







论文全称:Efficient Memory Management for Large Language Model Serving with PagedAttention(Efficient Memory Management .pdf)
目录
Priori Knowledge
链式法则:![]()
联合概率 P(x):这是指所有变量 ![]() 取特定值的联合概率。
取特定值的联合概率。
边缘概率 ![]() :这是变量
:这是变量 ![]() 的概率。
的概率。
条件概率 ![]() :这是在
:这是在![]() 取特定值的条件下,变量
取特定值的条件下,变量![]() 取某个值的概率。
取某个值的概率。
该公式通过逐步计算每个变量在给定前面所有变量的条件下的概率,将一个多维随机变量的联合概率分解成一系列条件概率的乘积。
在实际应用中,像GPT-4这样的语言模型就是利用这种链式法则来生成文本的。
初始概率![]() :首先生成第一个词
:首先生成第一个词![]() 的概率。
的概率。
条件概率 ![]() :然后基于第一个词
:然后基于第一个词 ![]() 生成第二个词
生成第二个词![]() 。
。
依此类推,基于前面的所有词生成下一个词,直到生成完整的句子。
对于初始概率![]() 的计算会用到其它的方法,如数据驱动的方法、平滑技术、基于模型的方法、贝叶斯方法等。
的计算会用到其它的方法,如数据驱动的方法、平滑技术、基于模型的方法、贝叶斯方法等。
在文章里面直接给出了key的权重、query的权重、value的权重,但是并没有具体说明。这三个权重矩阵应该是通过模型训练得到的,文章中只是举例说明。
这些都是在说LLM在输入处理(prompt phase)是可以并行的,但是LLM的预测(autoregressive generation phase)是只能串行的,并且计算需要用到所有前面用到的P(x),键向量、值向量。
大模型请求批处理加速方法:固定长度填充,部分模型需要输入具有固定的尺寸,因此要对输入进行固定长度填充(为了让填充部分不影响工作,需要用注意力掩码)(极大的浪费GPU算力);等长匹配,将长度相近的请求一起处理(会出现让较早请求等较晚请求的现象);
上述的两个方法都是粗粒度的请求方法,同一批次全部处理完成才能处理新的请求。后面出现的cellular batching、iteration-level scheduling可以更加细粒度的控制处理的请求,使不需要同一批全部处理完再进入下一批次。此外,使用特殊的GPU内核可以消除填充输入输出的需要。
操作系统:将内存划分为固定大小的页面,并将用户程序的逻辑页面映射到物理页面。连续的逻辑页可以对应非连续的物理页,以此达到连续的效果,使得程序可以认为自己拥有一个相对连续的大内存空间,即使实际的物理内存(RAM)可能较小且分散。虚拟内存通常比物理内存大很多。
关键概念
-
虚拟地址空间:每个进程都有自己的虚拟地址空间,独立于其他进程。这意味着进程之间的内存访问不会相互干扰,提高了系统的稳定性和安全性。
-
页(Pages):虚拟内存将内存划分为固定大小的小块,称为页。常见的页大小为4KB。虚拟地址空间和物理内存都分为页。
-
页表(Page Table):操作系统维护一个页表,用于将虚拟地址映射到物理地址。页表条目包含虚拟页和物理页的对应关系。
-
页面置换(Page Replacement):当需要访问的虚拟页不在物理内存中(即发生缺页中断),操作系统会将某些页从物理内存中移出(可能是写回硬盘),并将需要的页加载进来。
工作原理
-
地址翻译:当程序访问某个内存地址时,CPU 生成一个虚拟地址。内存管理单元(MMU)会使用页表将该虚拟地址转换为物理地址。
-
缺页中断:如果访问的虚拟页不在物理内存中,MMU 产生一个缺页中断,操作系统捕获该中断并进行页面置换。
-
页面置换算法:操作系统使用页面置换算法(如LRU、FIFO等)选择一个物理页,将其内容写回硬盘(如果已被修改),然后将所需的页加载到该物理页中。
-
执行继续:缺页处理完毕后,操作系统更新页表,程序继续执行。
优点
-
扩展内存容量:虚拟内存使得系统可以运行比物理内存更大的程序,因为它可以利用硬盘作为扩展的内存空间。
Introduction
大模型基于输入(prompt)和之前的序列生成词(tokens),这种顺序工作的模式会给GPUs造成很大的负载。引入批处理可以提高吞吐量,同时,需要更高效的内存管理。一般的LLM内存占比如下图。

KV cache: key-value cache,请求的动态状态,与注意机制相关的键和值张量。1.大多数深度学习框架要求将这些张量存储在连续的内存中 ; 2.随着模型生成新的令牌,它会随着时间的推移动态增长和缩小,并且它的生命周期和长度是未知的。
Solved Questions: KV cache长度未知,导致现有的系统中往往会有很多内部或外部的内存碎片,如下图所示;多样化的解码算法,导致可以共享数据的算法无法共享内存(即每个算法表达方式不一样,数据不能通用)。对应下述挑战。
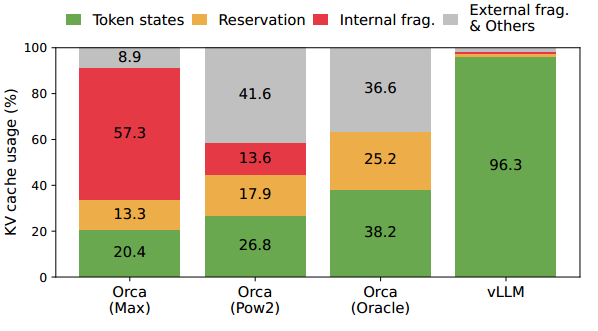
Contributions: 基于OS的内存碎片和共享解决方案提出PagedAttention算法,将块视为页面,令牌视为字节,请求视为进程。使用虚拟内存技术使KV缓存存放的物理空间可以不连续;通过使用相对较小的块并按需分配来减轻内部碎片;因为所有块都具有相同的大小,消除了外部碎片(不属于任何进程的碎片);最后,它支持以块粒度、跨相同请求关联的不同序列甚至跨不同请求共享内存。 1.确定了LLM在内存分配时的挑战,量化了他们对服务性能的影响; 2.提出PagedAttention算法; 3.基于PagedAttention算法设计了vLLM; 4.评估了vLLM
Challenges
- KV cache需要内存太大:一个请求的KV cache可能需要1.6GB的内存,现有的GPU最多达到80GB的内存。
- 解码算法复杂:一个LLM中通常有多种解码算法,KV cache的共享程度依赖于具体的算法,因此需要动态调整共享模式。
- 多变的输入输出长度:不能控制用户提示的长度且解码用户提示时不能控制输出的长度,这有可能导致运行中内存不足。
现有基于分配静态空间、基于压缩的方法,均不能很好的解决空间浪费和内存共享的问题。
读到这里产生的疑问: 1.前面说将内存分为多个相同大小的块可以消除外部碎片,但是由于输入输出长度不能确定,如何确定分配块的大小呢?是否会同样产生很大空间的内部碎片?2.该方法如何解决解码方法导致的内存共享问题呢?
Method
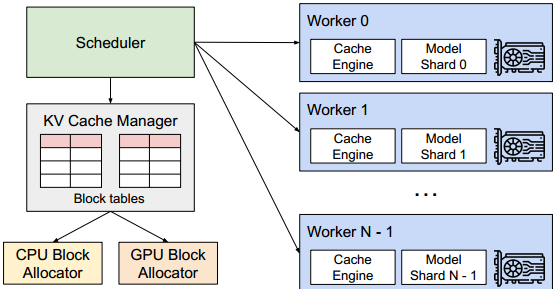
vLLM使用Scheduler集中式调度程序来协调GPU上的线程并发送指令给KV Cache Manager分页式的管理KV缓存(PagedAttention算法)。
PagedAttention
核心是将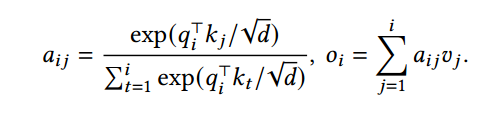 转化为
转化为![]() 由于e的幂相乘会转换为指数相加,对于数量积而言,矩阵a,b,c,满足[a,b]*[c]=[a]*[c]+[b]*[c](矩阵点积的结合律)。该公式将单个KV缓存计算转换成了连续的多个KV缓存组成的块的计算。
由于e的幂相乘会转换为指数相加,对于数量积而言,矩阵a,b,c,满足[a,b]*[c]=[a]*[c]+[b]*[c](矩阵点积的结合律)。该公式将单个KV缓存计算转换成了连续的多个KV缓存组成的块的计算。
- qi 是第 i 个查询向量。
- kj是第 j 个键向量。
- d 是向量的维度。
- exp 是指数函数,表示 e 的幂。
- 分母是对所有键向量的相似度得分的归一化因子。
- Kj和Vj是对应块的键向量
通过该方法,便可以将KV缓存以块单位绑定,使KV缓存没有那么零散,这样有利于后续分散之后的管理。
KV Cache Manager
将KV缓存表示为一系列逻辑块,将GPU划分为物理块,增设块表如下图所示。逻辑KV块直接索引到块表地址,块表地址索引到物理地址以及填充大小。分离逻辑和物理KV块允许vLLM动态增长KV缓存,而无需提前为所有位置保留它,这消除了现有系统中的大部分内存浪费。
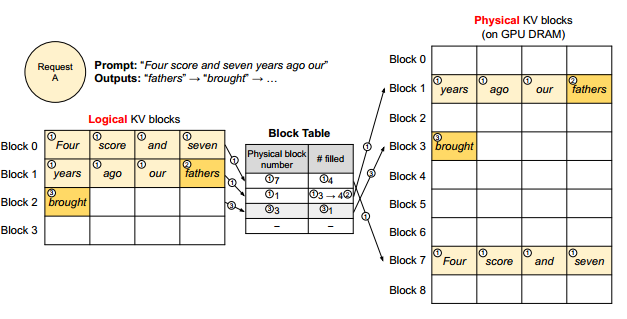
该图中淡黄色为用户输入的提示词,vLLM读到这里的时候会相应的给出两个物理KV块。值得注意的是在逻辑表中他们都是连续的,但是在物理块中,他们是不连续的。随后根据自回归解码算法算出后面的KV缓存,当逻辑块需要增加时,物理块对应增加;逻辑块被填充时,块表的filled字段也对应修改。
读到这有个问题。为什么说这样能增加并行性?应该是把多个KV缓存放到同一块中,然后通过上面的公式能够一起进行计算吧(不确定)。
读到后面发现文章给了解释,原来这里的共享并行是指共享并行用户输入的提示词,我们可以看到下图中的Block7是被Sample A1和Sample A2共享的。
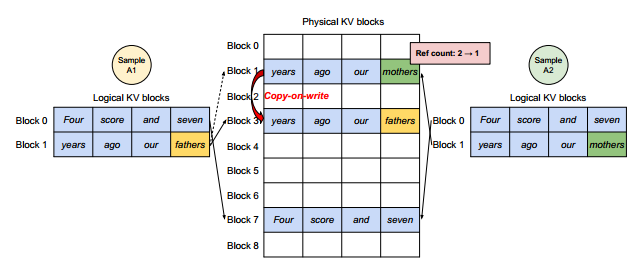
这个图可能还不太明确为什么能共享并行,再看下面这个就更加清晰了。
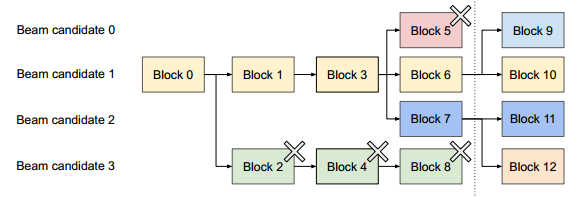
但是为什么说之前的不能达到这样的效果呢?因为之前的结构所有KV cache都是连续的,并不能包含这种并行结构,只能另外开辟一块新的空间。但是在这个方法里面,只需要新开辟一段逻辑KV块,让它们指向相同的物理内存即可(并不真正消耗物理内存)。
General Applicability
Beam Search. 不仅需要共享用户初始输入的提示词,还需要共享候选块,并且共享的模式是随着推理而变化的。这个在上面的图中也有展现,如Block6被Block9和Block10共享。
Shared prefix.通过逻辑块可以指向相同物理块的机制,共享提示词前缀也是可以共享的。
Mixed decoding methods.vLLM通过将逻辑块转换为物理块的公共映射层隐藏了不同序列之间的复杂内存共享,扩大了具有不同采样要求的请求的批处理机会。
Scheduling and Preemption
vLLM采取先到先服务(FCFS)的原则。
如何淘汰内存块。首先同一序列若淘汰则全部的块都被淘汰(对于一个序列,所有的块都是有用的);其次同一请求的序列组若淘汰则全部淘汰(可能存在内存共享)。
如何恢复已经淘汰的内存块。1.交换。如在空间耗尽时,将序列暂放到CPU上并停止接收请求,直到所有抢占的序列完成时再将CPU上的序列恢复出来。 2.重新计算KV缓存。将解码时生成的令牌与原始用户提示连接为一个新的提示,以提高KV缓存计算的速度。
Distributed Execution
因为大部分LLM参数大小都超过单个GPU,所以需要一个处理分布式内存的内存管理器,通过支持Megatron-LM型张量模型并行策略,vLLM在分布式设置中是有效的。该策略遵循SPMD执行计划。
在 SPMD 策略中:
- 单个程序:所有处理器运行相同的程序代码。
- 多个数据:每个处理器操作不同的数据子集。
在模型并行执行时,可能需要同时用到相同的一组输入令牌。因此设置了一个统一的scheduler,scheduler总是首先为批处理中的每个请求准备带有输入令牌id的消息,并为每个请求准备块表。接下来,将他们广播给所有的线程,这使GPU线程不需要同步内存管理,只需要接收内存管理消息和下一步的输入。
Conclusion
本文提出一种新的注意力算法PagedAttention,使KV缓存可以以块为单位计算;引入虚拟内存机制,允许将注意力键和值存储在非连续的分页内存中并为不同的解码算法共享内存提供了更多的机会;提出了一种基于PagedAttention的高吞吐量LLM服务系统vLLM。


















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









