋标记成像(ASL)中的一种如监督去噪和重建方法,该方法的特点是不需要任何的训练数据对,仅仅依靠输入图像自身的信息监督进行重建即可,作者在三个实验者上采集了44分钟的完整采样作为GT(8次采集平均,每次5.5分钟)。
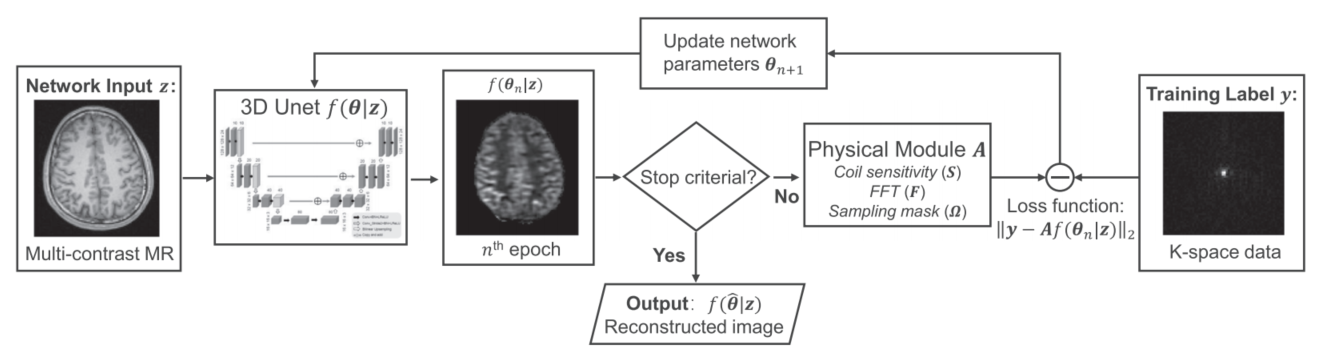
网络结构
整体的方法基于Deep Image Prior,需要注意的是输入的图像为解剖先验的T1图像,生成图像是灌注图像,通过和降采样数据进行损失计算优化整个模型。
对于去噪任务,损失直接如下:
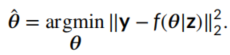
对于重建任务,损失函数如下,典型的Deep Image Prior的损失:

其中
Ω
\Omega
Ω表示采样矩阵(只针对重建任务,去噪任务时为全采样),
F
\mathcal{F}
F表示傅里叶变换,
S
S
S表示线圈敏感性,
z
z
z为网络输入。
通过ADMM算法设置代理变量
x
x
x并约束
x
=
f
(
θ
∣
z
)
x=f(\theta|\mathbf{z})
x=f(θ∣z),将问题转化为以下几个子问题:

再结合L-BFGS等优化方法进行优化即可。
实验结果
去噪方法对比:
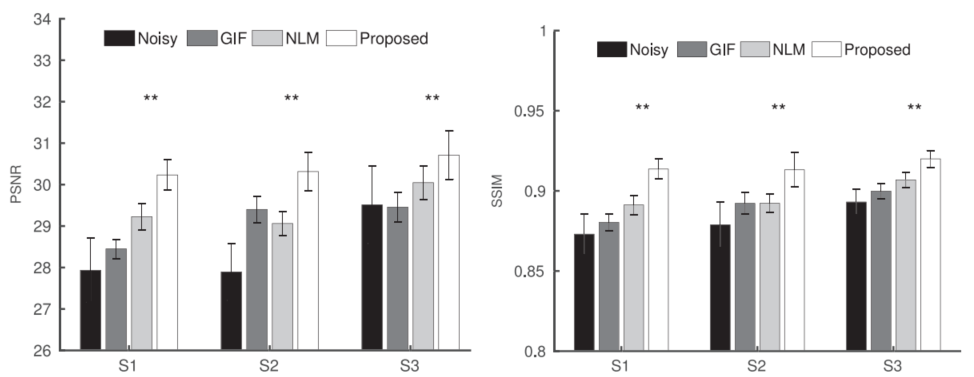
重建结果对比:
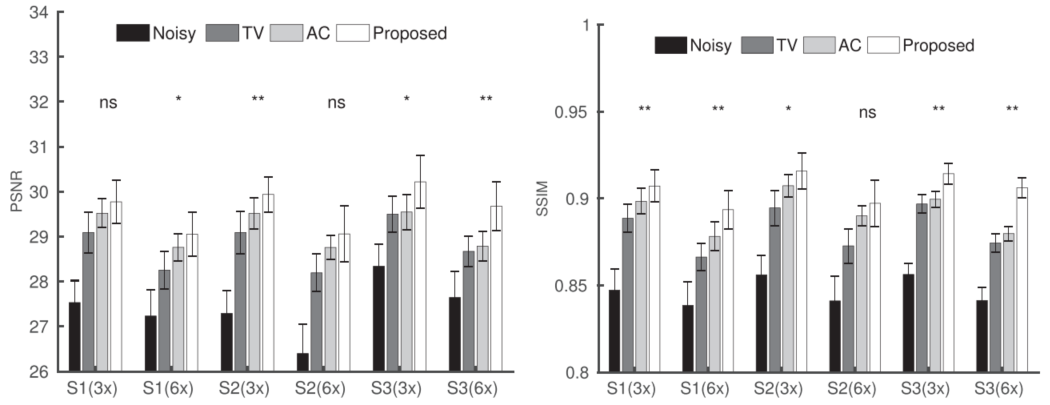
结果还是可以的,不过整体的训练时间比较长,500个epoch的去噪花费了4分钟,重建因为ADMM的优化比较复杂,花了40分钟才完成。
SelfCoLearn: Self-supervised collaborative learning for accelerating dynamic MR imaging(arXiv2022)
王珊珊团队的作品,这篇文章采用了接近对比学习的方式进行重建模型训练,具体而言,将降采样后的K空间再次进行降采样,然后进入两个不同的网络(Collaborative Network)重建,对重建的结果分别计算k空间部分的consistency损失(类似DIP)以及两个样本彼此之间重建部分k空间的一致性损失(类似对比学习)。

方法
对于给定的k空间数据
y
t
=
P
F
x
+
e
y^t=\bold{PFx}+e
yt=PFx+e,
P
\bold{P}
P为降采样的mask,有一组训练降采样数据
Ω
=
{
y
Ω
t
}
\Omega=\{\bold{y}^t_{\Omega}\}
Ω={yΩt},其中
T
T
T是序列帧数(本文是针对动态MRI的,所以输入包含了一系列时间序列帧),选择不同的re-降采样
u
=
Θ
,
Λ
u=\Theta,\Lambda
u=Θ,Λ得到两组样本:
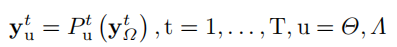
P
u
t
P^t_u
Put是降采样的mask。两组降采样的选择要求:
- 两组降采样可以覆盖原来的样本: y Ω t = y Θ t ∩ y Λ t \bold{y}^{t}_{\Omega} = \bold{y}^{t}_{\Theta} \cap \bold{y}^{t}_{\Lambda} yΩt=yΘt∩yΛt
- 两组降采样不(完全)相同: y Θ t ≠ y Λ t \bold{y}^{t}_{\Theta} \neq \bold{y}^{t}_{\Lambda} yΘt=yΛt
- 包括大部分低频部分
输入两个网络得到重建结果后,损失函数也包括两部分。
一部分是和re-降采样前的数据点的一致性损失(其实也就是真实采样到的点必须被确定地复原):

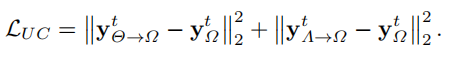
另外一部分是没有采样到的部分的对比损失,也就是两个网络的输出要尽量一致:
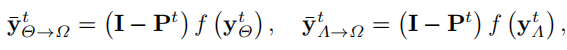
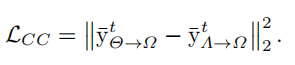
最终损失就是二者相加:
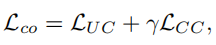
测试时直接将降采样但是没有re-降采样的数据输入Collaborative Network-1就得到了结果。
实验
实验数据选择了3T的Flash序列,大小128x128x14(长宽和时间帧,z轴只有一个slice所以忽略),5950训练50验证214测试。re-降采样采用2倍加速。作者和SS-DCNN和SS-CRNN两种自监督动态磁共振重建方式做了对比:


提出的SelfCoLearn再性能指标和视觉效果上都更好,提供了更好的细节和更清晰的心脏边界等。
作者还和有监督方法做了对比,和U-Net相比SelfCoLearn可以提供更加精确的解剖细节,和有监督的CRNN相比也有相近的结果。
网络结构选择与消融实验
在Collaborative network的具体结构上,该方法相比于SS-CRNN而言不是很敏感,可以是任何重建网络,作者选择了比较有代表性的数据驱动网络CRNN和模型驱动网络SLR-Net等。SLR-Net效果一般可能是因为其设定上有阈值参数更加需要从非re-undersampled的样本学习。

作者还对损失函数进行了消融实验,下图B-I是只训练一个网络,输入
y
Θ
t
\bold{y}^t_\Theta
yΘt重建结果和
y
Λ
t
\bold{y}^t_\Lambda
yΛt的对应部分做一致性损失,类似SSDU的策略。B-II就是只有一致性损失的类似DIP无监督策略。

从B-II和SelfCoLearn的差距来看,对比损失是很重要的。
对于损失函数域的选择来看,选择空域损失的影响不大(不太理解,空域的话未采样点怎么办?)

















 2292
2292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









