







https://blog.csdn.net/m0_67184231/article/details/140252553
2.8 手写数字识别之训练调试与优化
第2.7节我们研究了资源部署优化的方法,通过使用单GPU和分布式部署,提升模型训练的效率。本节我们依旧横向展开"横纵式",如 图1 所示,探讨在手写数字识别任务中,为了保证模型的真实效果,在模型训练部分,对模型进行一些调试和优化的方法
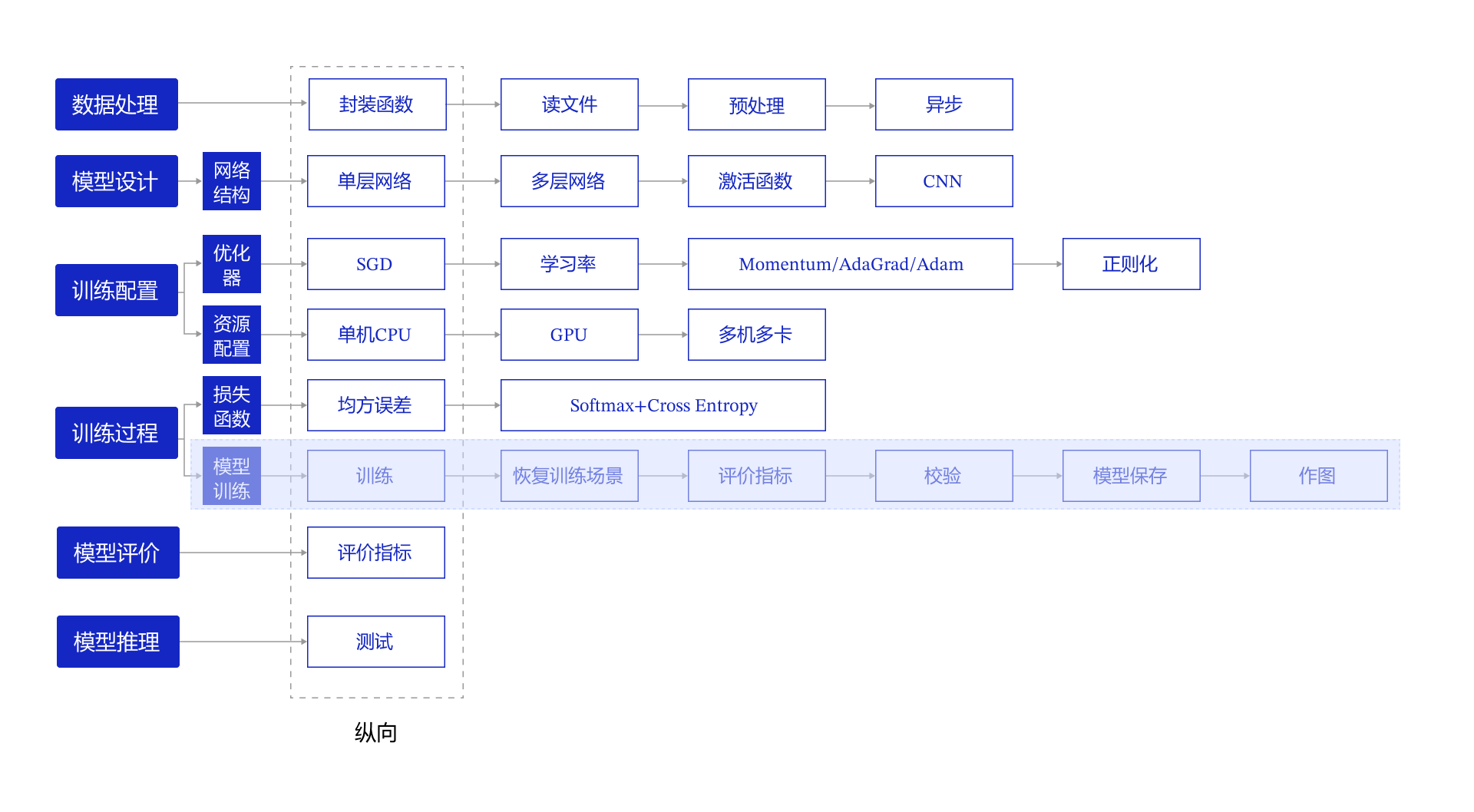
图1:“横纵式”教学法 — 训练过程
训练过程优化思路主要有如下五个关键环节:
(1)计算分类准确率,观测模型训练效果
交叉熵损失函数只能作为优化目标,无法直接准确衡量模型的训练效果。准确率可以直接衡量训练效果,但由于其离散性质,不适合做为损失函数优化神经网络。
(2)检查模型训练过程,识别潜在问题
如果模型的损失或者评估指标表现异常,通常需要打印模型每一层的输入和输出来定位问题,分析每一层的内容来获取错误的原因。
(3)加入校验或测试,更好评价模型效果
理想的模型训练结果是在训练集和验证集上均有较高的准确率,如果训练集的准确率低于验证集,说明网络训练程度不够;如果训练集的准确率高于验证集,可能是发生了过拟合现象。通过在优化目标中加入正则化项的办法,解决过拟合的问题。
(4)加入正则化项,避免模型过拟合
飞桨框架支持为整体参数加入正则化项,这是通常的做法。此外,飞桨框架也支持为某一层或某一部分的网络单独加入正则化项,以达到精细调整参数训练的效果。
(5)可视化分析
用户不仅可以通过打印或使用matplotlib库作图,飞桨还提供了更专业的可视化分析工具VisualDL,提供便捷的可视化分析方法 。
2.8.1 计算模型的分类准确率
准确率是一个直观衡量分类模型效果的指标,由于这个指标是离散的,因此不适合作为损失来优化。通常情况下,交叉熵损失越小的模型,分类的准确率也越高。基于分类准确率,我们可以公平地比较两种损失函数的优劣,例如在【手写数字识别】之损失函数章节中均方误差和交叉熵的比较。
使用飞桨提供的计算分类准确率API,可以直接计算准确率。
class paddle.metric.Accuracy
该API的输入参数input为预测的分类结果predict,输入参数label为数据真实的label。飞桨还提供了更多衡量模型效果的计算指标,详细可以查看paddle.meric包下面的API。
在下述代码中,我们在模型前向计算过程forward函数中计算分类准确率,并在训练时打印每个批次样本的分类准确率。
In [ ]
import paddle
from data_process import get_MNIST_dataloader
train_loader, test_loader = get_MNIST_dataloader()In [ ]
# 定义模型结构import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear
# 多层卷积神经网络实现classMNIST(paddle.nn.Layer):def__init__(self):super(MNIST, self).__init__()
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 定义一层全连接层,输出维度是10
self.fc = Linear(in_features=980, out_features=10)
# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出# 卷积层激活函数使用Relu,全连接层激活函数使用softmaxdefforward(self, inputs, label):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.reshape(x, [x.shape[0], 980])
x = self.fc(x)
if label isnotNone:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
#在使用GPU机器时,可以将use_gpu变量设置成True
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
#仅优化算法的设置有所差别deftrain(model):
model = MNIST()
model.train()
#四种优化算法的设置方案,可以逐一尝试效果# opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())
opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 5for epoch_id inrange(EPOCH_NUM):
for batch_id, data inenumerate(train_loader()):
#准备数据
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
#前向计算的过程
predicts, acc = model(images, labels)
#计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(), acc.numpy()))
#后向传播,更新参数,消除梯度的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
#保存模型参数
paddle.save(model.state_dict(), 'mnist.pdparams')
#创建模型
model = MNIST()
#启动训练过程
train(model)W0905 14:35:13.571403 98 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0905 14:35:13.574612 98 device_context.cc:465] device: 0, cuDNN Version: 8.2.
epoch: 0, batch: 0, loss is: [3.8877463], acc is [0.09375]
epoch: 0, batch: 200, loss is: [0.205946], acc is [0.921875]
epoch: 0, batch: 400, loss is: [0.01945284], acc is [1.]
epoch: 0, batch: 600, loss is: [0.0915114], acc is [0.96875]
epoch: 0, batch: 800, loss is: [0.07086004], acc is [0.984375]
epoch: 4, batch: 0, loss is: [0.10021097], acc is [0.96875]
epoch: 4, batch: 200, loss is: [0.04378257], acc is [0.984375]
epoch: 4, batch: 400, loss is: [0.02809021], acc is [0.984375]
epoch: 4, batch: 600, loss is: [0.04106805], acc is [0.984375]
epoch: 4, batch: 800, loss is: [0.01189358], acc is [1.]
2.8.2 检查模型训练过程,识别潜在训练问题
使用飞桨动态图编程可以方便的查看和调试训练的执行过程。在网络定义的Forward函数中,可以打印每一层输入输出的尺寸,以及每层网络的参数。通过查看这些信息,不仅可以更好地理解训练的执行过程,还可以发现潜在问题,或者启发继续优化的思路。
在下述程序中,使用check_shape变量控制是否打印“尺寸”,验证网络结构是否正确。使用check_content变量控制是否打印“内容值”,验证数据分布是否合理。假如在训练中发现中间层的部分输出持续为0,说明该部分的网络结构设计存在问题,没有充分利用。
In [ ]
import numpy as np
import paddle.nn.functional as F
# 定义模型结构classMNIST(paddle.nn.Layer):def__init__(self):super(MNIST, self).__init__()
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2
self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)
# 定义池化层,池化核的大小kernel_size为2,池化步长为2
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 定义一层全连接层,输出维度是10
self.fc = Linear(in_features=980, out_features=10)
#加入对每一层输入和输出的尺寸和数据内容的打印,根据check参数决策是否打印每层的参数和输出尺寸# 卷积层激活函数使用Relu,全连接层激活函数使用softmaxdefforward(self, inputs, label=None, check_shape=False, check_content=False):# 给不同层的输出不同命名,方便调试
outputs1 = self.conv1(inputs)
outputs2 = F.relu(outputs1)
outputs3 = self.max_pool1(outputs2)
outputs4 = self.conv2(outputs3)
outputs5 = F.relu(outputs4)
outputs6 = self.max_pool2(outputs5)
outputs6 = paddle.reshape(outputs6, [outputs6.shape[0], -1])
outputs7 = self.fc(outputs6)
# 选择是否打印神经网络每层的参数尺寸和输出尺寸,验证网络结构是否设置正确if check_shape:
# 打印每层网络设置的超参数-卷积核尺寸,卷积步长,卷积padding,池化核尺寸print("\n########## print network layer's superparams ##############")
print("conv1-- kernel_size:{}, padding:{}, stride:{}".format(self.conv1.weight.shape, self.conv1._padding, self.conv1._stride))
print("conv2-- kernel_size:{}, padding:{}, stride:{}".format(self.conv2.weight.shape, self.conv2._padding, self.conv2._stride))
#print("max_pool1-- kernel_size:{}, padding:{}, stride:{}".format(self.max_pool1.pool_size, self.max_pool1.pool_stride, self.max_pool1._stride))#print("max_pool2-- kernel_size:{}, padding:{}, stride:{}".format(self.max_pool2.weight.shape, self.max_pool2._padding, self.max_pool2._stride))print("fc-- weight_size:{}, bias_size_{}".format(self.fc.weight.shape, self.fc.bias.shape))
# 打印每层的输出尺寸print("\n########## print shape of features of every layer ###############")
print("inputs_shape: {}".format(inputs.shape))
print("outputs1_shape: {}".format(outputs1.shape))
print("outputs2_shape: {}".format(outputs2.shape))
print("outputs3_shape: {}".format(outputs3.shape))
print("outputs4_shape: {}".format(outputs4.shape))
print("outputs5_shape: {}".format(outputs5.shape))
print("outputs6_shape: {}".format(outputs6.shape))
print("outputs7_shape: {}".format(outputs7.shape))
# print("outputs8_shape: {}".format(outputs8.shape))# 选择是否打印训练过程中的参数和输出内容,可用于训练过程中的调试if check_content:
# 打印卷积层的参数-卷积核权重,权重参数较多,此处只打印部分参数print("\n########## print convolution layer's kernel ###############")
print("conv1 params -- kernel weights:", self.conv1.weight[0][0])
print("conv2 params -- kernel weights:", self.conv2.weight[0][0])
# 创建随机数,随机打印某一个通道的输出值
idx1 = np.random.randint(0, outputs1.shape[1])
idx2 = np.random.randint(0, outputs4.shape[1])
# 打印卷积-池化后的结果,仅打印batch中第一个图像对应的特征print("\nThe {}th channel of conv1 layer: ".format(idx1), outputs1[0][idx1])
print("The {}th channel of conv2 layer: ".format(idx2), outputs4[0][idx2])
print("The output of last layer:", outputs7[0], '\n')
# 如果label不是None,则计算分类精度并返回if label isnotNone:
acc = paddle.metric.accuracy(input=F.softmax(outputs7), label=label)
return outputs7, acc
else:
return outputs7
#在使用GPU机器时,可以将use_gpu变量设置成True
use_gpu = True
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
deftrain(model):
model = MNIST()
model.train()
#四种优化算法的设置方案,可以逐一尝试效果
opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())# opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())
EPOCH_NUM = 1for epoch_id inrange(EPOCH_NUM):
for batch_id, data inenumerate(train_loader()):
#准备数据,变得更加简洁
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
#前向计算的过程,同时拿到模型输出值和分类准确率if batch_id == 0and epoch_id==0:
# 打印模型参数和每层输出的尺寸
predicts, acc = model(images, labels, check_shape=True, check_content=False)
elif batch_id==401:
# 打印模型参数和每层输出的值
predicts, acc = model(images, labels, check_shape=False, check_content=True)
else:
predicts, acc = model(images, labels)
#计算损失,取一个批次样本损失的平均值
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(), acc.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
opt.step()
opt.clear_grad()
#保存模型参数
paddle.save(model.state_dict(), 'mnist_test.pdparams')
#创建模型
model = MNIST()
#启动训练过程
train(model)
print("Model has been saved.")########## print network layer's superparams ##############
conv1-- kernel_size:[20, 1, 5, 5], padding:2, stride:[1, 1]
conv2-- kernel_size:[20, 20, 5, 5], padding:2, stride:[1, 1]
fc-- weight_size:[980, 10], bias_size_[10]
########## print shape of features of every layer ###############
inputs_shape: [64, 1, 28, 28]
outputs1_shape: [64, 20, 28, 28]
outputs2_shape: [64, 20, 28, 28]
outputs3_shape: [64, 20, 14, 14]
outputs4_shape: [64, 20, 14, 14]
outputs5_shape: [64, 20, 14, 14]
outputs6_shape: [64, 980]
outputs7_shape: [64, 10]
epoch: 0, batch: 0, loss is: [3.1953034], acc is [0.109375]
epoch: 0, batch: 200, loss is: [0.37904966], acc is [0.875]
epoch: 0, batch: 400, loss is: [0.16234186], acc is [0.984375]
########## print convolution layer's kernel ###############
conv1 params -- kernel weights: Tensor(shape=[5, 5], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[-0.06305157, -0.24847564, -0.63125026, 0.16255459, 0.05321766],
[ 0.27163783, 0.03359267, -0.16793424, -0.33206284, 0.24191348],
[-0.01796198, 0.59920996, -0.19074094, 0.30350232, -0.13594414],
[-0.17397462, -0.28396046, 0.37263221, -0.46014515, 0.00446801],
[-0.34503123, 0.21267484, 0.12081132, 0.25961810, -0.29448596]])
conv2 params -- kernel weights: Tensor(shape=[5, 5], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[ 0.11260822, 0.07491580, -0.00697492, 0.03264738, -0.02312732],
[-0.13066202, -0.02998639, 0.01296079, 0.07414430, -0.07227730],
[ 0.00029436, 0.01291541, 0.06429236, 0.09252947, -0.00228186],
[-0.04436536, -0.02769227, -0.03541787, -0.04839976, 0.00429312],
[ 0.11987270, -0.00784257, -0.12884265, 0.03420701, 0.04363669]])
2.8.3 加入校验或测试,更好评价模型效果
在训练过程中,我们会发现模型在训练样本集上的损失在不断减小。但这是否代表模型在未来的应用场景上依然有效?为了验证模型的有效性,通常将样本集合分成三份,训练集、校验集和测试集。
- 训练集 :用于训练模型的参数,即训练过程中主要完成的工作。
- 验证集 :用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。
- 测试集 :用于模拟模型在应用后的真实效果。因为测试集没有参与任何模型优化或参数训练的工作,所以它对模型来说是完全未知的样本。在不以校验数据优化网络结构或模型超参数时,校验数据和测试数据的效果是类似的,均更真实的反映模型效果。
如下程序读取上一步训练保存的模型参数,读取校验数据集,并测试模型在校验数据集上的效果。
In [ ]
defevaluation(model):print('start evaluation .......')
# 定义预测过程
params_file_path = 'mnist.pdparams'# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
eval_loader = test_loader
acc_set = []
avg_loss_set = []
for batch_id, data inenumerate(eval_loader()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
predicts, acc = model(images, labels)
loss = F.cross_entropy(input=predicts, label=labels)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
#计算多个batch的平均损失和准确率
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
model = MNIST()
evaluation(model)start evaluation .......
loss=0.06925583740963806, acc=0.9796974522292994
从测试的效果来看,模型在验证集上依然有98.6%的准确率,证明它是有预测效果的。

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











