






摘要:我们推出了Step-Video-T2V,这是一个拥有300亿参数、能够生成长达204帧视频的先进文本到视频预训练模型。我们设计了一个深度压缩变分自编码器,即Video-VAE,专用于视频生成任务,实现了16x16的空间压缩比和8倍的时间压缩比,同时保持了卓越的视频重建质量。用户提示通过两个双语文本编码器进行编码,以处理英文和中文。我们采用流匹配方法训练了一个具有3D全局注意力的DiT(扩散变换器),用于将输入噪声去噪为潜在帧。此外,我们应用了一种基于视频的去伪影优化(DPO)方法,即Video-DPO,以减少伪影并提高生成视频的视觉质量。我们还详细介绍了我们的训练策略,并分享了关键观察和见解。Step-Video-T2V的性能在一个新的视频生成基准测试Step-Video-T2V-Eval上得到了评估,与开源和商业引擎相比,其文本到视频的质量达到了先进水平。此外,我们讨论了当前基于扩散的模型范式的局限性,并概述了视频基础模型的未来发展方向。Step-Video-T2V和Step-Video-T2V-Eval均可在https://github.com/stepfun-ai/Step-Video-T2V上获取。在线版本也可通过https://yuewen.cn/videos访问。我们的目标是加速视频基础模型的创新,并赋能视频内容创作者。Huggingface链接:Paper page,论文链接:2502.10248
一、引言
- 研究背景与意义:随着人工智能技术的不断发展,视频生成已成为一个重要的研究领域。视频基础模型,作为预先在大规模视频数据集上训练的模型,能够响应用户的文本、视觉或多模态输入来生成视频,具有广泛的应用前景。Step-Video-T2V作为先进的文本到视频预训练模型,其推出对于推动视频生成技术的发展具有重要意义。
- 模型概述:Step-Video-T2V是一个拥有300亿参数的预训练模型,能够生成长达204帧的视频。该模型采用了一系列创新技术,包括深度压缩变分自编码器(Video-VAE)、双语文本编码器、具有3D全局注意力的扩散变换器(DiT)以及基于视频的去伪影优化(Video-DPO)方法,以实现高效、高质量的视频生成。
二、模型架构与技术细节
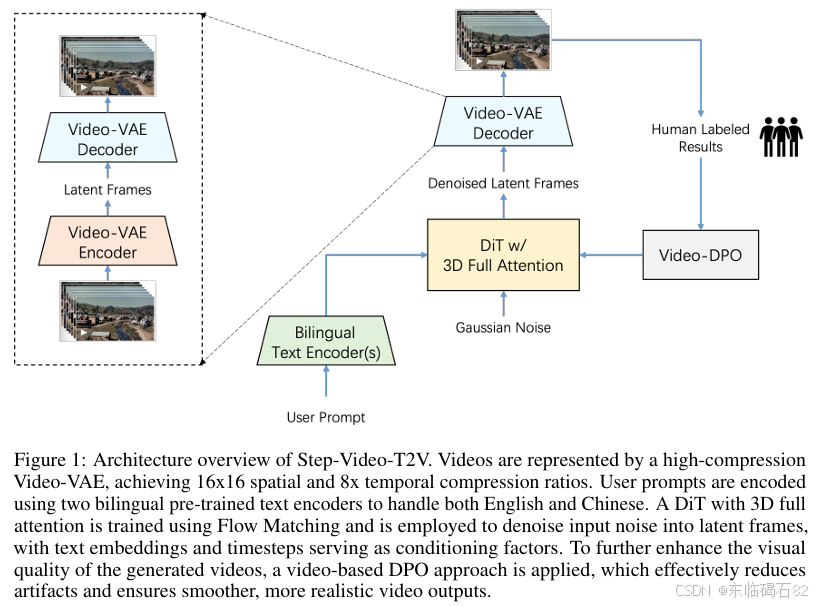
1. Video-VAE
- 设计目的:Video-VAE是为视频生成任务设计的深度压缩变分自编码器,旨在通过高效的压缩来加速训练和推理过程,同时保持卓越的视频重建质量。
- 压缩比与性能:该编码器实现了16x16的空间压缩比和8倍的时间压缩比,显著减少了视频数据的表示维度,从而降低了计算复杂度。实验结果表明,尽管压缩比很高,但Video-VAE仍然能够重建出高质量的视频。
- 架构创新:Video-VAE引入了新颖的双路径架构,在编码器的后期阶段和解码器的早期阶段实现了统一的时空压缩。通过结合3D卷积和优化后的像素重组操作,该编码器能够有效地处理视频数据。
2. 双语文本编码器
- 功能与作用:双语文本编码器用于处理用户输入的文本提示,支持英文和中文。该编码器由两个预训练的文本模型组成,能够生成鲁棒的文本表示,以有效引导视频生成过程。
- 模型选择:选用了Hunyuan-CLIP和Step-LLM两个模型。Hunyuan-CLIP是一个开源的双语CLIP模型,能够生成与视觉空间对齐良好的文本表示,但输入长度受限。而Step-LLM是一个内部开发的单向双语文本编码器,通过预测下一个令牌的任务进行预训练,没有输入长度限制。
3. 具有3D全局注意力的DiT
- 模型架构:DiT(扩散变换器)是基于Transformer架构的模型,具有48层,每层包含48个注意力头,每个头的维度为128。该模型采用3D全局注意力机制,能够同时捕捉视频中的空间和时间信息。
- 训练与优化:DiT通过流匹配方法进行训练,以最小化预测速度与真实速度之间的均方误差损失。在训练过程中,还采用了自适应层归一化(AdaLN)、查询-键归一化(QK-Norm)以及旋转位置编码(RoPE-3D)等技术来稳定训练过程并提高模型性能。
4. Video-DPO
- 方法概述:Video-DPO是一种基于视频的去伪影优化方法,通过引入人类反馈来微调模型,使生成的视频内容更符合人类期望。
- 实施流程:首先构建一个包含多种提示的数据集,然后邀请人类注释者根据提示生成视频样本,并对这些样本进行偏好评分。接着,使用这些偏好数据来训练模型,以提高生成视频的质量和一致性。
三、训练策略与实现细节
1. 级联训练策略
- 训练阶段:Step-Video-T2V的训练过程包括文本到图像(T2I)预训练、文本到视频/图像(T2VI)预训练、文本到视频(T2V)微调以及Video-DPO训练四个阶段。
- 数据利用:在T2I预训练阶段,模型首先在大规模图像数据集上进行训练,以建立对视觉概念的基础理解。随后,在T2VI预训练阶段,模型逐渐过渡到视频数据,学习运动相关的知识。最后,在T2V微调阶段,使用少量高质量的文本-视频对来进一步调整模型参数。
2. 数据预处理与增强
- 视频分割与评估:使用PySceneDetect工具包来识别视频中的场景变化,并使用FFmpeg将视频分割为单个镜头片段。然后,通过多个质量评估标签(如美学分数、NSFW分数、水印检测等)来过滤和选择高质量的视频片段。
- 视频运动评估:计算视频片段的光流平均值来评估其运动分数,以确保数据集中包含足够的运动内容,这对于训练有效的视频生成模型至关重要。
3. 并行化与分布式训练
- 并行化策略:为了高效利用计算资源,Step-Video-T2V的训练过程采用了多种并行化策略,包括张量并行化(TP)、序列并行化(SP)、上下文并行化(CP)以及管道并行化(PP)等。
- 训练框架优化:开发了StepEmulator模拟器来估计不同模型架构和并行化配置下的资源消耗和端到端性能。此外,还实现了StepCCL集体通信库和StepRPC高性能通信框架,以优化跨集群的数据传输和通信性能。
四、性能评估与比较
1. Step-Video-T2V-Eval基准测试
- 基准测试概述:为了评估Step-Video-T2V的性能,我们构建了一个新的视频生成基准测试Step-Video-T2V-Eval。该基准测试包含128个来自真实用户的中文提示,涵盖了11个不同的类别。
- 评估指标:提出了两种人类评估指标,即Win/Tie/Loss标签和四个维度的质量评分(指令遵循性、运动平滑性、物理合理性和美学吸引力)。
2. 与开源模型的比较
- 与HunyuanVideo的比较:在Step-Video-T2V-Eval基准测试上,Step-Video-T2V在整体性能上优于HunyuanVideo,尤其是在运动动态建模和生成能力方面。然而,在美学吸引力方面,HunyuanVideo表现更佳,这可能是由于其生成的视频分辨率更高。
- 与其他开源模型的比较:与Open-Sora、Open-Sora-Plan等开源模型相比,Step-Video-T2V在模型规模、压缩比、双语支持以及DPO方法等方面具有显著优势。
3. 与商业引擎的比较
- 与T2VTopA和T2VTopB的比较:在Step-Video-T2V-Eval基准测试上,Step-Video-T2V在整体排名上位于T2VTopA和T2VTopB之间。然而,在运动动态建模和生成方面,Step-Video-T2V表现出色,甚至在某些类别上超过了T2VTopA和T2VTopB。
- 分析与讨论:分析了Step-Video-T2V在某些类别上表现不佳的原因,并提出了未来的改进方向,如增加高质量的训练数据、优化模型架构等。
五、挑战与未来工作
1. 当前挑战
- 高质量标注数据的缺乏:现有视频标注模型仍存在幻觉问题,导致训练不稳定且指令遵循性能不佳。同时,人工标注成本高昂且难以扩展。
- 复杂动作序列的生成:即使像Step-Video-T2V这样的大规模模型,在生成涉及复杂动作序列的视频时仍面临困难。
- 物理定律的遵循:当前基于扩散的模型在生成遵循物理定律的视频方面存在局限性,如物体运动、碰撞效果等。
2. 未来工作
- 数据收集与标注:计划构建一个包含结构化标签的综合视频知识库,以支持更高效的视频生成模型训练。
- 模型架构与训练方法的改进:将探索结合自回归和扩散模型的统一框架,以提高模型对复杂动作序列和物理定律的遵循能力。
- 优化与加速:将继续优化模型架构和训练方法,以提高训练效率和生成速度,同时保持生成视频的高质量。
六、结论
Step-Video-T2V是一个先进的文本到视频预训练模型,具有高效的压缩机制、双语文本支持、3D全局注意力机制以及基于视频的去伪影优化方法。通过详细的训练策略和性能评估,我们展示了Step-Video-T2V在视频生成任务上的出色表现。然而,当前模型仍存在一些挑战,如高质量标注数据的缺乏、复杂动作序列的生成以及物理定律的遵循等。在未来的工作中,我们将致力于解决这些问题,并推动视频基础模型的进一步发展。我们的目标是加速视频基础模型的创新,并赋能视频内容创作者。

















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









