







DeepSeek-R1-Distill-Llama-70B模型可以部署在AWS Graviton4芯片的EC2实例上,以极高的性价比实现批处理任务。DeepSeek推出的DeepSeek-R1大语言模型(LLM)自发布以来因其卓越的推理能力而备受关注。该模型利用链式思维(Chain of Thought, CoT)进行问题求解。DeepSeek-R1系列包括DeepSeek-R1-Zero和DeepSeek-R1主模型,它们基于DeepSeek-V3模型架构。尽管主模型参数量高达6710亿,但还有基于Llama 3.1、Llama 3.3和Qwen2.5的较小模型,参数规模从1.5B到70B不等,这些模型是通过DeepSeek-R1的精选数据集进行微调的,被称为DeepSeek-R1 Distill模型。
当前对于部署DeepSeek-R1 Distill模型的需求日益增长。虽然GPU或AI芯片可以提供更快的推理速度,适用于低延迟应用(如聊天助手),但在某些批量推理场景中,使用CPU可能提供更优的性价比。例如企业可能需要从海量的原始文本数据中提取信息,而CPU的成本通常较低,足以满足这类异步推理需求。
AWS Graviton4是亚马逊云科技迄今为止最强大且最高效的处理器,适用于广泛的云端工作负载。相较于上一代Graviton3处理器,AWS Graviton4提供30%更高的计算性能、50%更多的核心数量以及75%更高的内存带宽,能够为Amazon EC2上的各种工作负载提供最佳的性价比和能源效率。
本博客文章重点介绍在Amazon EC2上使用AWS Graviton4部署DeepSeek-R1-Distill-Llama-70B的实操步骤,包括如何部署模型的具体实操步骤以及在测试中的性能表现。本文在北美佛吉尼亚区域(us-east-1)使用了c8g.16xlarge类型实例,该实例配备64 vCPUs和128 GB RAM。

在服务器中使用Graviton4 CPU部署DeepSeek-R1-Distill-Llama-70B
在亚马逊云科技账户中,大家可以按照官方文档创建EC2实例。在本实验中,我们将使用Graviton4实例(例如c8g.16xlarge系列),并选择默认的Amazon Linux 2023 OS操作系统(Amazon Linux 2023 AMI 2023.6.20250128.0 arm64 HVM kernel-6.1)。
实例启动后,大家可以登录创建的Graviton4实例,并运行以下简短的Shell脚本来加载模型,该脚本不足10行代码!随后大家就可以获得最先进的LLM推理性能。
#Install libraries
sudo yum -y groupinstall "Development Tools"
sudo yum -y install cmake
#Clone llama.cpp
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
#build with cmake
mkdir build
cd build
cmake .. -DCMAKE_CXX_FLAGS="-mcpu=native" -DCMAKE_C_FLAGS="-mcpu=native"
cmake --build . -v --config Release -j $(nproc)
#Download model
cd bin
wget https://huggingface.co/bartowski/DeepSeek-R1-Distill-Llama-70B-GGUF/resolve/main/DeepSeek-R1-Distill-Llama-70B-Q4_0.gguf
#Running model inference with llama.cpp cli
./llama-cli -m DeepSeek-R1-Distill-Llama-70B-Q4_0.gguf -p "Building a visually appealing website can be done in ten simple steps:/" -n 512 -t 64 -no-cnv上述脚本使用llama.cpp来部署模型。如果大家需要一个轻量级的、兼容OpenAI API的HTTP服务器来部署LLM服务,可以使用以下命令,将脚本中的llama-cli替换为llama-server:
#Running model inference with llama.cpp server
./llama-server -m DeepSeek-R1-Distill-Llama-70B-Q4_0.gguf —-host 0.0.0.0 —-port 8080如果大家不想将模型下载到本地,可以直接从Hugging Face仓库加载模型,只需修改llama-cli或llama-server命令,如下所示:
#Running model inference with llama.cpp cli
./llama-cli --hf-repo bartowski/DeepSeek-R1-Distill-Llama-70B-GGUF --hf-file DeepSeek-R1-Distill-Llama-70B-Q4_0.gguf "Building a visually appealing website can be done in ten simple steps:/" -n 512 -t 64 -no-cnv
性能与成本
我们使用llmperf在c8g.16xlarge EC2实例上对DeepSeek-R1-Distill-Llama-70B模型进行了基准测试,结果如下表所示:
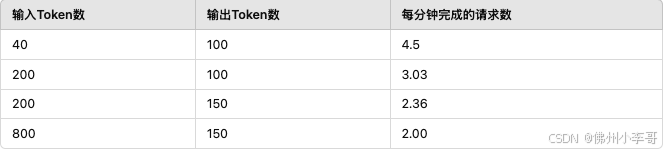
根据输入和输出的Token数,推理性能会有所不同。虽然上述性能的场景可能不能适用于实时应用(如聊天机器人),但对于日常批处理任务(如数据提取)仍然可以良好处理。例如在4.5次请求/分钟的情况下,每天可处理约6480次推理任务。如果每次推理对应于一个电子邮件数据提取任务,那么该模型每天可处理约6000封电子邮件的数据提取。
在北弗吉尼亚区域,运行c8g.16xlarge实例的计算成本(不包括存储和数据传输)如下:
- 按需(On-Demand)价格: 每月 $1,863
- 1年期无预付EC2 Savings Plan: 每月 $1,336
- 3年期全额预付EC2 Savings Plan: 每月 $819
大家可以访问EC2定价页面获取最新的价格信息。如果不需要始终运行EC2实例,可以使用Amazon EC2 Spot实例,最多可享受90%折扣。在北弗吉尼亚区域,c8g.16xlarge实例的Spot价格相比按需实例节省66%,且中断频率仅为5-10%。此外大家还可以使用EC2 Auto Scaling自动调整实例数量,在按需实例和Spot实例之间进行灵活配置,以优化系统方案成本与可用性。
总结
DeepSeek-R1和DeepSeek-R1 Distill蒸馏模型因其强大的推理能力而广受欢迎。虽然DeepSeek-R1 Distill模型可以在GPU或AI芯片上部署以获得最佳的低延迟和高吞吐性能,但在某些场景下,使用CPU可能提供更优的性价比。结合Amazon Graviton4和EC2 Savings Plan或Spot实例,可以在c8g.16xlarge EC2实例上部署DeepSeek-R1-Distill-Llama-70B,达到适用于批量推理任务计算性能水平。

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









