






本实验并不是用的C4.5算法,因为sklearn里面是没有真正实现C4.5算法的,本实验严格来说其实是cart算法。(本人小白一枚,纯粹为了记录完成结课作业的过程,代码丢带到jupyter里面完全可跑,如有问题记得踢我。)
一、数据集下载
UCI Machine Learning Repository
二、模型代码实现以及结果展示(使用sklearn库)
导入包
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelEncoder
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd加载数据
def load_data(file_path):
column_names = [
"age", "workclass", "fnlwgt", "education", "education_num", "marital_status",
"occupation", "relationship", "race", "sex", "capital_gain", "capital_loss",
"hours_per_week", "native_country", "income"
]
data = pd.read_csv(file_path, names=column_names, na_values=" ?", skipinitialspace=True)
data.head()
return data数据预处理
def preprocess_data(data):
data = data.dropna()#删除缺失值
label_encoders = {}
for column in data.select_dtypes(include=['object']).columns:
label_encoders[column] = LabelEncoder()
data[column] = label_encoders[column].fit_transform(data[column])
return data模型训练+决策树可视化
def train_evaluate_model(data):
X = data.drop('income', axis=1)
y = data['income']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = DecisionTreeClassifier(criterion='entropy', random_state=42, max_depth=5)#初始化一个决策树分类器模型。
clf.fit(X_train, y_train)#用训练集来训练模型
predictions = clf.predict(X_test)#用训练好的模型对测试集进行预测
report = classification_report(y_test, predictions)#返回模型的分类报告。
# Visualize the decision tree
plt.figure(figsize=(15, 10))
plot_tree(clf, filled=True, feature_names=list(X.columns), class_names=['<=50K', '>50K'], rounded=True, fontsize=10)
plt.tight_layout()
plt.show()
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(X_train)
test_predict = clf.predict(X_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the tree is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the tree is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 混淆矩阵结果可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
return report主函数调用
def main():
file_path = 'D:/postgraduate_study/pythonProject/adult/adult.data' # Replace with your data file path
data = load_data(file_path)
data = preprocess_data(data)
report = train_evaluate_model(data)
print(report)main()结果展示
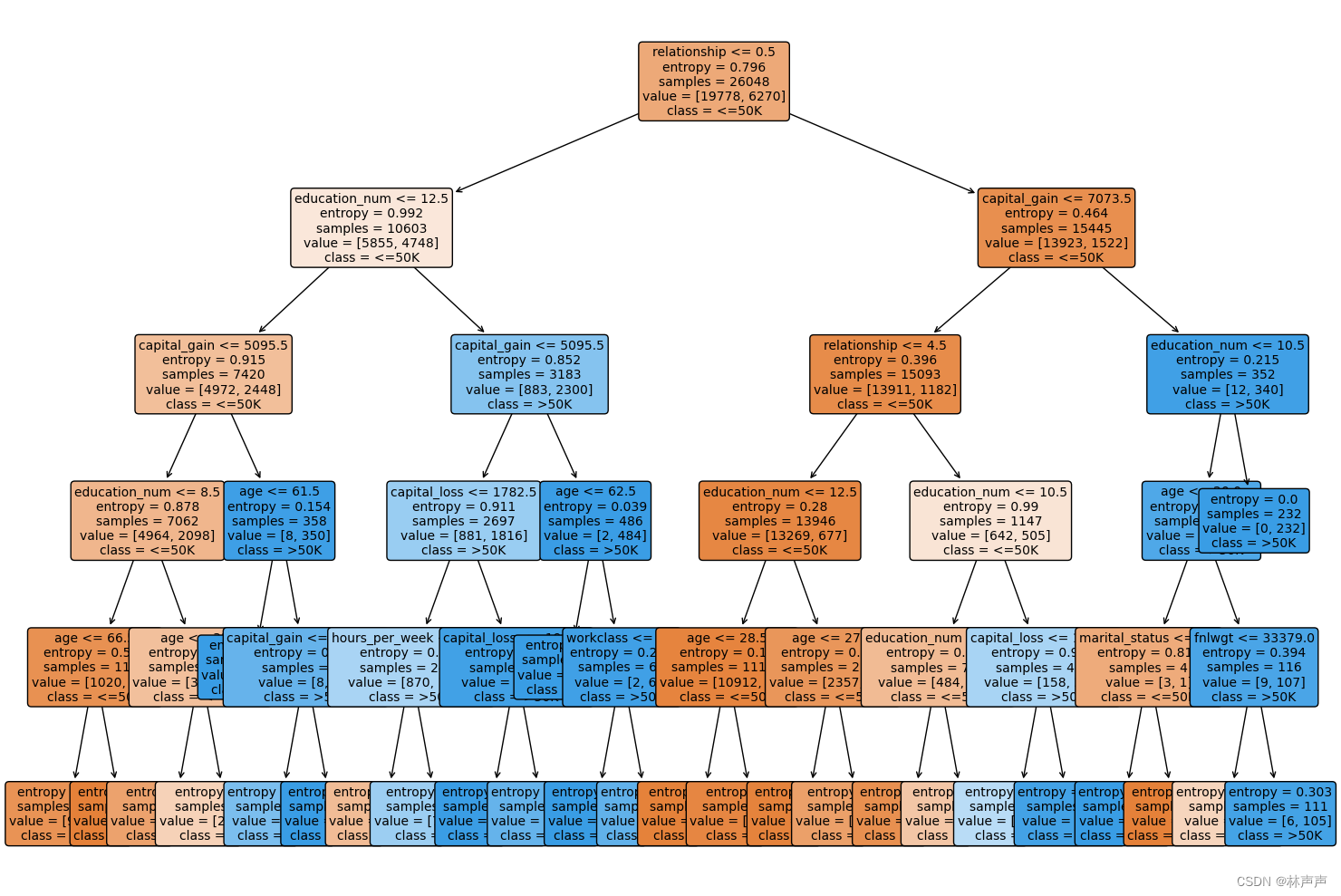 图一 决策树可视化
图一 决策树可视化
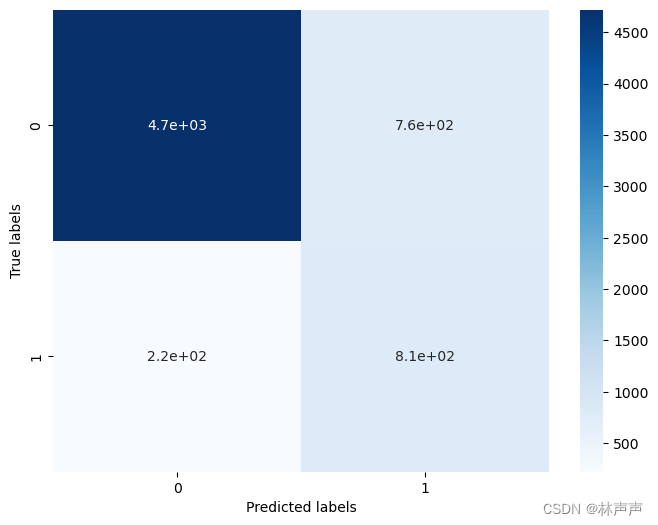
图二 混淆矩阵

图三 模型准确率
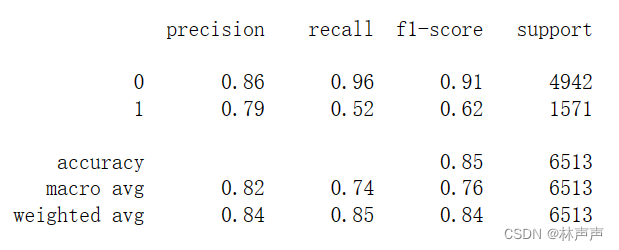
图四 模型评估
三、数据集可视化分析
进行简单的数据查看
file_path = 'D:/postgraduate_study/pythonProject/adult/adult.data'
data = pd.read_csv(file_path)
data.info()# 利用.info()查看数据的整体信息
data.head()# 进行简单的数据查看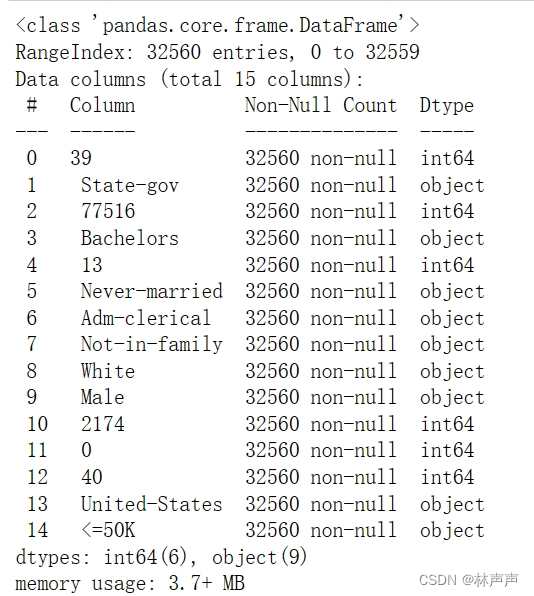
柱状图、散点图展示
column_names = [
"age", "workclass", "fnlwgt", "education", "education_num", "marital_status",
"occupation", "relationship", "race", "sex", "capital_gain", "capital_loss",
"hours_per_week", "native_country", "income"
]
file_path = 'D:/postgraduate_study/pythonProject/adult/adult.data' # Replace with your data file path
adult = pd.read_csv(file_path, names=column_names, na_values=" ?", skipinitialspace=True)
adult = adult.dropna()#删除缺失值
#从图1中可以直观看出高收入占比比较高的是执行管理(Exec-managerial)、专业教授(Prof-specialty)
#比较低的是清洁工(Handlers-cleaners)、养殖渔业(Farming-fishing)。
#高收入的职业往往是一些技术含量要高一些的工作或者是科研方面的。
sns.countplot(x= 'occupation', hue='income', data=adult)#hue:在x或y标签划分的同时,再以hue标签划分统计个数
plt.xticks(fontsize=6, rotation=-45) #调整x轴标签字体大小
plt.show()
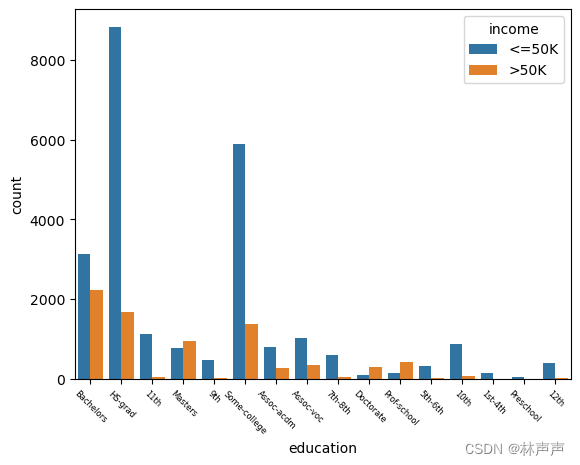
#通过对数据和图形的分析可知,“education”是标称属性
#取值有:'HS-grad高中毕业', 'Some-college', 'Bachelors学士', 'Masters硕士', 'Assoc-voc职业学校', '11th', 'Assoc-acdm'
#'10th', '7th-8th', 'Prof-school', '9th', '12th', 'Doctorate', '5th-6th', '1st-4th', 'Preschool'
#从图2可以看出,学历越高收入>50K的占比越高,大部分人受过高等教育。
sns.countplot(x= 'education', hue='income', data=adult)
plt.xticks(fontsize=6, rotation=-45) #调整x轴标签字体大小
plt.show()
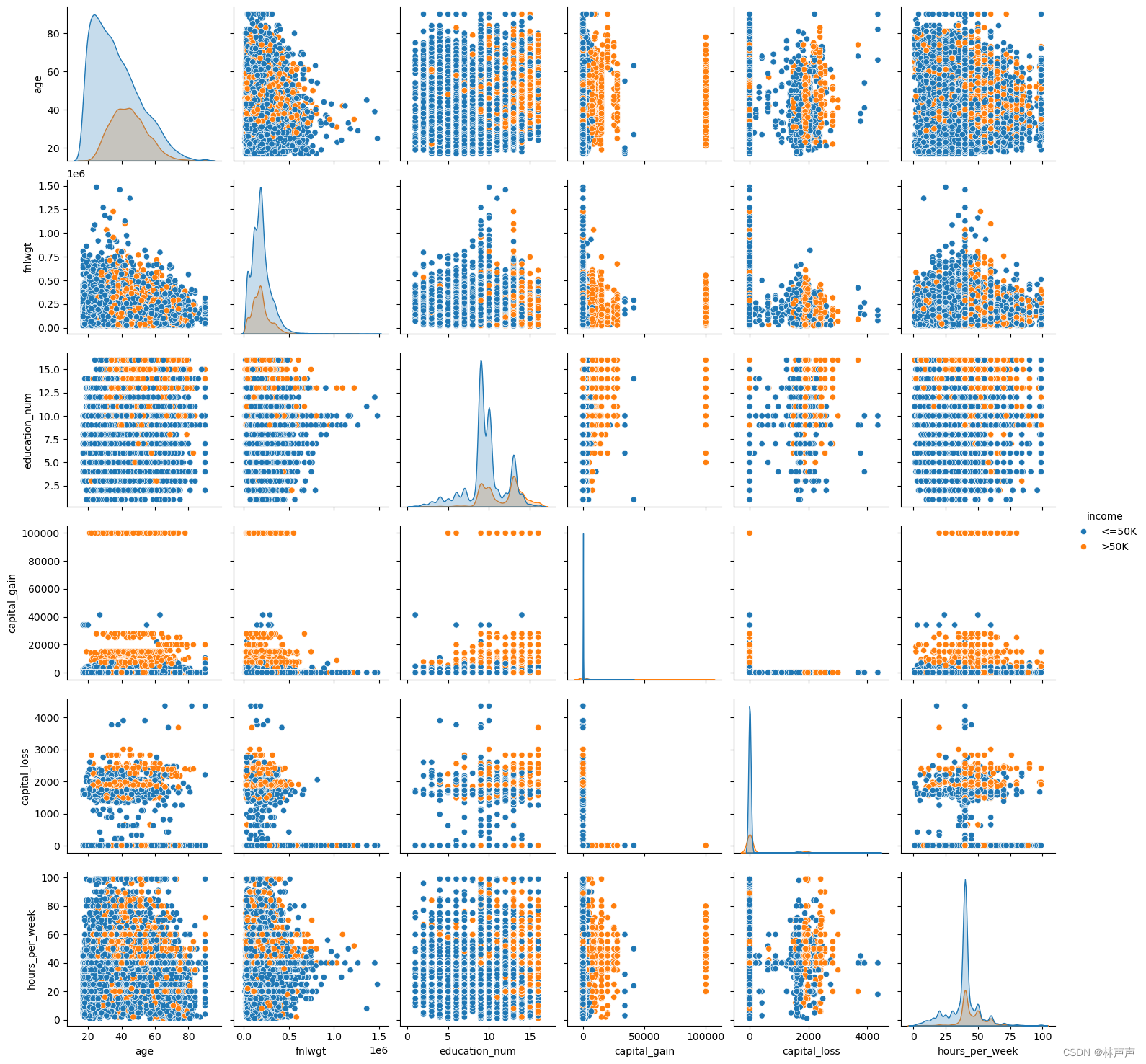
#创建散点图可视化
data_san = pd.read_csv('D:/postgraduate_study/pythonProject/adult/adult.data', names=column_names, na_values=" ?", skipinitialspace=True)
sns.pairplot(data_san, hue='income')
plt.show()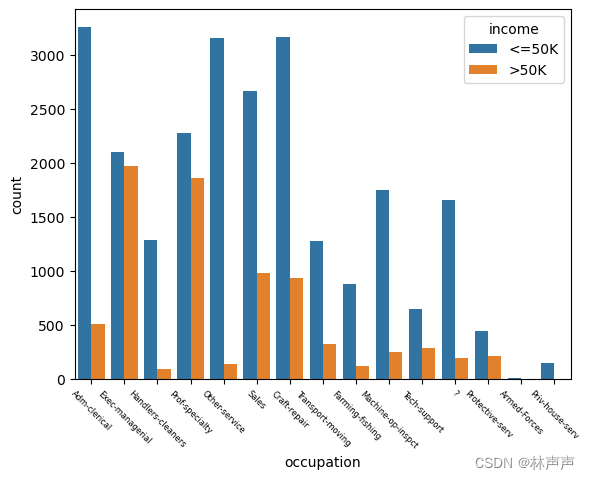

















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









