






一.tensor数据类型的基本概念
1.Dimension,简称dim
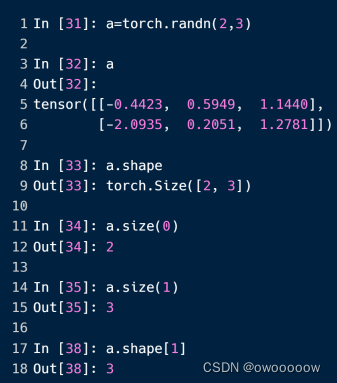
2.shape
表示tensor数据类型的形状,比如一个我们上一节的trains_loader就是一个dim为4的tensor数据类型,它的shape为[512,1,28,28]
3.不同维度的tensor

在pyt0.3以前并没有零维tensor,那时候的loss用一个长度为1的一维tensor表示,后来为了准确区分标量和向量的区别,pyt0.4中加入了零维tensor的概念

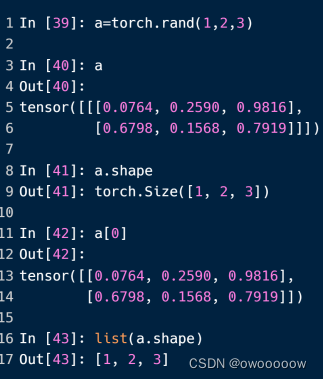
常见的三维tensor有RNN神经网络的输入,每个维度分别表示输入几句话,每句话几个单词,每个单词几个字母
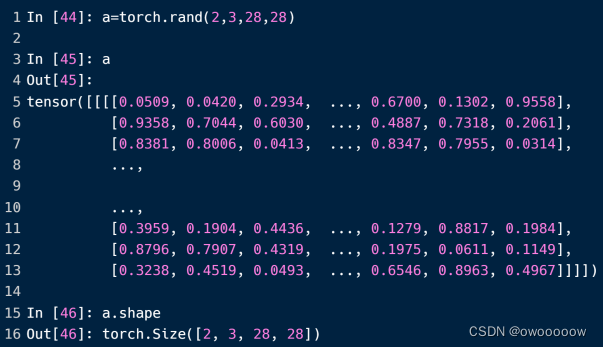
常见的四维tensor有CNN神经网络的输入,就像上一节的mnist数据集一样
二.tensor数据类型的创建
1.利用torch.tensor()直接创建已经初始化好的tensor类型:


2.利用torch.Tensor(shape)创建未初始化的tensor类型

利用torch.Tensor(shape)可以创建相应shape的tensor数据,但是里面的数据是随机初始化的,
这也就导致了它的缺陷:里面的数据可能很大(1e27),也可能很小(1e-43)
这里的tensor中的数据默认都是floattensor类型的,也可以向下面的方式一样通过加上前缀来生成int类型的tensor

这里引入了一个不相关的知识点,改变tensor的默认数据类型
在一些神经网络中,数据类型都是double,因为double的精度更高,所以可以用下面的方法把默认的数据类型改变成了doubletensor

3.利用rand/randlike,randint创建随机生成的未初始化tensor类型
由于方法2具有的缺点,所以引入了rand一类的方法来解决这个问题
①torch.rand(shape)生成[0,1)之间的随机数据
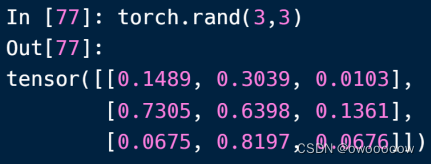
可以看到,里面的数据是分布比较均匀的,不会出现大的数字很大,小的数字很小的局面
如果想要生成[0,10)的shape为3*3的数据,可以这样写:
②torch.randlike(tensor)生成[0,1)之间的随机数据
和①一样,只不过传的参数从shape变成了一个具体的tensor变量,这样生成的tensor的shape就和传进来的tensor的shape是一样的
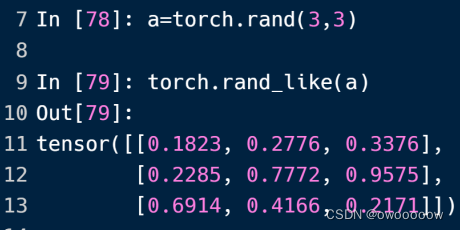
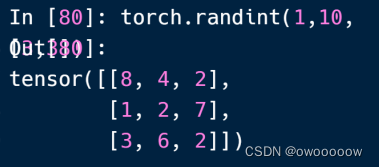
输入torch.randint(1,10,3,3)就生成了如下的结果
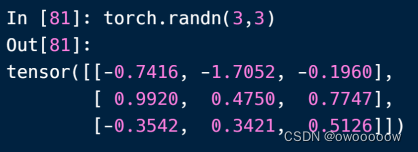
4.利用tensor.randn(shape)生成随机数正态分布tonsor数据类型
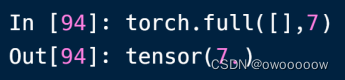
5.利用torch.full(shape,num)创建初始化的tensor数据类型


6.利用tensor.arange(st,ed,skip)生成一维等差数据类型

这样,生成等差数列后,可以重塑tensor的类型,让他变成二维,三维的
7.利用linspace/logspace生成一维等差数据
torch.linspace(st,ed,steps=x)就是把st到ed平均分成x份

torch.logspace(st,ed,steps=x)和linspace一样,都是平均分成x分,不过输出的是结果的对于10的log值 (大概)

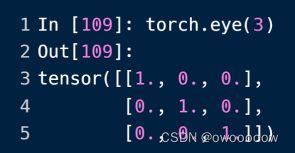
8.利用Ones/zeros/eye(shape)生成关于0和1的tensor数据类型
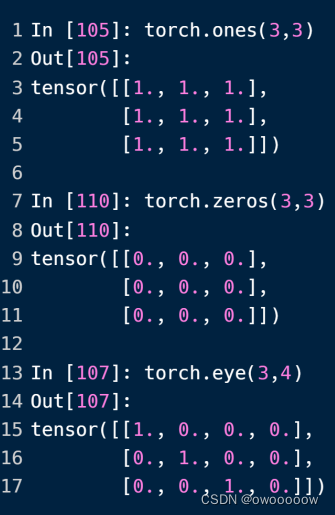
可以看到,ones是生成全为1的,zeros是生成全为0的,eye是生成对角线为1的
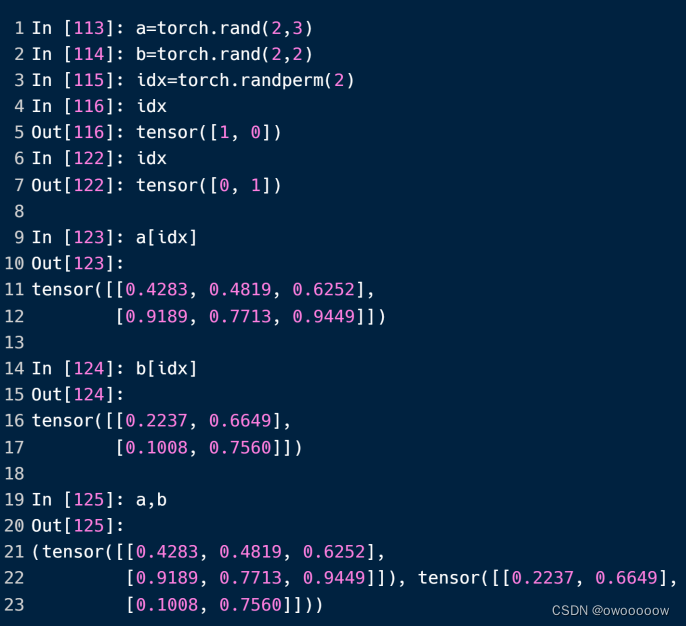
9.利用randperm生成打乱顺序的数据

三.tensor的索引
这里的例子都是一个四维的tensor,它的shape为[4,3,28,28]
1.正常的索引(和c++一样)

2.冒号索引
对于每个维度,格式为x:y:z,表示取从第x到y个,不包含y,每隔z个取一次
都可以缺省,x缺省为开头,y缺省为结尾,z缺省为1,当z缺省的时候,第二个冒号也要不写

3.利用index_select对某一维度进行索引
它的用法为a.index_select[x,tensor([st,ed])]
就是把从高到低的第x个维度(从0开始标号),取这个维度的从st到ed内的数据,不包含ed

4.利用...进行索引
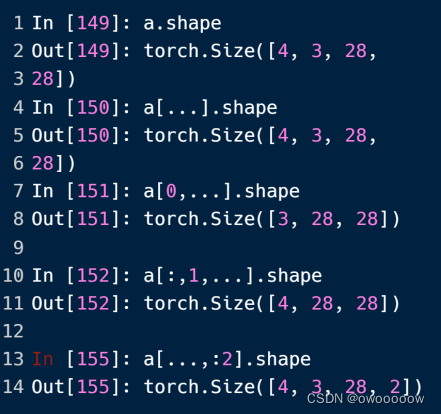
...用在结尾可能有些多余,但是夹杂在冒号索引或者单纯的数字索引中间,可以让写法变得方便许多
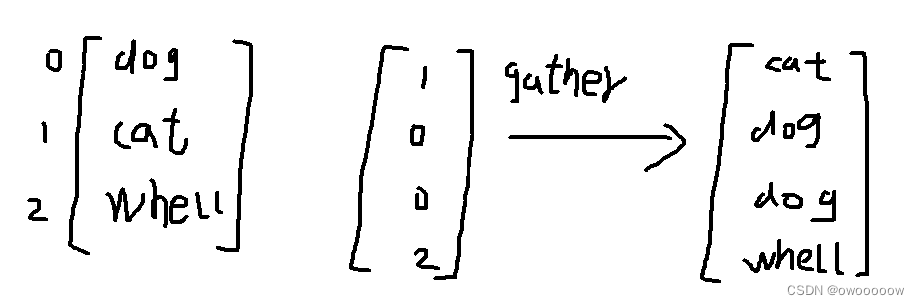
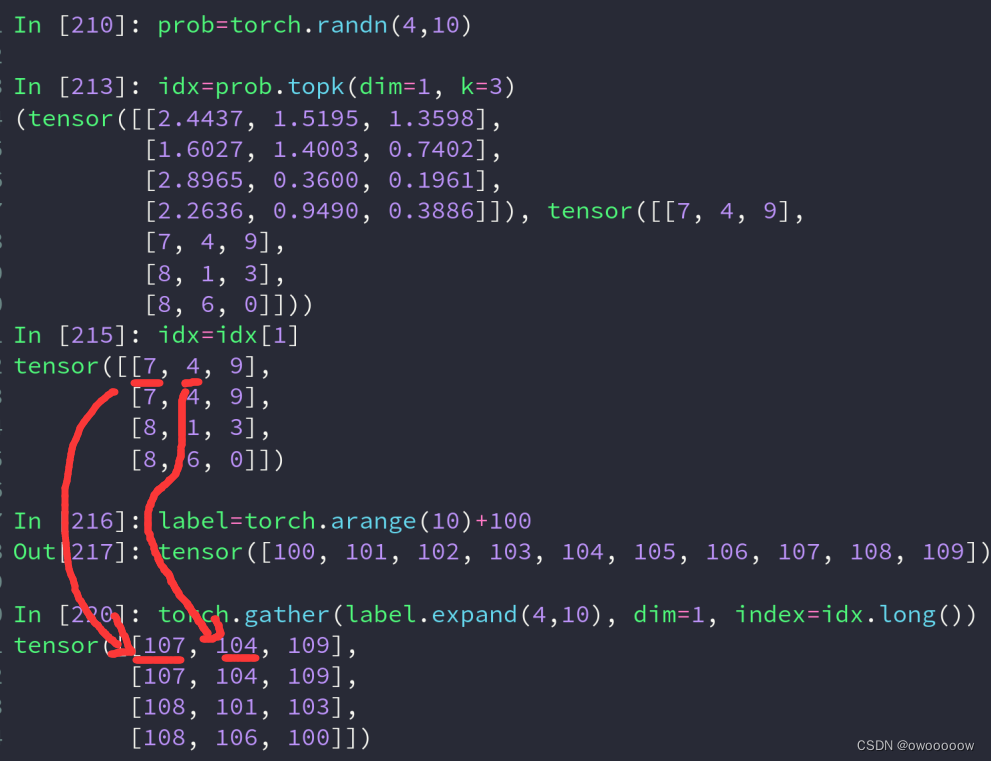
5.利用torch.take(tensor a,tensor b)进行索引
该函数会先tensor类型的a进行平铺,然后再按照b中的数字作为下标进行查找铺平后的a对应的下标

四.维度变换
1.view或reshape
把它的shape进行重组,view操作和reshape操作是完全一样的, pyt0.3之前只有view操作,在pyt0.4之后,为何和numpy的reshape操作进行统一,所以特意推出了reshape操作

有两点需要注意,view前后的size不能改变,比如28*28不能view成500
第二点就是view之后会导致数据缺失,比如[b,c,h,w],每一个维度都有它独特的意义,但是把它view之后,虽然数据没有变,但不知道这些数据是干什么的了
如果view(-1,x),-1代表根据另一个参数x来调整大小,如果size为64,x=16,那么-1这个地方就会自动计算成4
2.squeeze和unsqueeze
对于扩展操作unsqueeze()它需要传入一个下标,正数就是在这个下标的前面增加一个维度,负数就是在这个下标的后面增加一个维度
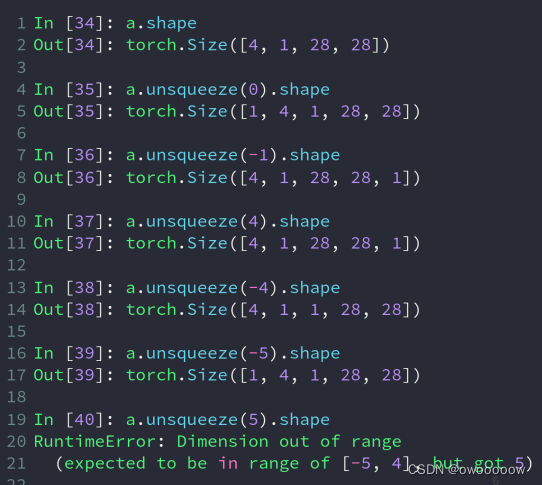

如图,如果用正数,在开头增加一个维度,就是a.unsqueeze(0),在最后增加一个维度就是a.unsqueeze(4)
如果是用负数,在开头增加一个维度就是a.squeeze(-5),在最后增加一个维度就是a.unsqueeze(-1)
squeeze()括号中不放下标,就是把该tensor类型的所有值为1的维度给压缩掉

如果括号中加上下标,那么如果该下标所指的维度的值为1,就压缩,如果不是1,也不会报错,会原封不动

3.Expand / repeat操作
expand操作是不会主动复制数据,如果后续有用到才会复制数据
就比如一张2*2的图片,如果用repeat把他变成2*4的,那么就会把前两号的数据给复制到后两行上

repeat的使用方法与expand有些许不同,它传入的参数不是说让这一维度的值变成多少,而是这一维度的数据要乘多少次
比如b本来的shape是[1,1,2,2],对他进行b.repeat(2,2,2,2)后,它的shape就会变成[2,2,4,4]

4.对于行和列的转换操作

比如a的shape为[1,3,28,28],a.transpose(1,3)的shape为[1,28,28,3]
然而,进行transpose需要人为记住每个维度代表什么含义,并且维度交换顺序后会使原本连续的数据变得不连续了,因此需要用到contiguous()函数让他们继续变得连续
如果想把一个shape[b,c,h,w]变成[b,h,w,c],首先需要transpose(1,3)再transpose(1,2),需要操作两次
而permute(0,2,3,1)就可以一次解决,它的每个参数的含义是该维度用原来的第几个维度来替代
进行该操作需要注意的与transpose一样,需要用到contiguous()
五.Broadcast自动扩展
比如给出一个shape为[4, 32, 14, 14]tensor数据a,代表4张32通道14*14的图片,现在要给每个像素增加偏移量b
这个偏移量的shape为[32, 1, 1],32通道,因为这个偏移量是针对单个像素的,所以是1*1,
按常规理解,a+b是不能够直接相加的,因为他们的shape不一样,但是pyt引出了一套Broadcast自动拓展机制,这里的偏移量在计算的过程中
会自动遵循以下扩展过程,扩展成和a相同的shape,在进行相加就可以了

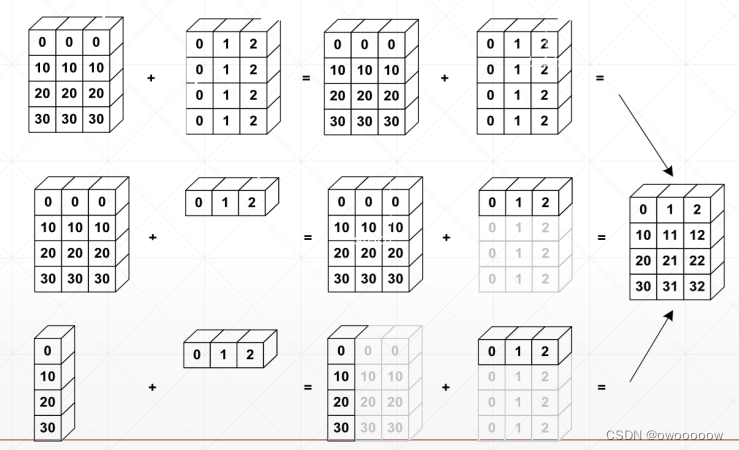
第二行是4*3的矩阵加上一个1*3的矩阵,1*3的矩阵会按照broadcase机制自动扩展成4*3,扩展的数值会复制已经有的数值
第三行是4*1的矩阵加上1*3的矩阵,他们两个会分别自动扩展,然后相加
自动扩展机制在一些现实问题中有比较方便的意义,比如下面这个数据的shape[4,32,8]代表有4个班,每个班有32个学生,每个学生考8门学科的成绩。现在学校发现题目太难了,给每位同学的每个科目加上5分,就可以利用自动扩展机制直接相加


想要扩展的条件就是同一纬度上,要么和要扩展成的数值相同,要么为1,这里最高维度是2,所以不能自动扩展
六.tonsor的拼接与拆分

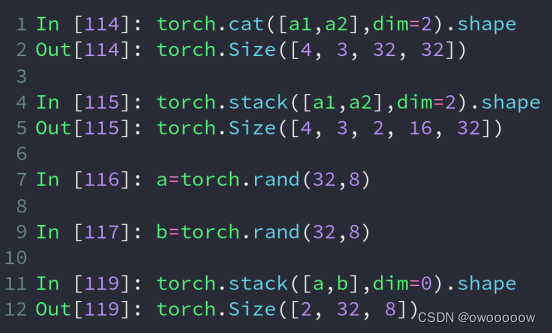
1.利用cat进行拼接
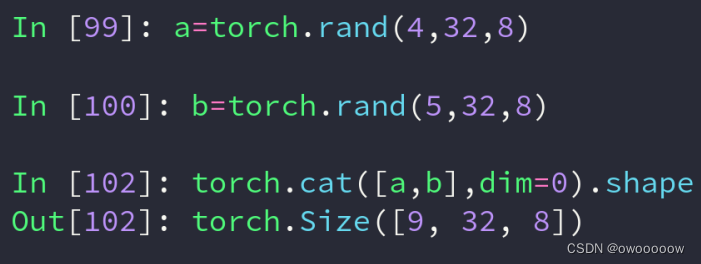
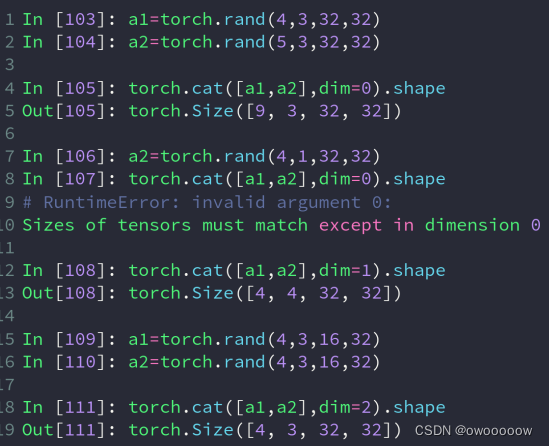
torch.cat([tensor_list],dim=x),第一个参数是一个列表,里面是要进行拼接的tensor,第二个参数是要在第几个维度上进行拼接
除了要进行拼接的dim可以可以不同,其他的dim必须全部相同
成绩单,一个包含四个班级,一个包含五个班级,把他们拼接成九个班级的成绩单
2.利用stack进行拼接
与cat一样,torch.stack([tensor_list],dim=x)

因为会增加一个新的维度,所以要求拼接的tensor之间的所有dim都是完全相同的,就连拼接的那个维度的值也需要相同
比如两个班的成绩单拼接到一起,如果变成了[64,8],就看不出来是哪个班了,用stack变成[2,32,8],最高的那个维度可以表示是第几个班的
3.利用split根据长度进行拆分
x.split(int len,dim = x)表示把x针对第x个维度拆分成长度为len的分tensor
比如a,b,c=x.split(1,dim=0),a,b,c的shape都为[1,32,8]
比如a,b=x.split([2,1],dim=0),这样拆分a.shape = [2,32,8],b.shape = [1,32,8]
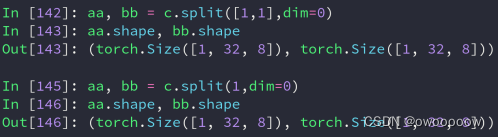
接收的tensor的数量一定要和拆分出来的tensor的数量一样,不然会报错。
4.利用chunk按照数量进行拆分

七.tensor的数学运算
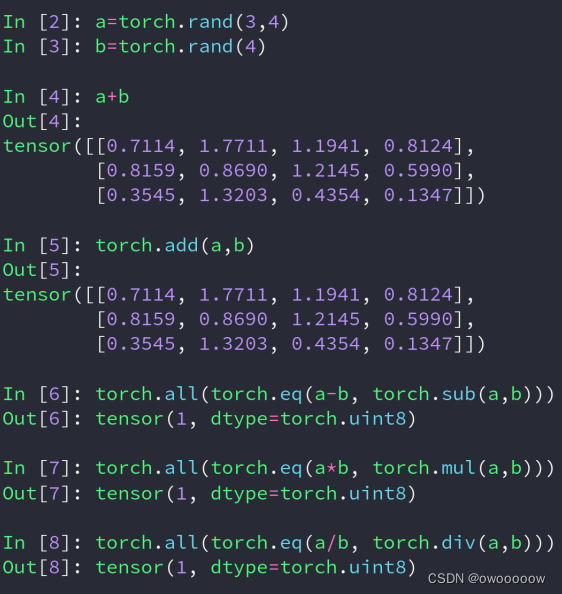
1.加减乘除:
一般建议直接用+ - * /,不要用torch.函数,两者的效果是一样的
2.矩阵相乘
①torch.mm(tensor a,tensor b),这种函数只能计算二维的
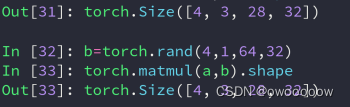
②torch.matmul(tensor a,tensor b),这种情况可以计算多维的,不过它只会让最底层的两维进行矩阵相乘运算
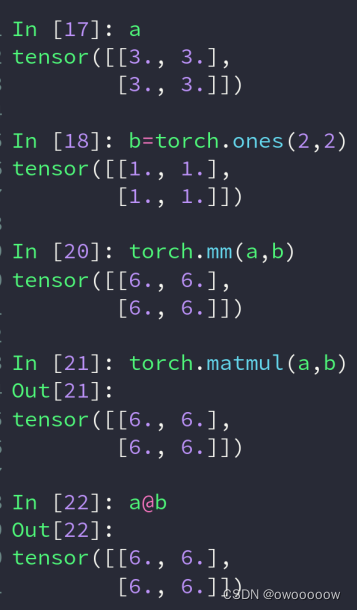
如下图所示,matmul是会调用boradcat自动拓展机制
3.平方

4.exp和log
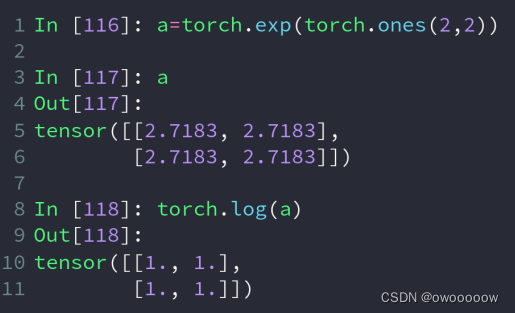
①.torch.exp(tensor a) 为对a中的每个元素x,都取e的x次方
②.torch.log(tensor a)为对a中的每个元素x,都取log x
5.一些取整操作

6.clamp操作
a.clamp(10)意思是让a中的所有数的最小值为10,也就是小于10的让他变成10
a.clamp(0,10)意思是让a中所有数都在0到10之间,小于0的变成0,大于10的变成10

八.tensor中的一些属性

1.norm

a.norm(阶数,dim=x),其中dim=x可以缺省,缺省后代表对a中的所有数据进行norm操作

如图所示,a,b,c的norm(1)按照公式就是8个1累加,结果为8
a,b,c的norm(2)按照公式就是8个1的平方累加,然后开根号就是根号8就是2.8284。

同样,b.norm(1,dim=1)就是对b的第一维进行一阶norm操作,b本来是两行四列,对每一行进行norm,得到了两行norm后的数据,就是[4,4]
同理,对c的第0维进行norm操作,它的shape变化为:[2,2,2]->[2,2]
因此,加入dim的norm操作,得到的shape与原数据的shape相比,进行norm操作的那一dim会消失
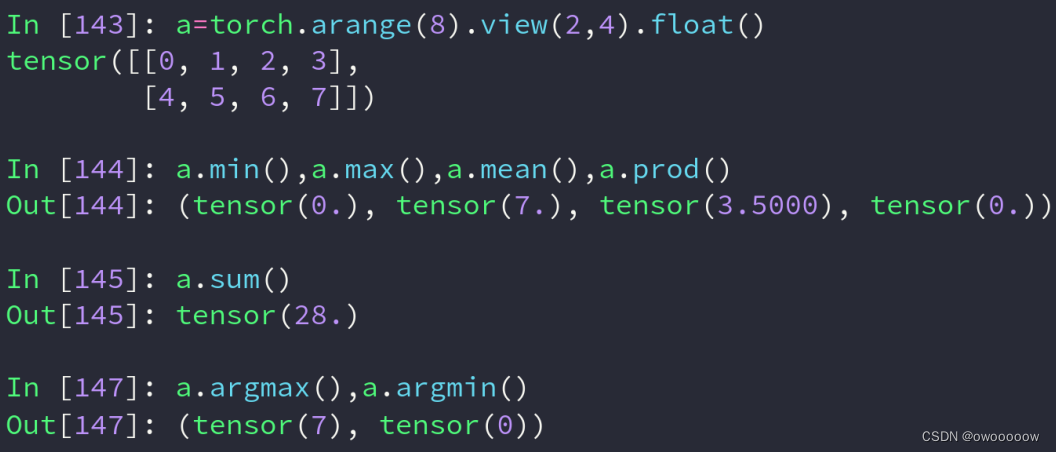
2.min,max,mean,prod,sum,argmax,argmin
分别代表取最小值,最大值,平均值,累乘,累加,最大值标号,最小值标号
3.dim,keepdim
如下面的例子,a4行10列,a.max(dim=1)就返回的每一行的最大值和其位置
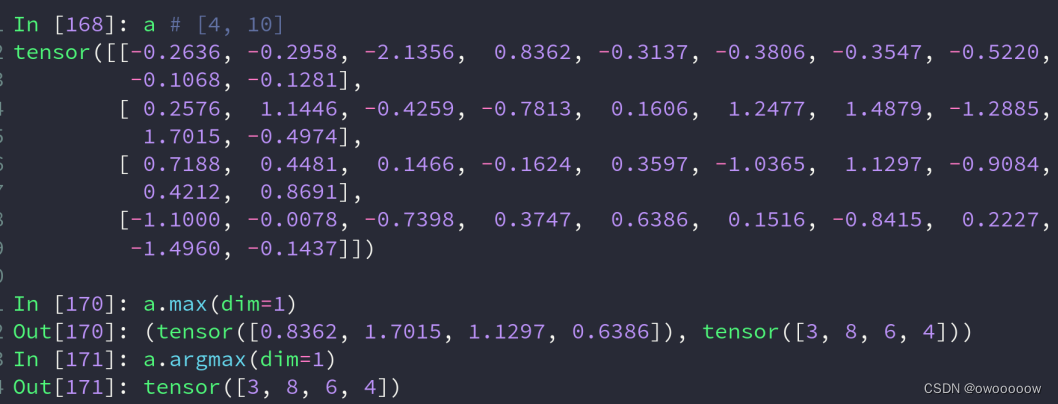
可以看到,返回值缺少了一个维度,所以可以再带上keepdim参数

这样,它的返回值的shape就是[4,1],并没有维度的缺失
4.topk和kthvalue
a.topk(n,dim=x,largest=true/false),其中largest缺省值为largest=true
当largest=false时,是返回a在x维度上前n小的值
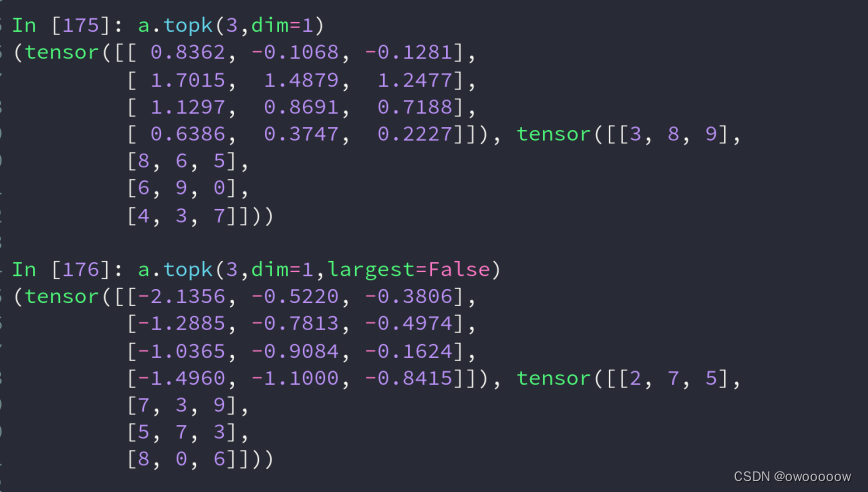
a.kthvalue(n,dim=1)dim可以缺省,缺省了会在最低维度上找

5.比较运算符

eq是对每一位,如果该位置数字相同,为1,不同为0,返回的是一个和a,bshape相同的tensor值
九.tensor的高级操作
1.where操作
一个tensor c,它的数据有的来自于a,有的来自于b,并且不好找规律
我们就可以创建一个和a与bshape一样的表,里面填0和1,如果是0,说明c在该位置的数据来自于a,如果是1,说明c在该位置的数据来自于b

意思就是如果cond表在该位置的值>0.5,那么该位置的数据就来自于a,否则来自于b
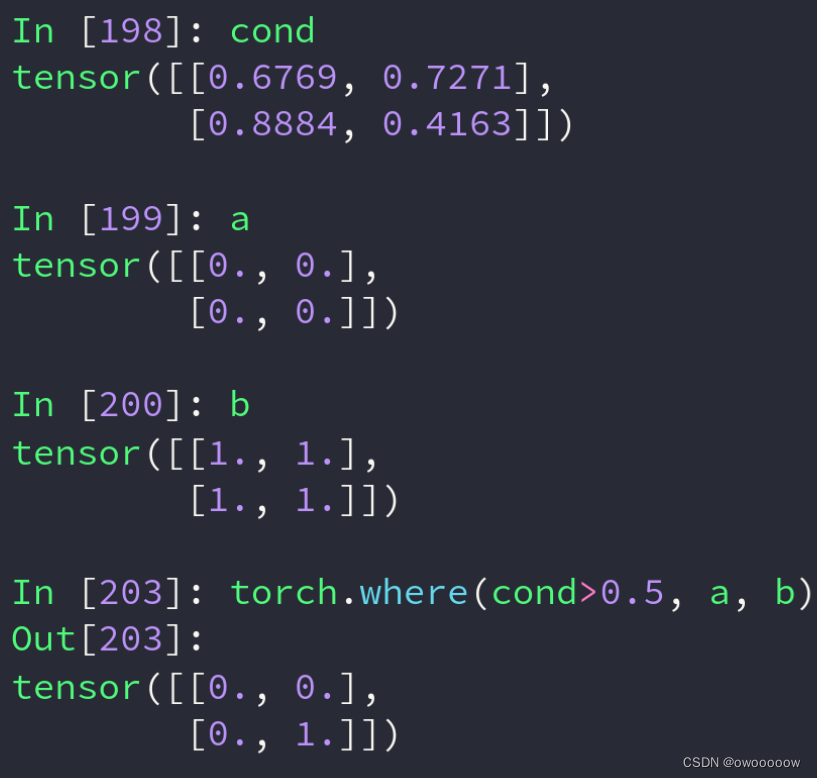
这种问题可以用python自带的多层for循环加上if判断来解决,但问题是这样程序只能在cpu上跑,没办法再gpu上跑了,因此引入了where操作
















 5350
5350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











