







5.3 目标检测YOLOv3实战:叶病虫害检测
基本的计算机视觉任务研发全流程
首先简单回顾下第四章介绍的基本的计算机视觉任务研发全流程:
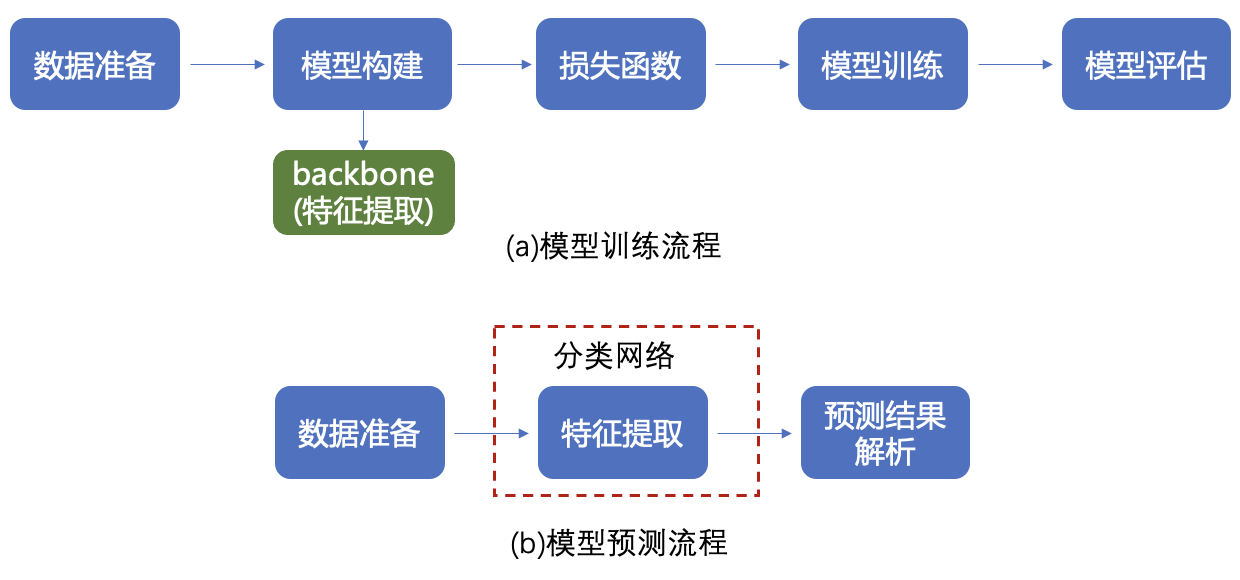
图1:基本的视觉任务研发全流程
通用的视觉任务研发全流程
目标检测模型构建流程如图2所示,和基本的计算机视觉任务研发全流程(图1)相比增加了检测头结构和多尺度检测结构2部分。
目标检测既需要识别出物体的类别,还需要标示出每个目标的位置,因此我们增加检测头结构,用于计算预测框是否包含物体的概率、预测框位置坐标以及物体属于每个类别的概率。
同时在目标检测中,检测的物体形状尺寸可能变化比较大,使用单一尺寸的特征图做预测容易造成漏检,而且像素点包含的语义信息可能不够丰富,难以提取到有效的特征模式,因此在目标检测中将高级层的特征图尺寸放大之后跟低层级的特征图进行融合,从而检测多尺度目标。
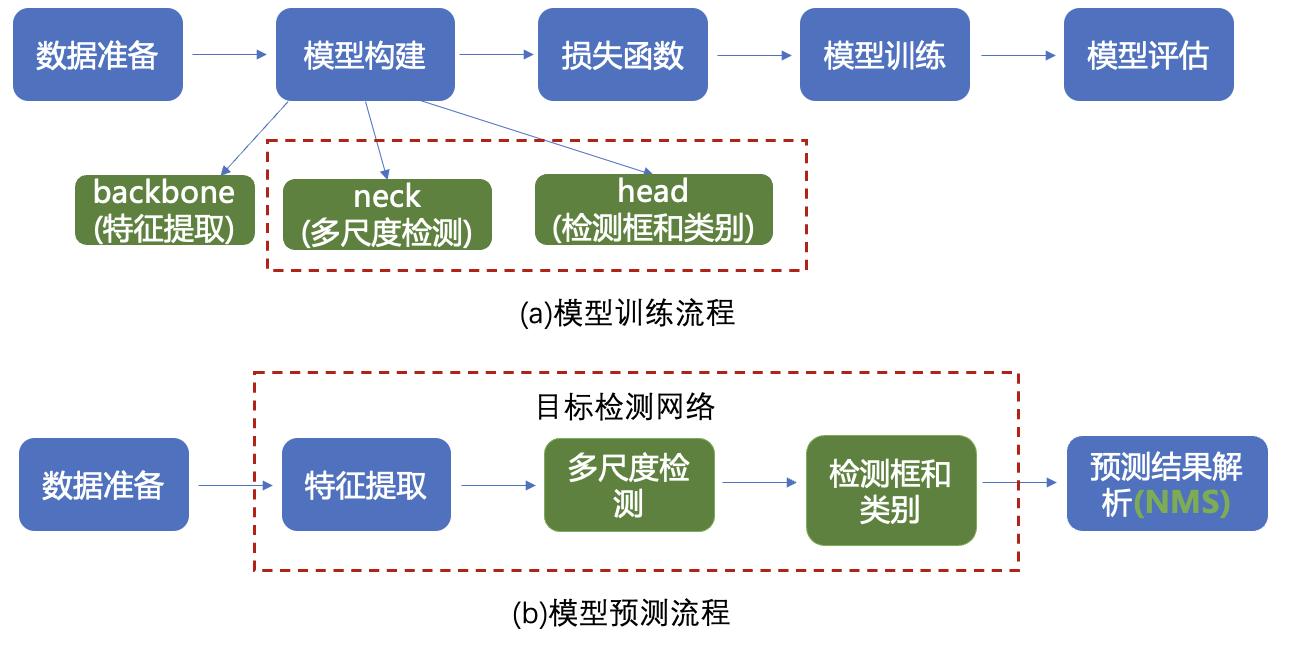
图2:通用的视觉任务研发全流程
- 数据处理:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取,同时产生候选区域;
- 模型构建:设计目标检测网络结构;
- 特征提取:使用卷积神经网络提取特征;
- 检测头设计:计算预测框是否包含物体的概率、预测框位置坐标、物体属于每个类别概率;
- 多尺度检测:将高级层的特征图尺寸放大之后跟低层级的特征图进行融合;
- 损失函数:模型优化的目标;
- 模型评估:在模型训练中或训练结束后岁模型进行评估测试,观察准确率;
- 模型预测:使用训练好的模型进行测试,也需要准备数据和模型特征提取,最后对结果进行解析;
- 模型部署:通常需要将训练好的模型在特定环境(服务器、手机等)中运行,即在设备端运行推理任务。
接下来具体介绍流程中各节点的原理和代码实现。
5.3.1 数据处理
5.3.1.1 数据集介绍
在本课程中,将使用百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集。AI识虫数据集结构如下:
- 提供了2183张图片,其中训练集1693张,验证集245,测试集245张。
- 包含7种昆虫,分别是Boerner、Leconte、Linnaeus、acuminatus、armandi、coleoptera和linnaeus。
- 包含了图片和标注
5.3.1.2 数据集下载和标签格式
请读者先将数据解压,并存放在insects目录下。
# 解压数据脚本,第一次运行时打开注释,将文件解压到work目录下
!unzip -q -d /home/aistudio/work /home/aistudio/data/data19638/insects.zip将数据解压之后,可以看到insects目录下的结构如下所示。
insects
|---train
| |---annotations
| | |---xmls
| | |---100.xml
| | |---101.xml
| | |---...
| |---images
| |---100.jpeg
| |---101.jpeg
| |---...
|---val
| |---annotations
| | |---xmls
| | |---1221.xml
| | |---1277.xml
| | |---...
| |---images
| |---1221.jpeg
| |---1277.jpeg
| |---...
|---test
|---images
|---1833.jpeg
|---1838.jpeg
|---...
insects包含train、val和test三个文件夹。train/annotations/xmls目录下存放着图片的标注。每个xml文件是对一张图片的说明,包括图片尺寸、包含的昆虫名称、在图片上出现的位置等信息。
第四章介绍的分类数据集包含图片和标注信息(物体类别),目标检测的数据比分类复杂,一张图像中,需要标记出各个目标区域的位置和类别。
一般的目标区域位置用一个矩形框来表示,一般用以下3种方式表达:
| 表达方式 | 说明 |
| x1,y1,x2,y2 | (x1,y1)为左上角坐标,(x2,y2)为右下角坐标 |
| x1,y1,w,h | (x1,y1)为左上角坐标,w为目标区域宽度,h为目标区域高度 |
| xc,yc,w,h | (xc,yc)为目标区域中心坐标,w为目标区域宽度,h为目标区域高度 |
常见的目标检测数据集如Pascal VOC采用的[x1,y1,x2,y2]表示物体的bounding box, COCO采用的[x1,y1,w,h]表示物体的bounding box,Cformat.
<annotation>
<folder>刘霏霏</folder>
<filename>100.jpeg</filename>
<path>/home/fion/桌面/刘霏霏/100.jpeg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1336</width>
<height>1336</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Boerner</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>500</xmin>
<ymin>893</ymin>
<xmax>656</xmax>
<ymax>966</ymax>
</bndbox>
</object>
<object>
...
</object>
...
</annotation>上面列出的xml文件中的主要参数说明如下:
- size:图片尺寸。
- object:图片中包含的物体,一张图片可能中包含多个物体。
-- name:昆虫名称;
-- bndbox:物体真实框;
-- difficult:识别是否困难。
下面我们将从数据集中读取xml文件,将每张图片的标注信息读取出来。在读取具体的标注文件之前,我们先完成一件事情,就是将昆虫的类别名字(字符串)转化成数字表示的类别。因为神经网络里面计算时需要的输入类型是数值型的,所以需要将字符串表示的类别转化成具体的数字。昆虫类别名称的列表是:['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus'],这里我们约定此列表中:'Boerner'对应类别0,'Leconte'对应类别1,...,'linnaeus'对应类别6。使用下面的程序可以得到表示名称字符串和数字类别之间映射关系的字典。
In [ ]
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus',
'acuminatus', 'armandi', 'coleoptera', 'linnaeus']
def get_insect_names():
"""
return a dict, as following,
{'Boerner': 0,
'Leconte': 1,
'Linnaeus': 2,
'acuminatus': 3,
'armandi': 4,
'coleoptera': 5,
'linnaeus': 6
}
It can map the insect name into an integer label.
"""
insect_category2id = {}
for i, item in enumerate(INSECT_NAMES):
insect_category2id[item] = i
return insect_category2idIn [ ]
cname2cid = get_insect_names()
cname2cid{'Boerner': 0,
'Leconte': 1,
'Linnaeus': 2,
'acuminatus': 3,
'armandi': 4,
'coleoptera': 5,
'linnaeus': 6}
调用get_insect_names函数返回一个dict,描述了昆虫名称和数字类别之间的映射关系。下面的程序从annotations/xml目录下面读取所有文件标注信息。
import os
import numpy as np
import xml.etree.ElementTree as ET
def get_annotations(cname2cid, datadir):
filenames = os.listdir(os.path.join(datadir, 'annotations', 'xmls'))
records = []
ct = 0
for fname in filenames:
fid = fname.split('.')[0]
fpath = os.path.join(datadir, 'annotations', 'xmls', fname)
img_file = os.path.join(datadir, 'images', fid + '.jpeg')
tree = ET.parse(fpath)
if tree.find('id') is None:
im_id = np.array([ct])
else:
im_id = np.array([int(tree.find('id').text)])
objs = tree.findall('object')
im_w = float(tree.find('size').find('width').text)
im_h = float(tree.find('size').find('height').text)
gt_bbox = np.zeros((len(objs), 4), dtype=np.float32)
gt_class = np.zeros((len(objs), ), dtype=np.int32)
is_crowd = np.zeros((len(objs), ), dtype=np.int32)
difficult = np.zeros((len(objs), ), dtype=np.int32)
for i, obj in enumerate(objs):
cname = obj.find('name').text
gt_class[i] = cname2cid[cname]
_difficult = int(obj.find('difficult').text)
x1 = float(obj.find('bndbox').find('xmin').text)
y1 = float(obj.find('bndbox').find('ymin').text)
x2 = float(obj.find('bndbox').find('xmax').text)
y2 = float(obj.find('bndbox').find('ymax').text)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(im_w - 1, x2)
y2 = min(im_h - 1, y2)
# 这里使用xywh格式来表示目标物体真实框
gt_bbox[i] = [(x1+x2)/2.0 , (y1+y2)/2.0, x2-x1+1., y2-y1+1.]
is_crowd[i] = 0
difficult[i] = _difficult
voc_rec = {
'im_file': img_file,
'im_id': im_id,
'h': im_h,
'w': im_w,
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': [],
'difficult': difficult
}
if len(objs) != 0:
records.append(voc_rec)
ct += 1
return recordsTRAINDIR = '/home/aistudio/work/insects/train'
TESTDIR = '/home/aistudio/work/insects/test'
VALIDDIR = '/home/aistudio/work/insects/val'
cname2cid = get_insect_names()
records = get_annotations(cname2cid, TRAINDIR)
print('records num:{}\n recored[0]:{}'.format(len(records), records[0]))records num:1693
recored[0]:{'im_file': '/home/aistudio/work/insects/train/images/493.jpeg', 'im_id': array([0]), 'h': 1258.0, 'w': 1258.0, 'is_crowd': array([0, 0, 0, 0, 0], dtype=int32), 'gt_class': array([0, 1, 5, 2, 4], dtype=int32), 'gt_bbox': array([[503. , 701.5, 71. , 152. ],
[820.5, 603. , 116. , 119. ],
[644. , 447. , 75. , 43. ],
[695.5, 749. , 50. , 99. ],
[532. , 524.5, 63. , 98. ]], dtype=float32), 'gt_poly': [], 'difficult': array([0, 0, 0, 0, 0], dtype=int32)}
通过上面的程序,将所有训练数据集的标注数据全部读取出来了,存放在records列表下面,其中每一个元素是一张图片的标注数据,包含了图片存放地址,图片id,图片高度和宽度,图片中所包含的目标物体的种类和位置。
5.3.1.3 数据预处理
数据预处理是训练神经网络时非常重要的步骤。合适的预处理方法,可以帮助模型更好的收敛并防止过拟合。然后需要对这些数据进行预处理,为了保证网络运行的速度,通常还要对数据预处理进行加速。
首先我们需要从磁盘读入数据,前面已经将图片的所有描述信息保存在records中了,其中每一个元素都包含了一张图片的描述,下面的程序展示了如何根据records里面的描述读取图片及标注。
# 数据读取
import cv2
def get_bbox(gt_bbox, gt_class):
# 对于一般的检测任务来说,一张图片上往往会有多个目标物体
# 设置参数MAX_NUM = 50, 即一张图片最多取50个真实框;如果真实
# 框的数目少于50个,则将不足部分的gt_bbox, gt_class和gt_score的各项数值全设置为0
MAX_NUM = 50
gt_bbox2 = np.zeros((MAX_NUM, 4))
gt_class2 = np.zeros((MAX_NUM,))
for i in range(len(gt_bbox)):
gt_bbox2[i, :] = gt_bbox[i, :]
gt_class2[i] = gt_class[i]
if i >= MAX_NUM:
break
return gt_bbox2, gt_class2
def get_img_data_from_file(record):
"""
record is a dict as following,
record = {
'im_file': img_file,
'im_id': im_id,
'h': im_h,
'w': im_w,
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': [],
'difficult': difficult
}
"""
im_file = record['im_file']
h = record['h']
w = record['w']
is_crowd = record['is_crowd']
gt_class = record['gt_class']
gt_bbox = record['gt_bbox']
difficult = record['difficult']
img = cv2.imread(im_file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# check if h and w in record equals that read from img
assert img.shape[0] == int(h), \
"image height of {} inconsistent in record({}) and img file({})".format(
im_file, h, img.shape[0])
assert img.shape[1] == int(w), \
"image width of {} inconsistent in record({}) and img file({})".format(
im_file, w, img.shape[1])
gt_boxes, gt_labels = get_bbox(gt_bbox, gt_class)
# gt_bbox 用相对值
gt_boxes[:, 0] = gt_boxes[:, 0] / float(w)
gt_boxes[:, 1] = gt_boxes[:, 1] / float(h)
gt_boxes[:, 2] = gt_boxes[:, 2] / float(w)
gt_boxes[:, 3] = gt_boxes[:, 3] / float(h)
return img, gt_boxes, gt_labels, (h, w)record = records[0]
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
print('img shape:{}, \n gt_labels:{}, \n scales:{}\n'.format(img.shape, gt_labels, scales))img shape:(1258, 1258, 3),
gt_labels:[0. 1. 5. 2. 4. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.],
scales:(1258.0, 1258.0)
get_img_data_from_file()函数可以返回图片数据的数据,它们是图像数据img,真实框坐标gt_boxes,真实框包含的物体类别gt_labels,图像尺寸scales。
在计算机视觉中,通常会对图像做一些随机的变化,产生相似但又不完全相同的样本。主要作用是扩大训练数据集,抑制过拟合,提升模型的泛化能力,常用的方法主要有以下几种:
- 随机改变亮暗、对比度和颜色
- 随机填充
- 随机缩放
- 随机翻转
- 随机打乱真实框排列顺序
下面我们分别使用numpy 实现这些数据增强方法。
随机改变亮暗、对比度和颜色等
import numpy as np
import cv2
from PIL import Image, ImageEnhance
import random
# 随机改变亮暗、对比度和颜色等
def random_distort(img):
# 随机改变亮度
def random_brightness(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Brightness(img).enhance(e)
# 随机改变对比度
def random_contrast(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Contrast(img).enhance(e)
# 随机改变颜色
def random_color(img, lower=0.5, upper=1.5):
e = np.random.uniform(lower, upper)
return ImageEnhance.Color(img).enhance(e)
ops = [random_brightness, random_contrast, random_color]
np.random.shuffle(ops)
img = Image.fromarray(img)
img = ops[0](img)
img = ops[1](img)
img = ops[2](img)
img = np.asarray(img)
return img
# 定义可视化函数,用于对比原图和图像增强的效果
import matplotlib.pyplot as plt
%matplotlib inline
def visualize(srcimg, img_enhance):
# 图像可视化
plt.figure(num=2, figsize=(6,12))
plt.subplot(1,2,1)
plt.title('Src Image', color='#0000FF')
plt.axis('off') # 不显示坐标轴
plt.imshow(srcimg) # 显示原图片
# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
srcimg_gtbox = records[0]['gt_bbox']
srcimg_label = records[0]['gt_class']
plt.subplot(1,2,2)
plt.title('Enhance Image', color='#0000FF')
plt.axis('off') # 不显示坐标轴
plt.imshow(img_enhance)
image_path = records[0]['im_file']
print("read image from file {}".format(image_path))
srcimg = Image.open(image_path)
# 将PIL读取的图像转换成array类型
srcimg = np.array(srcimg)
# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
img_enhance = random_distort(srcimg)
visualize(srcimg, img_enhance)read image from file /home/aistudio/work/insects/train/images/493.jpeg
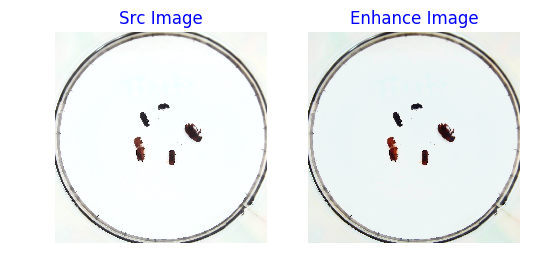
<Figure size 600x1200 with 2 Axes>
# 随机填充
def random_expand(img,
gtboxes,
max_ratio=4.,
fill=None,
keep_ratio=True,
thresh=0.5):
if random.random() > thresh:
return img, gtboxes
if max_ratio < 1.0:
return img, gtboxes
h, w, c = img.shape
ratio_x = random.uniform(1, max_ratio)
if keep_ratio:
ratio_y = ratio_x
else:
ratio_y = random.uniform(1, max_ratio)
oh = int(h * ratio_y)
ow = int(w * ratio_x)
off_x = random.randint(0, ow - w)
off_y = random.randint(0, oh - h)
out_img = np.zeros((oh, ow, c))
if fill and len(fill) == c:
for i in range(c):
out_img[:, :, i] = fill[i] * 255.0
out_img[off_y:off_y + h, off_x:off_x + w, :] = img
gtboxes[:, 0] = ((gtboxes[:, 0] * w) + off_x) / float(ow)
gtboxes[:, 1] = ((gtboxes[:, 1] * h) + off_y) / float(oh)
gtboxes[:, 2] = gtboxes[:, 2] / ratio_x
gtboxes[:, 3] = gtboxes[:, 3] / ratio_y
return out_img.astype('uint8'), gtboxes
srcimg_gtbox = records[0]['gt_bbox']
srcimg_label = records[0]['gt_class']
img_enhance, new_gtbox = random_expand(srcimg, srcimg_gtbox)
visualize(srcimg, img_enhance)
<Figure size 600x1200 with 2 Axes>
# 随机缩放
def random_interp(img, size, interp=None):
interp_method = [
cv2.INTER_NEAREST,
cv2.INTER_LINEAR,
cv2.INTER_AREA,
cv2.INTER_CUBIC,
cv2.INTER_LANCZOS4,
]
if not interp or interp not in interp_method:
interp = interp_method[random.randint(0, len(interp_method) - 1)]
h, w, _ = img.shape
im_scale_x = size / float(w)
im_scale_y = size / float(h)
img = cv2.resize(
img, None, None, fx=im_scale_x, fy=im_scale_y, interpolation=interp)
return img
# 对原图做 随机缩放
random_size = 640
img_enhance = random_interp(srcimg, random_size)
visualize(srcimg, img_enhance)
print('src image shape:{}, resize imgage shape:{}'.format(srcimg.shape, img_enhance.shape))src image shape:(1258, 1258, 3), resize imgage shape:(640, 640, 3)
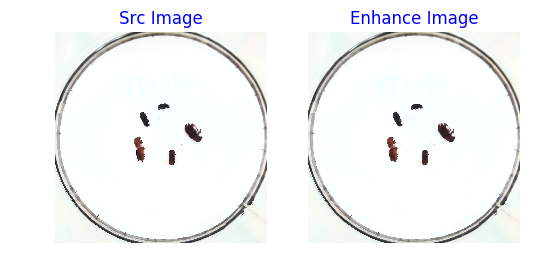
<Figure size 600x1200 with 2 Axes>
# 随机翻转
def random_flip(img, gtboxes, thresh=0.5):
if random.random() > thresh:
img = img[:, ::-1, :]
gtboxes[:, 0] = 1.0 - gtboxes[:, 0]
return img, gtboxes
# 对原图做 随机改变亮暗、对比度和颜色等 数据增强
img_enhance, box_enhance = random_flip(srcimg, srcimg_gtbox)
visualize(srcimg, img_enhance)
<Figure size 600x1200 with 2 Axes>
随机打乱真实框排列顺序
# 随机打乱真实框排列顺序
def shuffle_gtbox(gtbox, gtlabel):
gt = np.concatenate(
[gtbox, gtlabel[:, np.newaxis]], axis=1)
idx = np.arange(gt.shape[0])
np.random.shuffle(idx)
gt = gt[idx, :]
return gt[:, :4], gt[:, 4]图像增广方法汇总
# 图像增广方法汇总
def image_augment(img, gtboxes, gtlabels, size, means=None):
# 随机改变亮暗、对比度和颜色等
img = random_distort(img)
# 随机填充
img, gtboxes = random_expand(img, gtboxes, fill=means)
# 随机缩放
img = random_interp(img, size)
# 随机翻转
img, gtboxes = random_flip(img, gtboxes)
# 随机打乱真实框排列顺序
gtboxes, gtlabels = shuffle_gtbox(gtboxes, gtlabels)
return img.astype('float32'), gtboxes.astype('float32'), gtlabels.astype('int32')
img_enhance, img_box, img_label = image_augment(srcimg, srcimg_gtbox, srcimg_label, size=320)
visualize(srcimg, img_enhance)Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

<Figure size 600x1200 with 2 Axes>
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
size = 512
img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)
print('img shape:{}\n gt_boxes shape:{}\n gt_labels shape:{}'.format(img.shape, gt_boxes.shape, gt_labels.shape))img shape:(512, 512, 3)
gt_boxes shape:(50, 4)
gt_labels shape:(50,)
这里得到的img数据数值需要调整,需要除以255,并且减去均值和方差,再将维度从[H, W, C]调整为[C, H, W]。
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
size = 512
img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape((1, 1, -1))
std = np.array(std).reshape((1, 1, -1))
img = (img / 255.0 - mean) / std
img = img.astype('float32').transpose((2, 0, 1))将上面的过程整理成一个get_img_data函数。
def get_img_data(record, size=640):
img, gt_boxes, gt_labels, scales = get_img_data_from_file(record)
img, gt_boxes, gt_labels = image_augment(img, gt_boxes, gt_labels, size)
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape((1, 1, -1))
std = np.array(std).reshape((1, 1, -1))
img = (img / 255.0 - mean) / std
img = img.astype('float32').transpose((2, 0, 1))
return img, gt_boxes, gt_labels, scalesTRAINDIR = '/home/aistudio/work/insects/train'
TESTDIR = '/home/aistudio/work/insects/test'
VALIDDIR = '/home/aistudio/work/insects/val'
cname2cid = get_insect_names()
records = get_annotations(cname2cid, TRAINDIR)
record = records[0]
img, gt_boxes, gt_labels, scales = get_img_data(record, size=480)
print('img shape:{} \n gt_boxes shape:{}\n gt_bales:{}\n scales:{}'.format(img.shape, gt_boxes.shape, gt_labels, scales))img shape:(3, 480, 480)
gt_boxes shape:(50, 4)
gt_bales:[0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 0 0 2 0 0 0 0 0 0 0
0 0 0 0 1 0 0 3 0 5 0 0 0]
scales:(1288.0, 1288.0)
5.3.1.4 批量数据读取
上面的程序展示了如何读取一张图片的数据并加速,但在真实场景的模型训练与评估过程中,通常会使用批量数据读取和预处理的方式。下面代码实现了批量数据读取。
# 获取一个批次内样本随机缩放的尺寸
def get_img_size(mode):
if (mode == 'train') or (mode == 'valid'):
inds = np.array([0,1,2,3,4,5,6,7,8,9])
ii = np.random.choice(inds)
img_size = 320 + ii * 32
else:
img_size = 608
return img_size
# 将 list形式的batch数据 转化成多个array构成的tuple
def make_array(batch_data):
img_array = np.array([item[0] for item in batch_data], dtype = 'float32')
gt_box_array = np.array([item[1] for item in batch_data], dtype = 'float32')
gt_labels_array = np.array([item[2] for item in batch_data], dtype = 'int32')
img_scale = np.array([item[3] for item in batch_data], dtype='int32')
return img_array, gt_box_array, gt_labels_array, img_scale由于数据预处理耗时较长,可能会成为网络训练速度的瓶颈,所以需要对预处理部分进行优化。通过使用飞桨提供的paddle.io.DataLoaderAPI中的num_workers参数设置进程数量,实现多进程读取数据,具体实现代码如下。
import paddle
# 定义数据读取类,继承Paddle.io.Dataset
class TrainDataset(paddle.io.Dataset):
def __init__(self, datadir, mode='train'):
self.datadir = datadir
cname2cid = get_insect_names()
self.records = get_annotations(cname2cid, datadir)
self.img_size = 640 #get_img_size(mode)
def __getitem__(self, idx):
record = self.records[idx]
# print("print: ", record)
img, gt_bbox, gt_labels, im_shape = get_img_data(record, size=self.img_size)
return img, gt_bbox, gt_labels, np.array(im_shape)
def __len__(self):
return len(self.records)
# 创建数据读取类
train_dataset = TrainDataset(TRAINDIR, mode='train')
# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数
train_loader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=2, drop_last=True)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
img, gt_boxes, gt_labels, im_shape = next(train_loader())
print('img shape:{}\n gt_boxes shape:{}\n gt_labels shape:{}'.format(img.shape, gt_boxes.shape, gt_labels.shape))至此,我们完成了如何查看数据集中的数据、提取数据标注信息、从文件读取图像和标注数据、图像增广、批量读取和加速等过程,通过paddle.io.Dataset可以返回img, gt_boxes, gt_labels, im_shape等数据,接下来就可以将它们输入到神经网络,应用到具体算法上了。
在开始具体的算法讲解之前,先补充一下读取测试数据的代码。测试数据没有标注信息,也不需要做图像增广,代码如下所示。
import os
# 将 list形式的batch数据 转化成多个array构成的tuple
def make_test_array(batch_data):
img_name_array = np.array([item[0] for item in batch_data])
img_data_array = np.array([item[1] for item in batch_data], dtype = 'float32')
img_scale_array = np.array([item[2] for item in batch_data], dtype='int32')
return img_name_array, img_data_array, img_scale_array
# 测试数据读取
def test_data_loader(datadir, batch_size= 10, test_image_size=608, mode='test'):
"""
加载测试用的图片,测试数据没有groundtruth标签
"""
image_names = os.listdir(datadir)
def reader():
batch_data = []
img_size = test_image_size
for image_name in image_names:
file_path = os.path.join(datadir, image_name)
img = cv2.imread(file_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
H = img.shape[0]
W = img.shape[1]
img = cv2.resize(img, (img_size, img_size))
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape((1, 1, -1))
std = np.array(std).reshape((1, 1, -1))
out_img = (img / 255.0 - mean) / std
out_img = out_img.astype('float32').transpose((2, 0, 1))
img = out_img #np.transpose(out_img, (2,0,1))
im_shape = [H, W]
batch_data.append((image_name.split('.')[0], img, im_shape))
if len(batch_data) == batch_size:
yield make_test_array(batch_data)
batch_data = []
if len(batch_data) > 0:
yield make_test_array(batch_data)
return reader
















 6186
6186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











