







 本文深入探讨推荐系统中的多种偏差,包括选择偏差、曝光偏差、位置偏差和不公平性等问题。揭示了这些偏差如何影响模型训练与用户反馈循环,并提出了一系列的去偏解决方案,如Propensity Score、逆倾向性加权和对抗性训练等。未来的研究方向包括通用的去偏框架、知识增强的去偏方法以及动态偏差的分析。
本文深入探讨推荐系统中的多种偏差,包括选择偏差、曝光偏差、位置偏差和不公平性等问题。揭示了这些偏差如何影响模型训练与用户反馈循环,并提出了一系列的去偏解决方案,如Propensity Score、逆倾向性加权和对抗性训练等。未来的研究方向包括通用的去偏框架、知识增强的去偏方法以及动态偏差的分析。
作 者:一元
公众号:炼丹笔记背景
在实践中,做推荐系统的很多朋友思考的问题是如何对数据进行挖掘,大多数论文致力于开发机器学习模型来更好地拟合用户行为数据。然而,用户行为数据是观察性的,而不是实验性的。这里面带来了非常多的偏差,典型的有:选择偏差、位置偏差、曝光偏差和流行度偏差等。如果不考虑固有的偏差,盲目地对数据进行拟合,会导致很多严重的问题,如线下评价与在线指标的不一致,损害用户对推荐服务的满意度和信任度等,本篇文章对推荐系统中的Bias问题进行了调研并总结了推荐中的七种偏差类型及其定义和特点。详细的细节可以参考引文。
推荐系统中的反馈循环
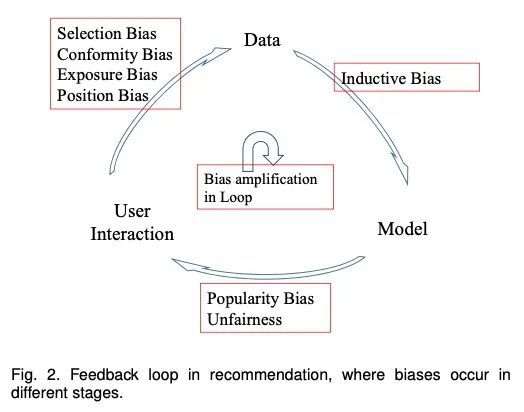
我们可以将推荐系统的循环表述为下面的几个阶段。
User -> Data

Data -> Model
基于收集到的数据进行推荐模型的学习,从历史的交互中学习用户的喜好,并且预测用户可能购买某个商品的概率等;
Model -> User
将推荐的结果返回给用户,以满足用户的信息需求。这一阶段将影响用户未来的行为和决策。
通过上面的循环,用户和推荐系统在交互的过程中,用户的行为通过推荐进行更新,这样土建系统可以通过利用更新的数据进行自我强化。
在推荐系统中的Bias
数据中的Bias
由于用户交互的数据是观察性的,而不是实验性的,因此很容易在数据中引入偏差。它们通常来自不同的数据分组,并使推荐模型捕捉到这些偏差,甚至对其进行缩放,从而导致系统性种族主义和次优决策。本文将数据偏差分为四类:外显反馈中的选择偏差和从众偏差,内隐反馈中的暴露偏差和位置偏差。
1. 显示反馈数据中的Bias
1.1 选择偏差(Selection Bias):当用户可以自由选择要评分的项目时,会出现选择偏差,因此观察到的评分并不是所有评分的代表性样本。换言之,评级数据往往是不随机缺失的(MNAR)。
在rating数据集上面, 用户并非是随机打分的.
- 用户会选择它们喜欢的商品进行打分;
- 用户更倾向于给特别好的商品和坏的商品打分;
1.2.一致性偏差(Conformity Bias):一致性偏差发生在用户倾向于与组中其他人的评分相似时,即使这样做违背了他们自己的判断,使得评分值并不总是表示用户真正的偏好。
这个最典型的例子就是:一个用户会受到诸多其它人的评分的影响,如果很多其他人都打了高分,他可能会改变自己的评分,避免过于严厉。这个问题主要是由于用户受社会影响导致,一个用户往往会受到他朋友的影响。所以我们观测到的评分是有偏的,有些是没法反映真实用户的喜好。
2. 隐式反馈数据的Bias
和显示反馈提供评分不一样,隐式反馈主要反映的是用户的自然行为, 例如购买,浏览,点击等。所以会有很多bias是从one-class的数据中带来的,例如曝光的bias和位置的bias等。
2.1.曝光Bias:暴露偏差的发生是因为用户只接触到特定项目的一部分,因此未观察到的交互并不总是代表消极偏好。
特殊地,用户和商品之间未被观察到的交互可以归因于两大原因:1&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









