







目录
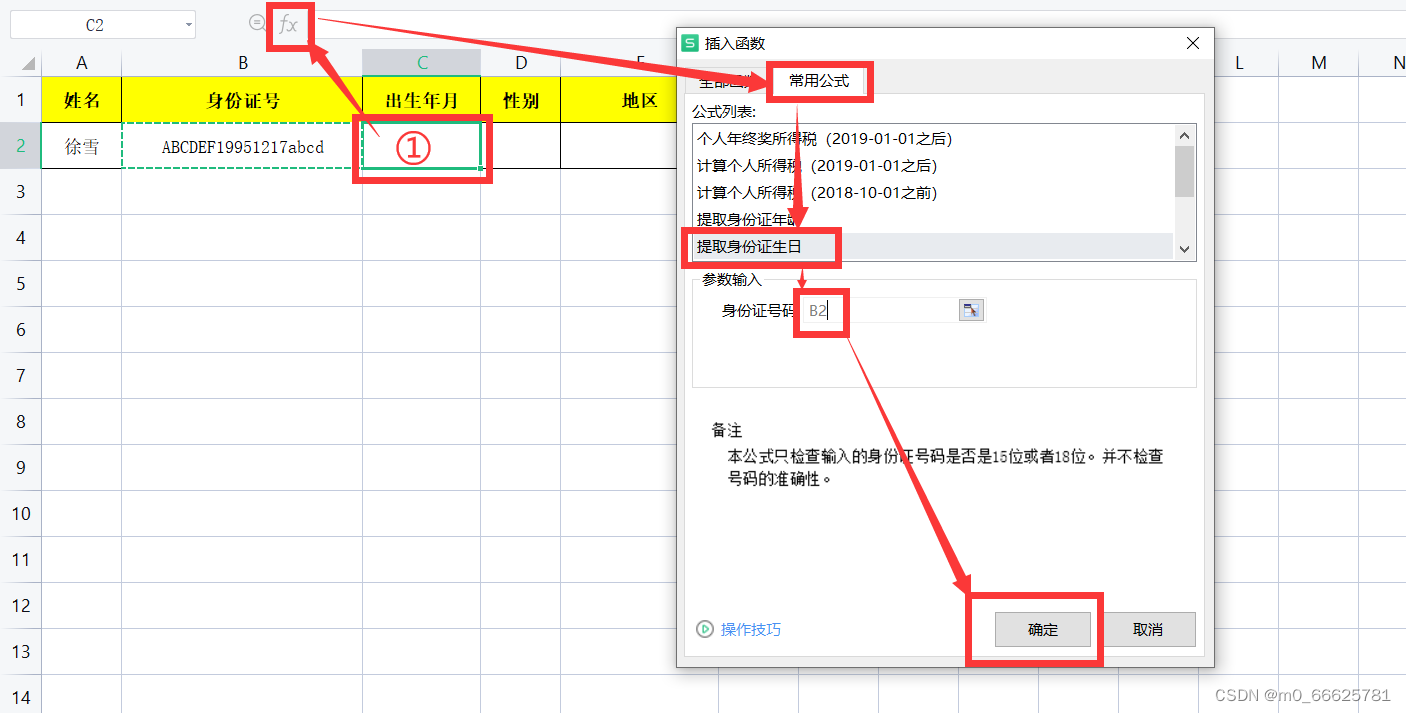
提取出生日期
假设证号在B2单元格,是ABCDEF19951217abcd,出生年月的公式就是=MID(B2,7,8),提取B2的字符串,从第7位开始的8为数字
或者

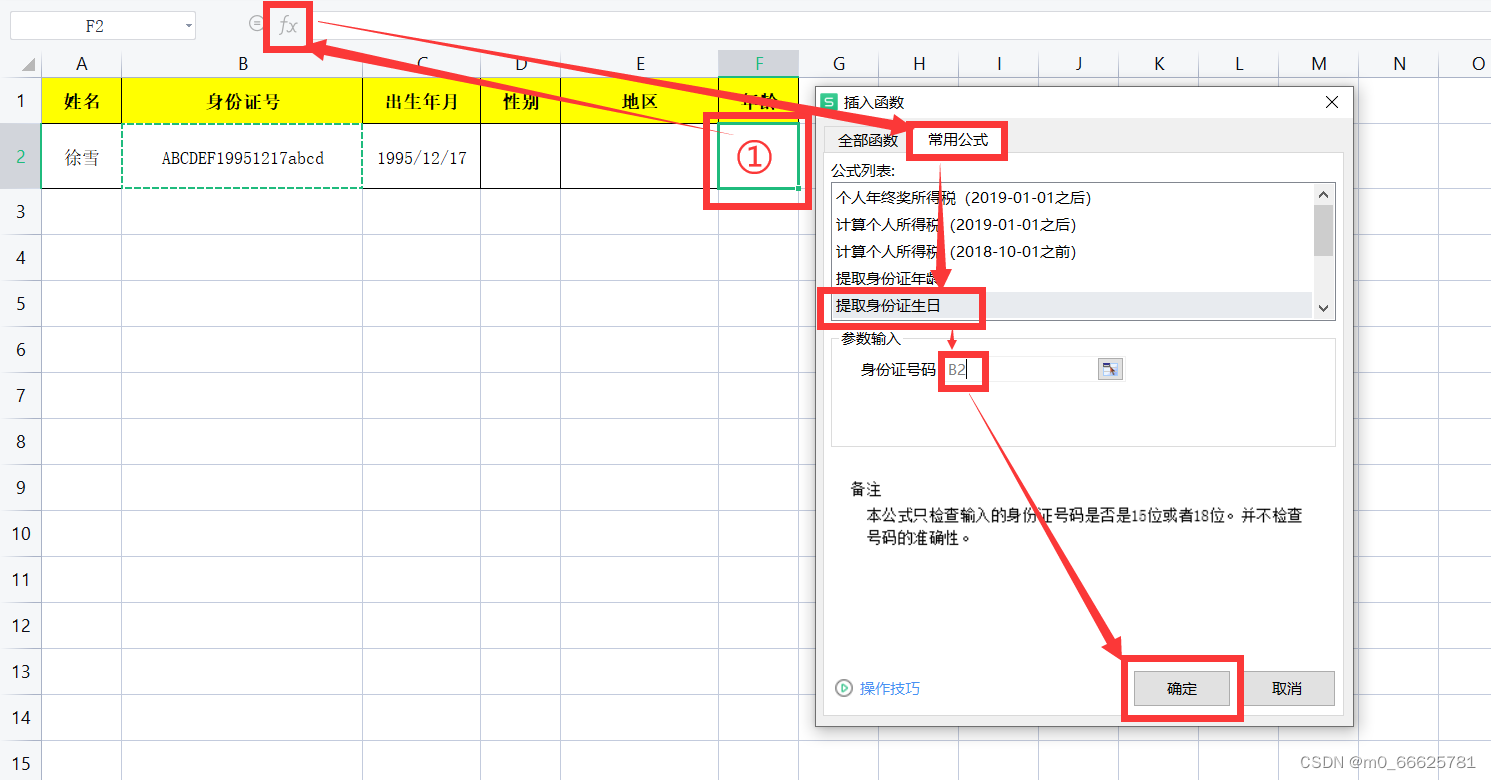
计算年龄
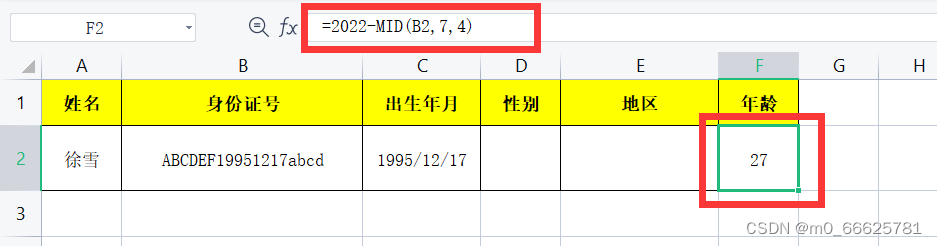
公式=2022-MID(B2,7,4)
其中【MID(B2,7,4)】:提取身份证的出生年份,用现在的年份减去出生日期,就能计算出年龄了
或者
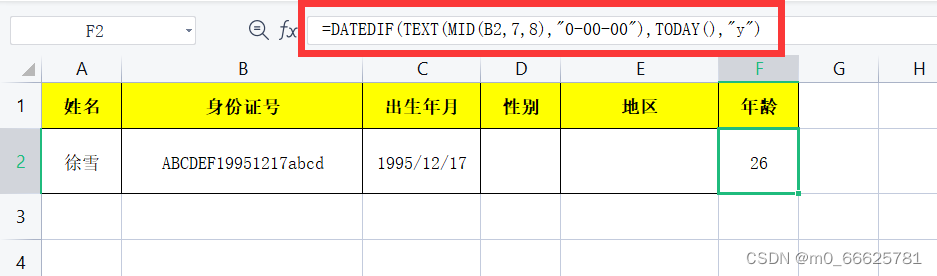
如果今年还没过生日,需要知道目前的年龄,用今天的日期计算:
公式=DATEDIF(TEXT(MID(B2,7,8),"0-00-00"),TODAY(),"y")
或者
性别
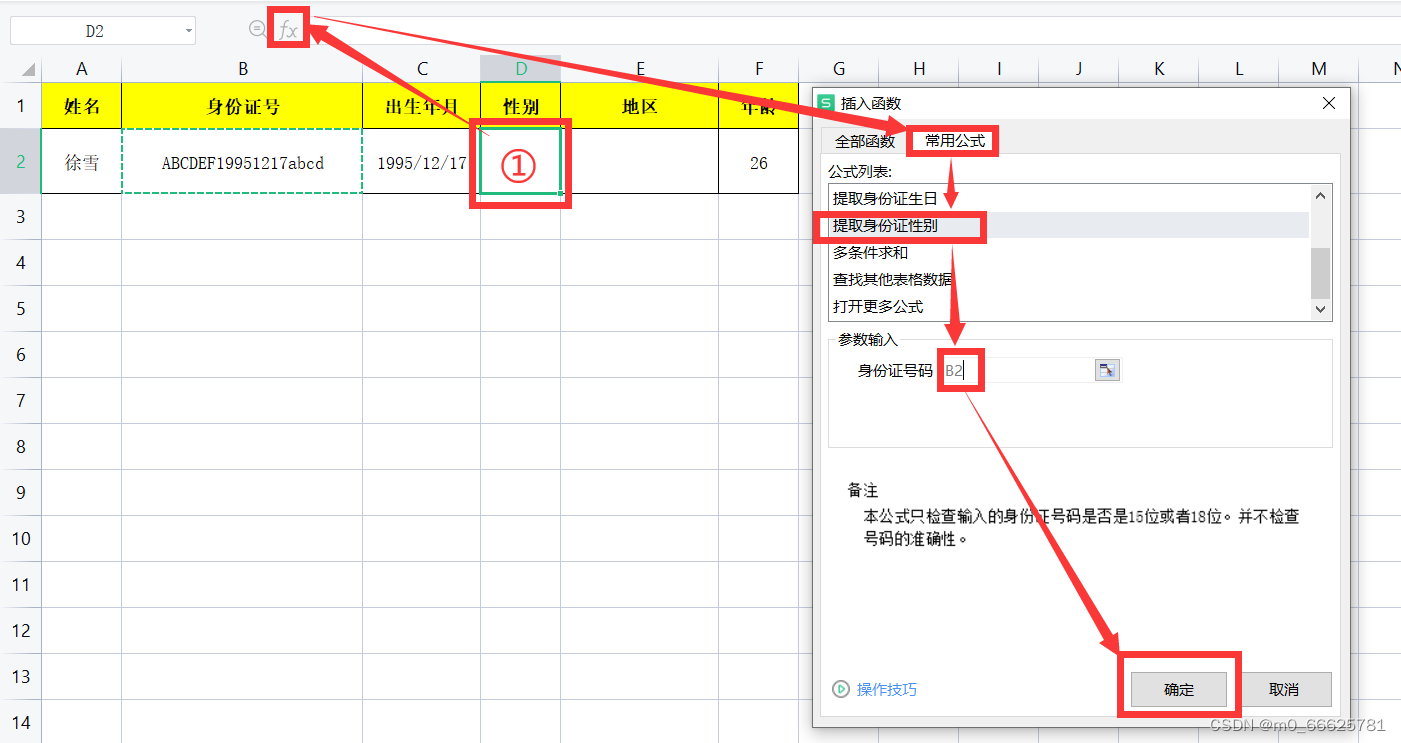
户籍所在地
如果没有身份证地区代码表首先就要此表,如图
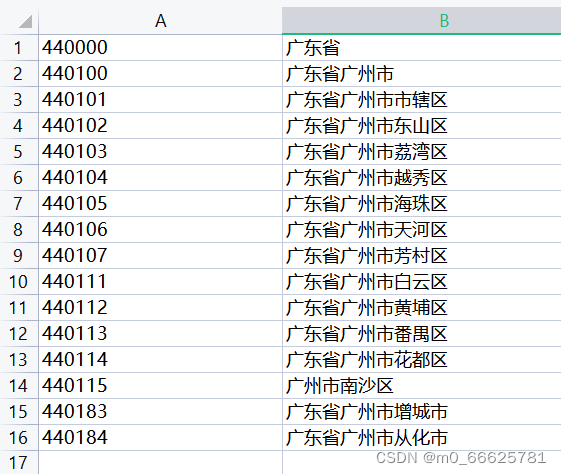
公式=VLOOKUP(VALUE(LEFT(B2,6)),身份证号前六位!A:B,2,0)
LEFT(B2,6) —— 提取身份证的前六位
VALUE(LEFT(B2,6)) —— 将前六位字符转为数字格式
然后再使用VLOOKUP函数,从代码表中查找A列和B列列数为2的相对应的数据
最后可填1或0,1为模糊查找,0为精确查找

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









