







 本文详细介绍了如何利用决策树预测个人年收入是否超过50k。内容涵盖数据集介绍、分类变量转换、熵和信息增益计算、最佳属性选择、ID3算法实现以及决策树的构建和预测过程。
本文详细介绍了如何利用决策树预测个人年收入是否超过50k。内容涵盖数据集介绍、分类变量转换、熵和信息增益计算、最佳属性选择、ID3算法实现以及决策树的构建和预测过程。
Dataset
决策树的一个优点是它可以处理变量之间有非线性关系的数据,而这种数据用前面的线性回归是不能做的。
- 本文的数据集是美国1994年的个人收入信息,这个数据还包含了婚姻状况,年龄以及工作类型等等。目标是要预测他们每年的收入与50k的关系{<=50:0,>50:1}
import pandas
income = pandas.read_csv("income.csv")
print(income.head(5))
'''
age workclass fnlwgt education education_num \
0 39 State-gov 77516 Bachelors 13
1 50 Self-emp-not-inc 83311 Bachelors 13
2 38 Private 215646 HS-grad 9
3 53 Private 234721 11th 7
4 28 Private 338409 Bachelors 13
marital_status occupation relationship race sex \
0 Never-married Adm-clerical Not-in-family White Male
1 Married-civ-spouse Exec-managerial Husband White Male
2 Divorced Handlers-cleaners Not-in-family White Male
3 Married-civ-spouse Handlers-cleaners Husband Black Male
4 Married-civ-spouse Prof-specialty Wife Black Female
capital_gain capital_loss hours_per_week native_country high_income
0 2174 0 40 United-States <=50K
1 0 0 13 United-States <=50K
2 0 0 40 United-States <=50K
3 0 0 40 United-States <=50K
4 0 0 40 Cuba <=50K
'''Converting Categorical Variables
- 数据集中有很多分类变量:比如workclass(string:State-gov, Self-emp-not-inc, Private),sex(Male,Female)等等。在进行决策树构造之前,我们利用 Categorical.from_array这个函数将分类变量都转换为数值型数据类型。
'''
包括education, marital_status, occupation, relationship, race, sex, native_country, 以及high_income)
'''
# Convert a single column from text categories into numbers.
col = pandas.Categorical.from_array(income["workclass"])
income["workclass"] = col.codes
print(income["workclass"].head(5))
'''
0 7
1 6
2 4
3 4
4 4
Name: workclass, dtype: int8
'''
for name in ["education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", "high_income"]:
col = pandas.Categorical.from_array(income[name])
income[name] = col.codes- Categorical.from_array函数将分类属性Series对象转换为数值型属性分类变量,其分类取值从string变为number.这样在长树过程中,原本是判断一个人workclass是否等于Private来进行分支,现在就是判断一个人的workclass是否等于4(Private这个分类变量被数值型数据4替代了)来进行分支。
Split
- 可以将决策树看成是一个数据流,数据从上往下开始按照一定的规则流入到每个分支,总之最后每个树枝上的数据流总量等于流进树根的数据总量。当树越深,流进每个树枝的流量就越小。我们需要做的是将同一种流量流进同一个叶子,并且该叶子有唯一标签。
Entropy
熵:是用来找到分裂属性的基础。在概率论中,信息熵给了我们一种度量不确定性的方式,是用来衡量随机变量不确定性的,熵就是信息的期望值。若待分类的事物可能划分在N类中,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
其中b通常取2,熵值越高,则数据混合的种类越高,其蕴含的含义是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大。看个例子:
它的熵计算如下:
计算一下整体的关于high_income这个属性的信息熵:
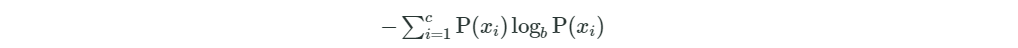

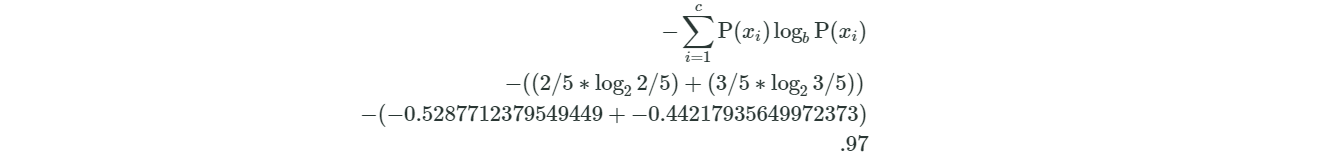
import math
# We'll do the same calculation we did above, but in Python.
# Passing 2 as the second parameter to math.log will take a base 2 log.
entropy = -(2/5 * math.log(2/5, 2) + 3/5 * math.log(3/5, 2))
print(entropy)
'''
0.9709505944546686
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3891
3891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









