







AI OCR文本生成器
欢迎来到AI OCR文本生成器专栏,这是一个专注于深度学习OCR(光学字符识别)模型训练的文本生成工具的专业平台。在这里,您将了解如何使用该工具生成训练CRNN等OCR模型所需的文本行图像。
我们的工具采用模块化设计,允许您轻松添加各种组件,如不同类型的语料库(Corpus)、图像效果(Effect)和布局(Layout)。该工具还与图像增强库imgaug完美集成,支持在图像生成的各个阶段应用不同的效果。无论是生成垂直文本,还是为PaddleOCR生成兼容的lmdb数据集,这款工具都能满足您的需求。
本专栏涵盖了从环境搭建、资源准备到配置文件编写的详细指导,帮助您快速上手。此外,我们还提供了丰富的示例和实践案例,包括如何使用背景图片、字体文件以及文本语料库来生成符合实际业务场景的训练数据。
如果您正在从事OCR相关的研究,或是希望通过训练自己的模型提高文本识别的精度,这个专栏将为您提供全面的技术支持和资源共享。
完整项目代码请访问:Burmese-text-rendering。
文本渲染器
生成文本行图像,用于训练深度学习 OCR 模型(例如 CRNN)。
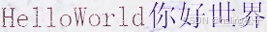
- 模块化设计。您可以轻松添加不同的组件:Corpus、Effect、Layout。
- 与 imgaug 集成,使用方法请参见 imgaug_example。
- 支持在图像上渲染多个语料库并实现不同的效果。 Layout负责多个语料库之间的布局
- 支持在渲染过程的不同阶段应用效果corpus_effects、layout_effects、render_effects。
- 生成垂直文本。
- 支持生成与 PaddleOCR 兼容的
lmdb数据集,请参阅 Dataset - 网页字体查看器。
- 语料库采样器:有助于执行角色平衡
运行示例
运行以下命令使用示例数据生成图像:
git clone https://github.com/lingskr/Burmese-text-rendering.git
cd Burmese-text-rendering
python3 setup.py evolve
pip3 install -r docker/requirements.txt
pip install --upgrade pip setuptools
pip install "fonttools>=4.22.0" "pillow>=8.3.2" "sphinx>=5" "pygments>=2.13.0"
python3 main.py \
--config example_data/example.py \
--dataset img \
--num_processes 2 \
--log_period 10
数据是在 example_data/output 目录中生成。labels.json 文件包含以下格式的所有注释:
{
"labels": {
"000000000": "test",
"000000001": "text2"
},
"sizes": {
"000000000": [
120,
32
],
"000000001": [
128,
32
]
},
"num-samples": 2
}
您还可以使用 --dataset lmdb 将图像存储在 lmdb 文件中,lmdb 文件包含以下键:
- num-samples
- image-000000000
- label-000000000
- size-000000000
您可以检查配置文件example_data/example.py 了解如何使用 text_renderer,
或按照 快速入门 了解如何设置配置
快速入门
准备文件资源
- 字体文件:
.ttf、.otf、.ttc - 任意大小的背景图片,可以来自您的业务场景,也可以来自公开可用的数据集 (COCO、VOC)
- 语料库:text_renderer 提供多种 文本采样方法,
使用这些方法,你需要从两个角度考虑语料库的准备:
- 语料库必须是你想要进行OCR识别的目标语言
- 语料库应该符合你的实际业务需求,例如教育领域、医疗领域等。
- 字符集文件[可选但推荐]:现实场景中的OCR模型(例如CRNN)通常仅支持有限的字符集,
因此最好在数据生成时过滤掉字符集之外的字符。
您可以通过设置 chars_file 参数来实现此目的
您可以从此处下载此“快速入门”的预先准备的文件资源:
将这些资源文件保存在同一目录中:
workspace
── bg
│ └── background.png
── corpus
│ └── burmse.txt
└── font
└── NotoSansMyanmar-Regular.ttf
创建配置文件
在 workspace 目录中创建一个 config.py 文件。一个配置文件必须有一个 configs 变量,它是 GeneratorCfg 的列表。
完整的配置文件如下:
import os
from pathlib import Path
from text_renderer.effect import *
from text_renderer.corpus import *
from text_renderer.config import (
RenderCfg,
NormPerspectiveTransformCfg,
GeneratorCfg,
SimpleTextColorCfg,
)
CURRENT_DIR =Path(os.path.abspath(os.path.dirname(__file__)))
def story_data():
return GeneratorCfg(
num_image=10,
save_dir=CURRENT_DIR / "output",
render_cfg=RenderCfg(
bg_dir=CURRENT_DIR / "bg",
height=32,
perspective_transform=NormPerspectiveTransformCfg(20, 20, 1.5),
corpus=WordCorpus(
WordCorpusCfg(
text_paths=[CURRENT_DIR / "corpus" / "eng_text.txt"],
font_dir=CURRENT_DIR / "font",
font_size=(20, 30),
num_word=(2, 3),
),
),
corpus_effects=Effects(Line(0.9, thick=(2, 5))),
gray=False,
text_color_cfg=SimpleTextColorCfg(),
),
)
configs = [story_data()]
在上面的配置中我们做了以下几件事:
1.指定资源文件的位置
2.指定文本采样方式:从语料库中随机选取2个或3个单词
3.配置一些生成的效果
- 透视变换NormPerspectiveTransformCfg
- 随机线条效果
- 固定输出图片高度为32
- 生成彩色图片。
gray=False,SimpleTextColorCfg()
- 指定字体相关参数:
font_size,font_dir
运行
运行main.py,它只有4个参数:
- config:Python配置文件路径
- dataset:数据集格式
img或lmdb - num_processes:使用的进程数
- log_period:日志打印周期。 (0, 100)
所有效果/布局示例
在 链接 处找到所有效果/布局配置示例
bg_and_text_mask: 三张相同宽度的图像水平合并在一起,
可用于训练 GAN 模型,如 EraseNet
| 名称 | 示例 | |
|---|---|---|
| 0 | bg_and_text_mask |  |
| 1 | char_spacing_compact |  |
| 2 | char_spacing_large | 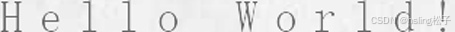 |
| 3 | color_image |  |
| 4 | 曲线 | 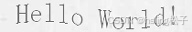 |
| 5 | dropout_horizontal | 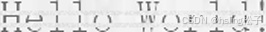 |
| 6 | dropout_rand |  |
| 7 | dropout_vertical | 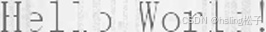 |
| 8 | 浮雕 | 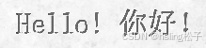 |
| 9 | extra_text_line_layout | 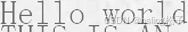 |
| 10 | line_bottom |  |
| 11 | line_bottom_left |  |
| 12 | line_bottom_right |  |
| 13 | line_horizontal_middle |  |
| 14 | line_left | 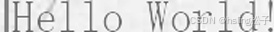 |
| 15 | 线条右 | 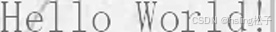 |
| 16 | 行顶 |  |
| 17 | 线条上左 |  |
| 18 | 线条上右 |  |
| 19 | 垂直线中间 | 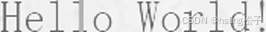 |
| 20 | 填充 | 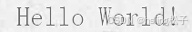 |
| 21 | 透视变换 |  |
| 22 | same_line_layout_different_font_size |  |
| 23 | vertical_text |  |
贡献
设置 Commitizen 以获取提交消息
- 语料库:欢迎为项目贡献更多语料库生成器,
它不一定需要是通用语料库生成器,也可以是特定于业务的生成器,
例如生成 ID 号
引用 text_renderer
如果您在研究中使用 text_renderer,请考虑使用以下 BibTeX 条目。
@misc{text_renderer,
author = {lingskr},
title = {Burmese-text-rendering},
howpublished = {\url{https://github.com/lingskr/Burmese-text-rendering.git}},
year = {2024}
}


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}