







💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
在YOLOv5的GFLOPs计算量中,卷积占了其中大多数的比列,为了减少计算量,研究人员提出了用DwConv代替Conv。本文给大家带来的教程是将原来的Conv替换为DwConv。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法
目录
1. 原理
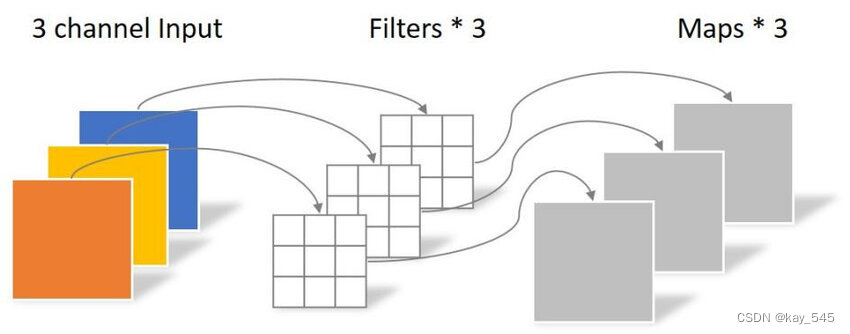
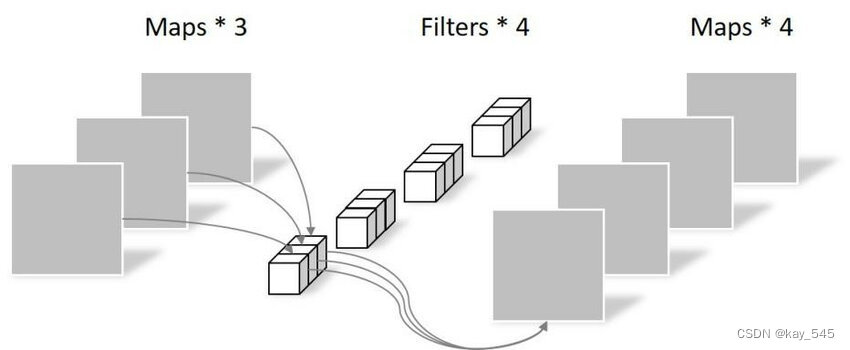
Dwconv,或深度可分离卷积(Depthwise Separable Convolution),是一种在神经网络中常用的卷积操作。它由两部分组成:深度卷积和逐点卷积。
1. 深度卷积(Depthwise Convolution):在深度卷积中,每个输入通道都与一个单独的滤波器(kernel)进行卷积操作。这意味着每个输入通道都会生成一个对应的输出通道。深度卷积主要用于捕捉输入数据的空间信息。
2. 逐点卷积(Pointwise Convolution):逐点卷积是一个 1×1 的卷积操作,它在每个位置上对输入的所有通道进行卷积。逐点卷积可以看作是在输入数据的通道维度上进行的卷积操作,而不涉及空间信息。它用于将深度卷积生成的各个通道的特征图进行线性组合。
使用深度可分离卷积的主要优势在于减少了计算量和参数数量,同时提高了模型的效率和速度。因为在深度卷积中,每个通道只需要与一个滤波器进行卷积,而不是像传统卷积那样每个通道都需要与所有滤波器进行卷积。逐点卷积进一步减少了参数数量,通过降低输入通道的维度。这种结构可以在保持相对较高的性能的同时,显著减少模型的大小和计算需求,特别是在移动设备等资源受限的环境中。
2. 代码实现
2.1 添加DwConv到YOLOv5代码中
关键步骤一:将下面代码粘贴到/projects/yolov5-6.1/models/common.py文件中
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
Dwconv的流程可以分为以下几个步骤:
1. 输入数据:首先,我们有一个输入数据张量,通常是一个多通道的特征图。这个特征图可以是来自于之前的层级输出或者是网络的输入。
2. 深度卷积(Depthwise Convolution):对输入数据的每个通道应用深度卷积操作。对于每个输入通道,使用一个单独的滤波器(kernel)进行卷积操作。这个滤波器的大小通常是一个小的正方形,比如3x3或5x5。这个操作会生成与输入通道数相同的输出通道数,每个通道都包含了该通道的卷积结果。
3. 逐点卷积(Pointwise Convolution):接下来,对深度卷积生成的特征图应用逐点卷积操作。逐点卷积使用1x1的卷积核,在每个位置上对所有通道进行卷积操作。这个操作实际上是对特征图的每个像素点进行线性组合,将深度卷积生成的各个通道特征进行混合。逐点卷积的输出通道数量可以由设计者灵活指定,通常用来控制输出特征图的深度。
4. 非线性激活函数:通常,在逐点卷积之后,会应用一个非线性激活函数,比如ReLU,来增加网络的非线性表达能力。
5. 可选的池化或下采样:在需要的情况下,可以添加池化层或者其他下采样操作,以减小特征图的空间维度,同时保留重要的特征。
6. 输出:最终的输出是经过深度可分离卷积和非线性激活后得到的特征图。这些特征图可以传递到网络的下一层,也可以作为最终的输出。
Dwconv通过将传统的卷积操作拆分成深度卷积和逐点卷积两个步骤,从而降低了参数数量和计算复杂度,同时保持了模型的表达能力和性能。这种结构特别适用于移动端和嵌入式设备等资源受限的场景。
2.2 新增yaml文件
关键步骤二:在下/projects/yolov5-6.1/models下新建文件 yolov5_dw.yaml并将下面代码复制进去,当然你也可以自己修改,替换不同数量不同位置的Conv
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, DWConv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, DWConv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, DWConv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, DWConv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, DWConv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, DWConv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, DWConv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, DWConv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
温馨提示:本文只是对yolov5l基础上添加swin模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py中注册, 大概在260行左右添加 ‘DwConv’

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_dwconv.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
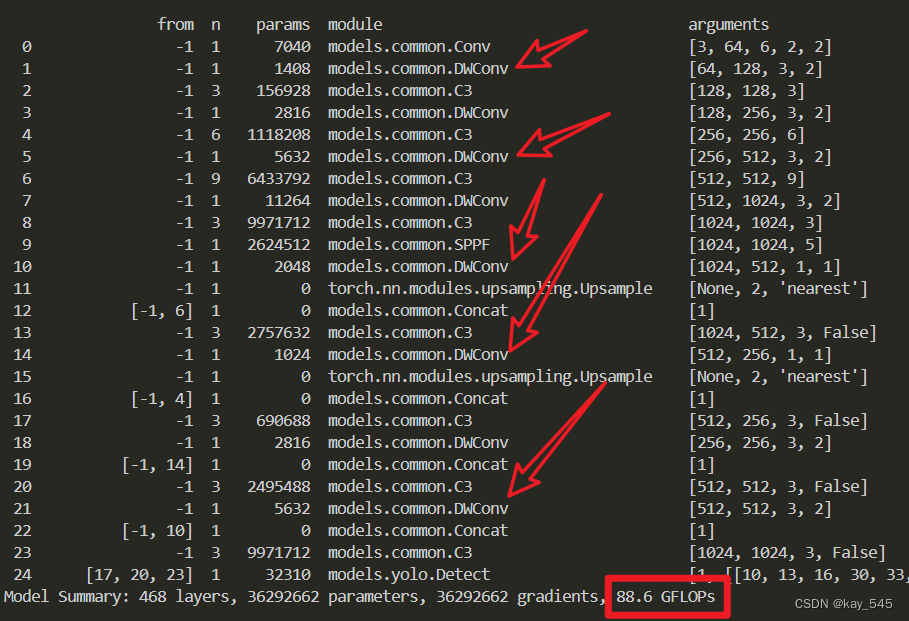
3. 完整代码分享
https://pan.baidu.com/s/1KbdSobXl8_asS2w_860iUA?pwd=7zh4👆我修改后的代码, 提取码: 7zh4
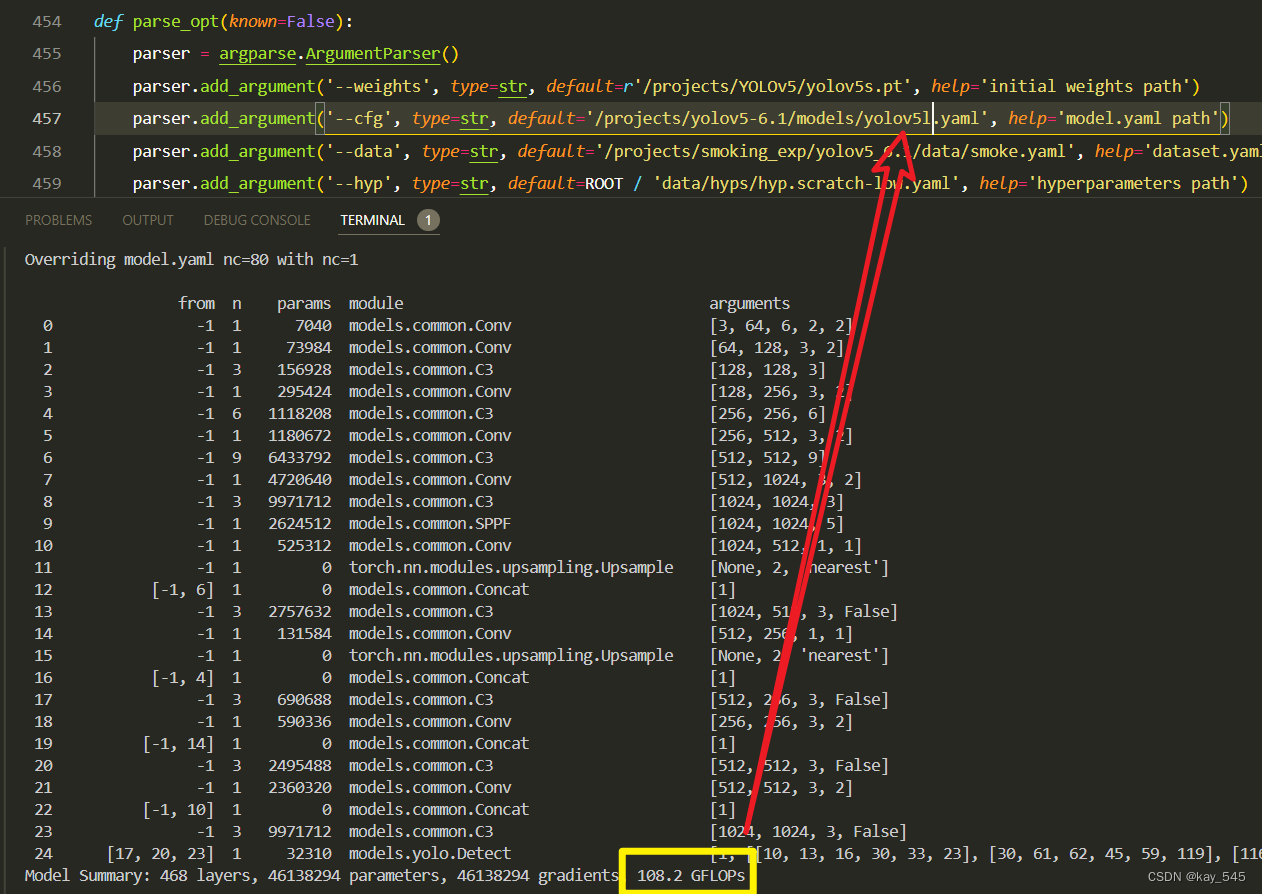
4.GFLOPs对比
未改进的YOLOv5l的GFLOPs
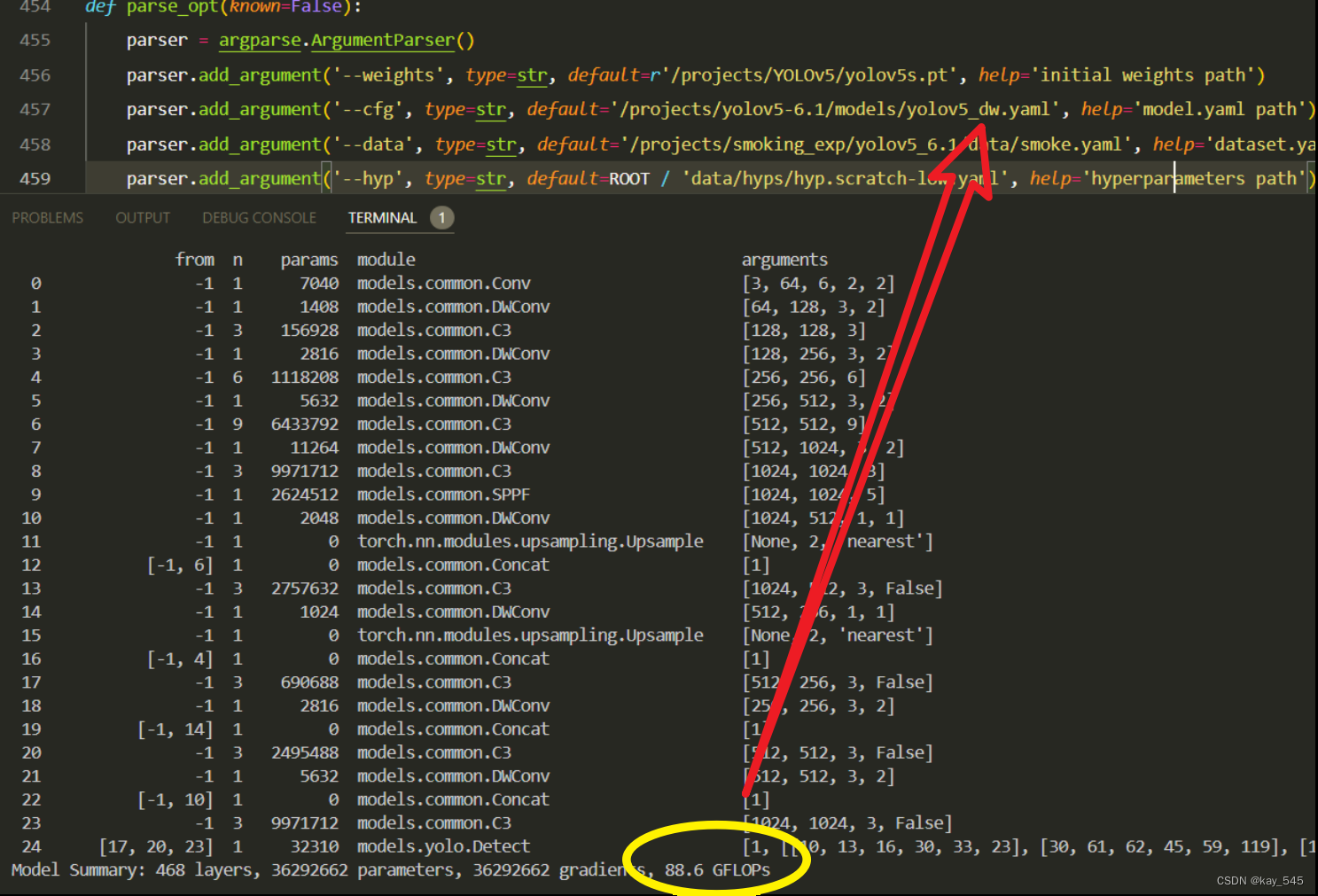
改进后的YOLOv5l的GFLOPs
5. 总结
Dwconv卷积(深度可分离卷积)是一种将传统卷积操作分解为深度卷积和逐点卷积两个步骤的技术。首先,深度卷积独立地对输入数据的每个通道进行卷积操作,生成与输入通道数相同的特征图通道。然后,逐点卷积使用1x1的卷积核对深度卷积生成的特征图进行线性组合,以减少参数数量和计算复杂度。逐点卷积的输出通道数量可以根据需要调整,控制输出特征图的深度。这种结构不仅有效地降低了模型的计算负载,同时也保持了模型的表达能力,特别适用于资源受限的移动端和嵌入式设备等场景。



















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











