







4.3 图像分类ResNet实战:眼疾识别
基本的计算机视觉任务研发全流程如图1所示:
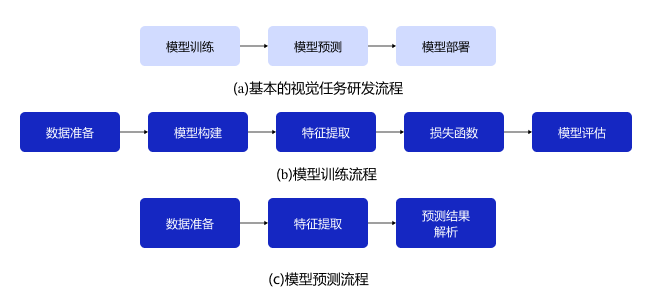
图1:基本的计算机视觉任务研发全流程
其中,基本的计算机视觉任务研发全流程包含模型训练、模型预测和模型部署三大步骤。每个步骤又包含单独的流程:
- 数据准备:根据网络接收的数据格式,完成相应的预处理和跑批量数据读取器操作,保证模型正常读取;
- 模型构建:设计卷积网络结构;
- 特征提取:使用构建的模型提取数据的特征信息;
- 损失函数:通过损失函数衡量模型的预测值和真实值的不一致程度,通常损失函数越小,模型性能越好;
- 模型评估:在模型训练中或训练结束后,对模型进行评估测试,观察准确率;
- 模型预测:使用训练好的模型进行测试,也需要准备数据和模型特征提取,最后对结果进行解析。
4.3.1 数据处理
4.3.1.1 数据集介绍
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。iChallenge-PM分为2类:病理性近视和非病理性近视(包含高度近视和正常眼睛),数据集命名规则如下:
- 病理性近视(PM):文件名以P开头
- 非病理性近视(non-PM):
- 高度近视(high myopia):文件名以H开头
- 正常眼睛(normal):文件名以N开头
有监督图像分类任务的数据包含图片和对应的类别标签(如猫、狗等),我们将病理性患者的图片作为正样本,标签为1; 非病理性患者的图片作为负样本,标签为0。iChallenge-PM数据集的示意如图2所示。
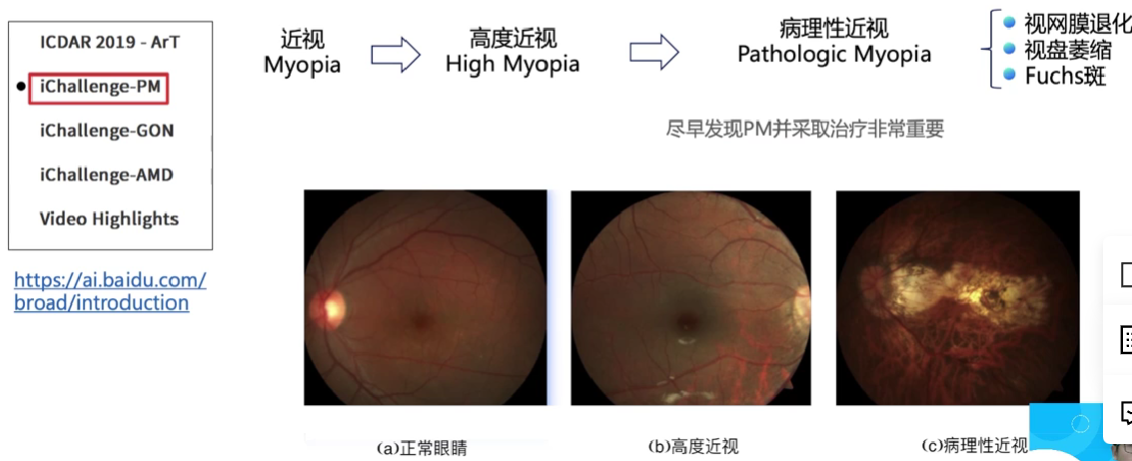
图2:iChallenge-PM数据集示例
4.3.1.2 数据集下载
AIStudio项目包含了iChallenge-PM数据集,位于/home/aistudio/data/data19065目录,包括如下三个文件:
- training.zip:训练中的图片和标签
- validation.zip:验证集的图片
- valid_gt.zip:验证集的标签
通过如下命令解压数据集(执行一次即可),解压缩后存放在/home/aistudio/work/palm目录下:
注意:
valid_gt.zip文件解压缩之后,需要将“/home/aistudio/work/palm/PALM-Validation-GT/”目录下的“PM_Label_and_Fovea_Location.xlsx”文件转存成.csv格式,本节代码示例中已经提前转成文件labels.csv。
# 如果已经解压过,不需要运行此段代码,否则由于文件已经存在,解压时会报错
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/training.zip
%cd /home/aistudio/work/palm/PALM-Training400/
!unzip -o -q PALM-Training400.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/validation.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/valid_gt.zip
#返回家目录,生成模型文件位于/home/aistudio/
%cd /home/aistudio//home/aistudio/work/palm/PALM-Training400
/home/aistudio
从数据集中选取两张图片,并将图片显示出来。代码如下所示:
import os
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
# 文件名以N开头的是正常眼底图片,以P开头的是病变眼底图片
file1 = 'N0012.jpg'
file2 = 'P0095.jpg'
# 读取图片
img1 = Image.open(os.path.join(DATADIR, file1))
img1 = np.array(img1)
img2 = Image.open(os.path.join(DATADIR, file2))
img2 = np.array(img2)
# 画出读取的图片
plt.figure(figsize=(16, 8))
f = plt.subplot(121)
f.set_title('Normal', fontsize=20)
plt.imshow(img1)
f = plt.subplot(122)
f.set_title('PM', fontsize=20)
plt.imshow(img2)
plt.show()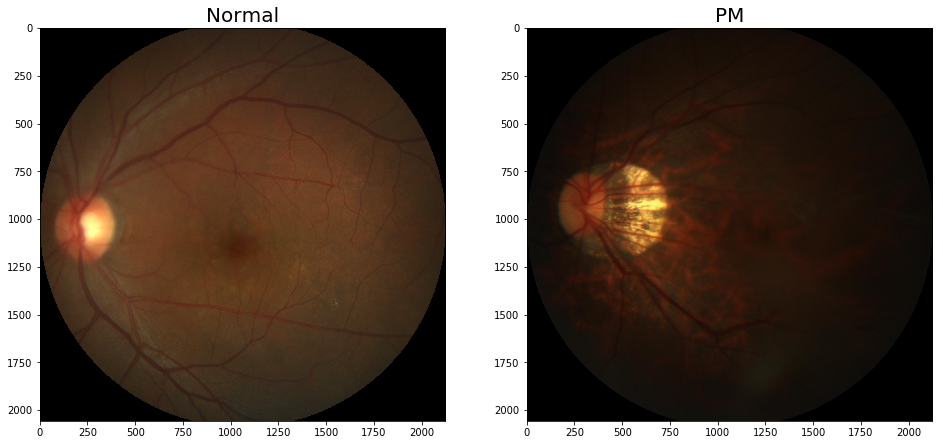
<Figure size 1152x576 with 2 Axes>
In [ ]
# 查看图片形状
img1.shape, img2.shape((2056, 2124, 3), (2056, 2124, 3))
4.3.1.3 数据预处理
图像分类网络对输入图片的格式、大小有一定的要求,数据灌入模型前,需要对数据进行预处理操作,使图片满足网络训练以及预测的需要。本实验主要应用了如下方法:
- 调整图片大小:将每张图缩放到 224 × 224大小 ,统一大小训练速度更快
- 归一化:将像素值调整到[-1, 1] 之间 ,效果更好
代码如下所示:
import cv2
import numpy as np
# 对读入的图像数据进行预处理
def transform_img(img):
# 将图片尺寸缩放道 224x224
img = cv2.resize(img, (224, 224))
# 读入的图像数据格式是[H, W, C]
# 使用转置操作将其变成[C, H, W]
img = np.transpose(img, (2,0,1))
img = img.astype('float32')
# 将数据范围调整到[-1.0, 1.0]之间
img = img / 255.
img = img * 2.0 - 1.0
return img4.1.1.4 定义数据读取器
上面的代码仅展示了读取一张图片和预处理的方法,但在真实场景的模型训练与评估过程中,通常会使用批量数据读取和预处理的方式。

In [3]
import cv2
import random
import numpy as np
import os
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 将datadir目录下的文件列出来,每条文件都要读入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 训练时随机打乱数据顺序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H开头的文件名表示高度近似,N开头的文件名表示正常视力
# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0
label = 0
elif name[0] == 'P':
# P开头的是病理性近视,属于正样本,标签为1
label = 1
else:
raise('Not excepted file name')
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签
# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容
# csvfile文件所包含的内容格式如下,每一行代表一个样本,
# 其中第一列是图片id,第二列是文件名,第三列是图片标签,
# 第四列和第五列是Fovea的坐标,与分类任务无关
# ID,imgName,Label,Fovea_X,Fovea_Y
# 1,V0001.jpg,0,1157.74,1019.87
# 2,V0002.jpg,1,1285.82,1080.47
# 打开包含验证集标签的csvfile,并读入其中的内容
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',')
name = line[1]
label = int(line[2])
# 根据图片文件名加载图片,并对图像数据作预处理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).reshape(-1, 1)
yield imgs_array, labels_array
return reader
In [6]
import paddle
paddle.seed(100)
# 查看数据形状
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
train_loader = data_loader(DATADIR,
batch_size=10, mode='train')
data_reader = train_loader()
data = next(data_reader)
data[0].shape, data[1].shape
eval_loader = data_loader(DATADIR,
batch_size=10, mode='eval')
data_reader = eval_loader()
data = next(data_reader)
data[0].shape, data[1].shape((10, 3, 224, 224), (10, 1))



















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











