







一、自然语言情感分析
人类自然语言具有高度的复杂性,相同的对话在不同的情景,不同的情感,不同的人演绎,表达的效果往往也会迥然不同。例如"你真的太瘦了",当你聊天的对象是一位身材苗条的人,这是一句赞美的话;当你聊天的对象是一位肥胖的人时,这就变成了一句嘲讽。感兴趣的读者可以看一段来自肥伦秀的视频片段,继续感受下人类语言情感的复杂性。
从视频中的内容可以看出,人类自然语言不只具有复杂性,同时也蕴含着丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
简单的说,我们可以将情感分析(sentiment classification)任务定义为一个分类问题,即指定一个文本输入,机器通过对文本进行分析、处理、归纳和推理后自动输出结论,如图1所示。
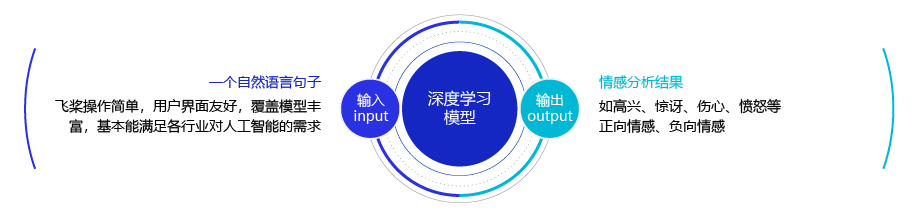
图1:情感分析任务
通常情况下,人们把情感分析任务看成一个三分类问题,如图2所示:

图2:情感分析任务
- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
在情感分析任务中,研究人员除了分析句子的情感类型外,还细化到以句子中具体的“方面”为分析主体进行情感分析(aspect-level),如下:
这个薯片口味有点咸,太辣了,不过口感很脆。
关于薯片的口味方面是一个负向评价(咸,太辣),然而对于口感方面却是一个正向评价(很脆)。
我很喜欢夏威夷,就是这边的海鲜太贵了。
关于夏威夷是一个正向评价(喜欢),然而对于夏威夷的海鲜却是一个负向评价(价格太贵)。
1.1 使用深度神经网络完成情感分析任务
上一节课我们学习了通过把每个单词转换成向量的方式,可以完成单词语义计算任务。那么我们自然会联想到,是否可以把每个自然语言句子也转换成一个向量表示,并使用这个向量表示完成情感分析任务呢?
在日常工作中有一个非常简单粗暴的解决方式:就是先把一个句子中所有词的embedding进行加权平均,再用得到的平均embedding作为整个句子的向量表示。然而由于自然语言变幻莫测,我们在使用神经网络处理句子的时候,往往会遇到如下两类问题:
- 变长的句子: 自然语言句子往往是变长的,不同的句子长度可能差别很大。然而大部分神经网络接受的输入都是张量,长度是固定的,那么如何让神经网络处理变长数据成为了一大挑战。
- 组合的语义: 自然语言句子往往对结构非常敏感,有时稍微颠倒单词的顺序都可能改变这句话的意思,比如:
你等一下我做完作业就走。 我等一下你做完工作就走。
我不爱吃你做的饭。 你不爱吃我做的饭。
我瞅你咋地。
你瞅我咋地。
因此,我们需要找到一个可以考虑词和词之间顺序(关系)的神经网络,用于更好地实现自然语言句子建模。
1.2 处理变长数据
在使用神经网络处理变长数据时,需要先设置一个全局变量max_seq_len,再对语料中的句子进行处理,将不同的句子组成mini-batch,用于神经网络学习和处理。
1. 设置全局变量
设定一个全局变量max_seq_len,用来控制神经网络最大可以处理文本的长度。我们可以先观察语料中句子的分布,再设置合理的max_seq_len值,以最高的性价比完成句子分类任务(如情感分类)。
2. 对语料中的句子进行处理
我们通常采用截断+填充的方式,对语料中的句子进行处理,将不同长度的句子组成mini-batch,以便让句子转换成一个张量给神经网络进行计算,如图 3所示。
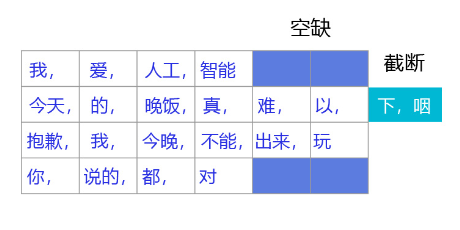
图3:变长数据处理
- 对于长度超过max_seq_len的句子,通常会把这个句子进行截断,以便可以输入到一个张量中。句子截断是有技巧的,有时截取句子的前一部分会比后一部分好,有时则恰好相反。当然也存在其他的截断方式,有兴趣的读者可以翻阅一下相关资料,这里不做赘述。
- 前向截断: “晚饭, 真, 难, 以, 下, 咽”
- 后向截断: “今天, 的, 晚饭, 真, 难, 以”
- 对于句子长度不足max_seq_len的句子,我们一般会使用一个特殊的词语对这个句子进行填充,这个过程称为Padding。假设给定一个句子“我,爱,人工,智能”,max_seq_len=6,那么可能得到两种填充方式:
- 前向填充: “[pad],[pad],我,爱,人工,智能”
- 后向填充: “我,爱,人工,智能,[pad],[pad]”
同样,不同的填充方式也对网络训练效果有一定影响。一般来说,后向填充是更常用的选择。
1.3 学习句子的语义
上一节课学习了如何学习每个单词的语义信息,从上面的举例中我们也会观察到,一个句子中词的顺序往往对这个句子的整体语义有重要的影响。因此,在刻画整个句子的语义信息过程中,不能撇开顺序信息。如果简单粗暴地把这个句子中所有词的向量做加和,会使得我们的模型无法区分句子的真实含义,例如:
我不爱吃你做的饭。 你不爱吃我做的饭。
一个有趣的想法,把一个自然语言句子看成一个序列,把自然语言的生成过程看成是一个序列生成的过程。例如对于句子“我,爱,人工,智能”,这句话的生成概率P(我,爱,人工,智能)可以被表示为:

上面的公式把一个句子的生成过程建模成一个序列的决策过程,这就是香农在1950年左右提出的使用马尔可夫过程建模自然语言的思想。使用序列的视角看待和建模自然语言有一个明显的好处,那就是在对每个词建模的过程中,都有机会去学习这个词和之前生成的词之间的关系,并利用这种关系更好地处理自然语言。如图4所示,生成句子“我,爱,人工”后,“智能”在下一步生成的概率就变得很高了,因为“人工智能”经常同时出现。
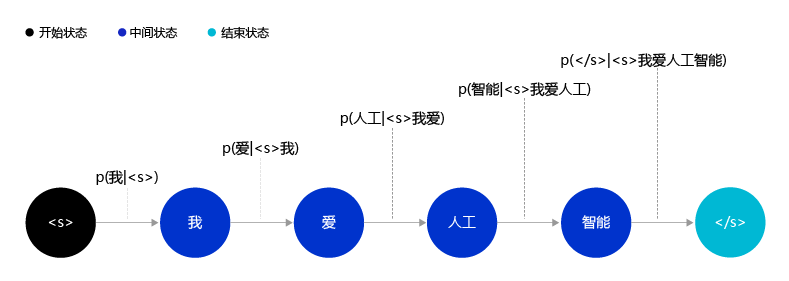
图4:自然语言生成过程示意图
通过考虑句子内部的序列关系,我们就可以清晰地区分“我不爱吃你做的菜”和“你不爱吃我做的菜”这两句话之间的联系与不同了。事实上,目前大多数成功的自然语言模型都建立在对句子的序列化建模上。下面让我们学习两个经典的序列化建模模型:循环神经网络(Recurrent Neural Network,RNN)和长短时记忆网络(Long Short-Term Memory,LSTM)。
二、循环神经网络RNN和长短时记忆网络LSTM
2.1 RNN和LSTM网络的设计思考
与读者熟悉的卷积神经网络(Convolutional Neural Networks, CNN)一样,各种形态的神经网络在设计之初,均有针对特定场景的奇思妙想。卷积神经网络的设计具备适合视觉任务“局部视野”特点,是因为视觉信息是局部有效的。例如在一张图片的1/4区域上有一只小猫,如果将图片3/4的内容遮挡,人类依然可以判断这是一只猫。
与此类似,RNN和LSTM的设计初衷是部分场景神经网络需要有“记忆”能力才能解决的任务。在自然语言处理任务中,往往一段文字中某个词的语义可能与前一段句子的语义相关,只有记住了上下文的神经网络才能很好的处理句子的语义关系。例如:
我一边吃着苹果,一边玩着苹果手机。
网络只有正确的记忆两个“苹果”的上下文“吃着”和“玩着…手机”,才能正确的识别两个苹果的语义,分别是水果和手机品牌。如果网络没有记忆功能,那么两个“苹果”只能归结到更高概率出现的语义上,得到一个相同的语义输出,这显然是不合理的。
如何设计神经网络的记忆功能呢?我们先了解下RNN网络是如何实现具备记忆功能的。RNN相当于将神经网络单元进行了横向连接,处理前一部分输入的RNN单元不仅有正常的模型输出,还会输出“记忆”传递到下一个RNN单元。而处于后一部分的RNN单元,不仅仅有来自于任务数据的输入,同时会接收从前一个RNN单元传递过来的记忆输入,这样就使得整个神经网络具备了“记忆”能力。
但是RNN网络只是初步实现了“记忆”功能,在此基础上科学家们又发明了一些RNN的变体,来加强网络的记忆能力。但RNN对“记忆”能力的设计是比较粗糙的,当网络处理的序列数据过长时,累积的内部信息就会越来越复杂,直到超过网络的承载能力,通俗的说“事无巨细的记录,总有一天大脑会崩溃”。为了解决这个问题,科学家巧妙的设计了一种记忆单元,称之为“长短时记忆网络(Long Short-Term Memory,LSTM)”。在每个处理单元内部,加入了输入门、输出门和遗忘门的设计,三者有明确的任务分工:
- 输入门:控制有多少输入信号会被融合;
- 遗忘门:控制有多少过去的记忆会被遗忘;
- 输出门:控制多少处理后的信息会被输出;
三者的作用与人类的记忆方式有异曲同工之处,即:
- 与当前任务无关的信息会直接过滤掉,如非常专注的开车时,人们几乎不注意沿途的风景;
- 过去记录的事情不一定都要永远记住,如令人伤心或者不重要的事,通常会很快被淡忘;
- 根据记忆和现实观察进行决策,如开车时会结合记忆中的路线和当前看到的路标,决策转弯或不做任何动作。
了解了这些关于网络设计的本质,下面进入实现方案的细节。
2.2 RNN网络结构
RNN是一个非常经典的面向序列的模型,可以对自然语言句子或是其它时序信号进行建模,网络结构如图5所示。
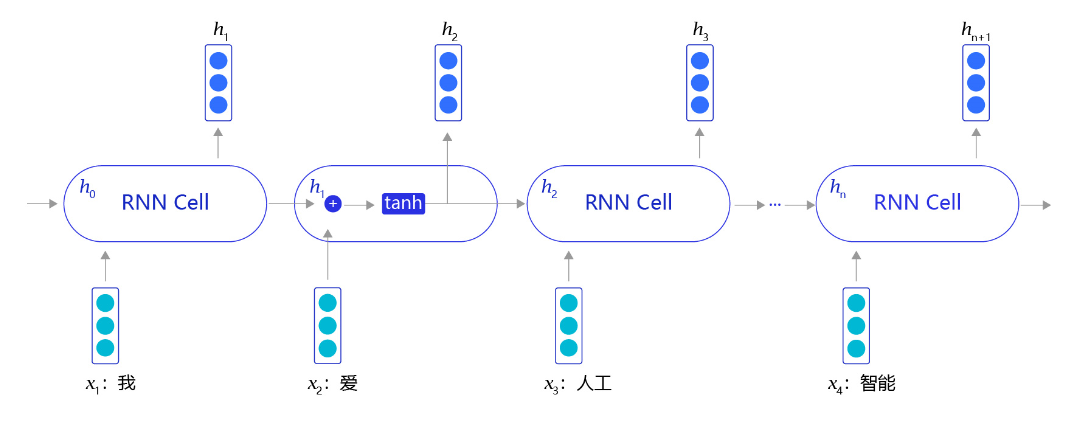
图5:RNN网络结构
不同于其他常见的神经网络结构,循环神经网络的输入是一个序列信息。假设给定任意一句话[x0,x1,...,xn],其中每个x_i都代表了一个词,如“我,爱,人工,智能”。
循环神经网络从左到右逐词阅读这个句子,并不断调用一个相同的RNN Cell来处理时序信息。每阅读一个单词,循环神经网络会先将本次输入的单词通过embedding lookup转换为一个向量表示。再把这个单词的向量表示和这个模型内部记忆的向量h融合起来,形成一个更新的记忆。最后将这个融合后的表示输出出来,作为它当前阅读到的所有内容的语义表示。当循环神经网络阅读过整个句子之后,我们就可以认为它的最后一个输出状态表示了整个句子的语义信息。
听上去很复杂,下面我们以一个简单地例子来说明,假设输入的句子为:
“我,爱,人工,智能”
循环神经网络开始从左到右阅读这个句子,在未经过任何阅读之前,循环神经网络中的记忆向量是空白的。其处理逻辑如下:
- 网络阅读单词“我”,并把单词“我”的向量表示和空白记忆相融合,输出一个向量h_1 ,用于表示“空白+我”的语义。
- 网络开始阅读单词“爱”,这时循环神经网络内部存在“空白+我”的记忆。循环神经网络会将“空白+我”和“爱”的向量表示相融合,并输出“空白+我+爱”的向量表示h_2 ,用于表示“我爱”这个短语的语义信息。
- 网络开始阅读单词“人工”,同样经过融合之后,输出“空白+我+爱+人工”的向量表示h_3 ,用于表示“空白+我+爱+人工”语义信息。
- 最终在网络阅读了“智能”单词后,便可以输出“我爱人工智能”这一句子的整体语义信息。
说明:
在实现当前输入x_t和已有记忆h_{t-1}融合的时候,循环神经网络采用相加并通过一个激活函数tanh的方式实现:
![]()
tanh函数是一个值域为(-1,1)的函数,其作用是长期维持内部记忆在一个固定的数值范围内,防止因多次迭代更新导致数值爆炸。同时tanh的导数是一个平滑的函数,会让神经网络的训练变得更加简单。
2.3 LSTM网络结构
上述方法听上去很有效(事实上在有些任务上效果还不错),但是存在一个明显的缺陷,就是当阅读很长的序列时,网络内部的信息会变得越来越复杂,甚至会超过网络的记忆能力,使得最终的输出信息变得混乱无用。长短时记忆网络(Long Short-Term Memory,LSTM)内部的复杂结构正是为处理这类问题而设计的,其网络结构如图6所示。
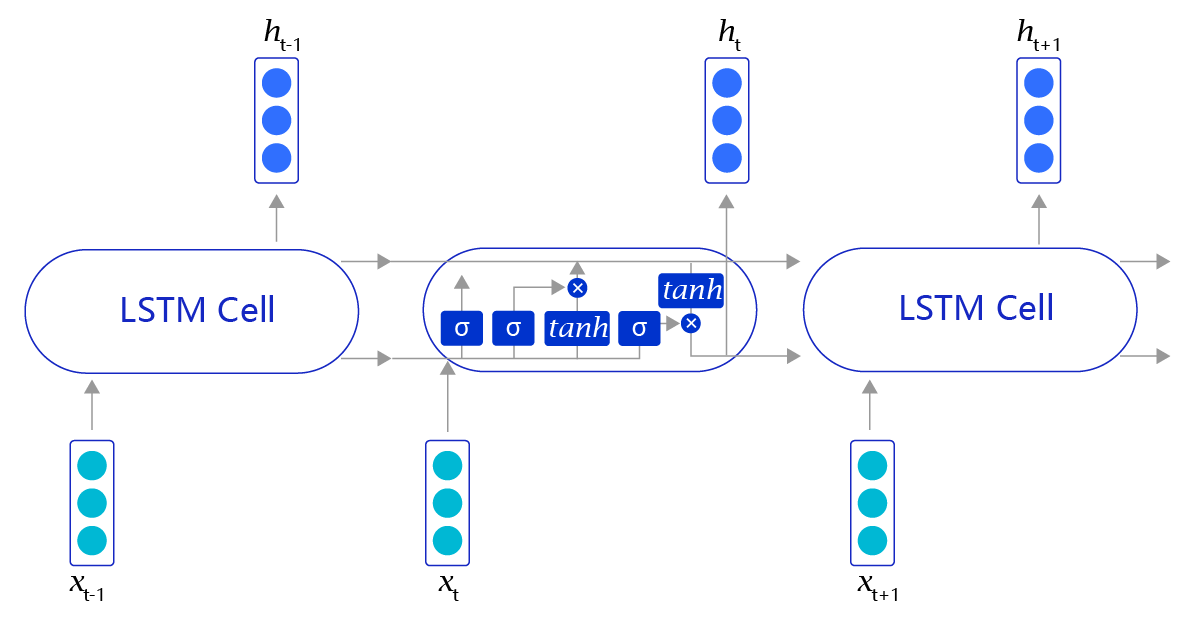
图6:LSTM网络结构
长短时记忆网络的结构和循环神经网络非常类似,都是通过不断调用同一个cell来逐次处理时序信息。每阅读一个新单词x_t,就会输出一个新的输出信号h_t,用来表示当前阅读到所有内容的整体向量表示。不过二者又有一个明显区别,长短时记忆网络在不同cell之间传递的是两个记忆信息,而不像循环神经网络一样只有一个记忆信息,此外长短时记忆网络的内部结构也更加复杂,如图7所示。
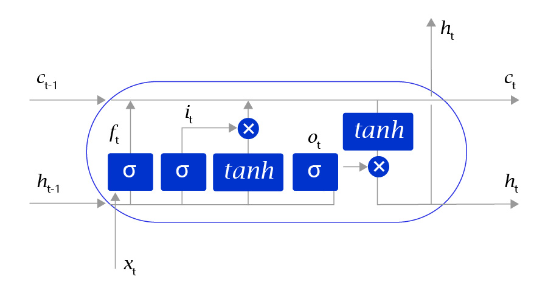
图7:LSTM网络内部结构示意图
区别于循环神经网络RNN,长短时记忆网络最大的特点是在更新内部记忆时,引入了遗忘机制。即容许网络忘记过去阅读过程中看到的一些无关紧要的信息,只保留有用的历史信息。通过这种方式延长了记忆长度。举个例子:
我觉得这家餐馆的菜品很不错,烤鸭非常正宗,包子也不错,酱牛肉很有嚼劲。但是服务员态度太恶劣了,我们在门口等了50分钟都没有能成功进去,好不容易进去了,桌子也半天没人打扫。整个环境非常吵闹,我的孩子都被吓哭了,我下次不会带朋友来。
当我们阅读上面这段话的时候,可能会记住一些关键词,如烤鸭好吃、牛肉有嚼劲、环境吵等,但也会忽略一些不重要的内容,如“我觉得”、“好不容易”等,长短时记忆网络正是受这个启发而设计的。
长短时记忆网络的Cell有三个输入:
- 这个网络新看到的输入信号,如下一个单词,记为x_{t} , 其中x_{t} 是一个向量,t 代表了当前时刻。
- 这个网络在上一步的输出信号,记为h_{t-1} ,这是一个向量,维度同x_{t} 相同。
- 这个网络在上一步的记忆信号,记为c_{t-1} ,这是一个向量,维度同x_{t} 相同。
得到这两个信号之后,长短时记忆网络没有立即去融合这两个向量,而是计算了权重。
- 输入门: i t = σ ( W i X t + V i H t − 1 + b i ) ,控制有多少输入信号会被融合。
- 遗忘门: f t = σ ( W f X t + V f H t − 1 + b f ) ,控制有多少过去的记忆会被遗忘。
- 输出门: o t = σ ( W o X t + V o H t − 1 + b o ) ,控制最终输出多少融合了记忆的信息。
- 单元状态: g t = t a n h ( Wg Xt+Vg Ht −1+bg ),输入信号和过去的输入信号做一个信息融合。
其中σ\sigma表示的是sigmoid激活函数,tanh表示的是双曲正切激活函数。
通过学习这些门的权重设置,长短时记忆网络可以根据当前的输入信号和记忆信息,有选择性地忽略或者强化当前的记忆或是输入信号,帮助网络更好地学习长句子的语义信息:
- 记忆信号: c t = f t ⋅ c t − 1 + i t ⋅ g t
- 输出信号: h t = o t ⋅ t a n h ( c t )
说明:
事实上,长短时记忆网络之所以能更好地对长文本进行建模,还存在另外一套更加严谨的计算和证明,有兴趣的读者可以翻阅一下引文中的参考资料进行详细研究。
2.4 使用LSTM完成情感分析任务
借助长短时记忆网络,我们可以非常轻松地完成情感分析任务。如图8所示。对于每个句子,我们首先通过截断和填充的方式,把这些句子变成固定长度的向量。然后,利用长短时记忆网络,从左到右开始阅读每个句子。在完成阅读之后,我们使用长短时记忆网络的最后一个输出记忆,作为整个句子的语义信息,并直接把这个向量作为输入,送入一个分类层进行分类,从而完成对情感分析问题的神经网络建模。

图8:LSTM完成情感分析任务流程

















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











