







秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录:《YOLOv8改进有效涨点》专栏介绍 & 专栏目录 | 目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
目标检测是计算机视觉中一个重要的下游任务。对于边缘盒子的计算平台来说,一个大型模型很难实现实时检测的要求。而且,一个由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确度。一种新的轻量级卷积技术GSConv可以减轻模型但保持准确性。GSConv在模型的准确性和速度之间实现了优秀的权衡。在本文中,给大家带来的教程是将原来的网络中的Conv模块修改为GSConv。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
2.1 将GSConv、VoVGSCSP添加到YOLOv5中
1.原理

官方代码:代码仓库地址——点击即可跳转
Slim-neck by GSConv 是一种基于 GSConv(Grouped Spatial Convolution)的神经网络结构改进技术,主要用于减小模型的计算复杂度和参数量,同时保持或提高模型的性能。以下是对 Slim-neck by GSConv 的详细讲解:
背景和动机
随着深度学习的快速发展,模型的规模和复杂度也在不断增加,这给计算资源带来了巨大的挑战。为了在保证性能的同时减少计算开销,研究人员提出了多种方法,Slim-neck by GSConv 就是其中之一。
GSConv 的基本概念
GSConv 是 Grouped Spatial Convolution 的缩写,其核心思想是通过分组卷积(Grouped Convolution)和空间卷积(Spatial Convolution)的结合来减少计算量。具体来说,GSConv 将常规卷积分解为两个步骤:
-
分组卷积(Grouped Convolution):将输入特征图分成若干组,每组分别进行卷积操作。这样可以减少每组卷积的计算量。
-
空间卷积(Spatial Convolution):在每组卷积后的输出上再进行空间卷积操作,以捕捉跨组的特征。
Slim-neck 的改进
Slim-neck 是在 GSConv 的基础上进行的改进,旨在进一步简化模型结构,特别是在网络的颈部(neck)部分。网络的颈部通常是特征提取和特征聚合的关键部分,对模型性能有重要影响。Slim-neck 通过以下几方面进行优化:
-
通道压缩:在网络的颈部部分,采用 GSConv 进行通道压缩,以减少特征图的通道数,从而降低计算量。
-
高效连接:通过引入跳跃连接(skip connection)和高效的连接策略,确保特征信息的有效传递和利用。
-
轻量化设计:在设计上注重轻量化,尽可能减少参数量和计算复杂度,同时保持或提高模型的性能。
Slim-neck by GSConv 的应用
Slim-neck by GSConv 在多种计算资源受限的场景下具有广泛应用,例如:
-
移动设备:由于移动设备的计算资源有限,Slim-neck by GSConv 能够在不显著降低模型性能的前提下,减少计算量和功耗。
-
嵌入式系统:嵌入式系统通常需要在低功耗和有限计算资源下运行,Slim-neck by GSConv 可以提供一种高效的解决方案。
-
实时应用:在需要实时处理的应用场景中,Slim-neck by GSConv 通过减少计算延迟,提高了模型的响应速度。
实验结果与性能
通过在实际任务中的实验,Slim-neck by GSConv 通常能在保持甚至提升模型精度的同时,显著减少计算开销。例如,在图像分类、目标检测等任务中,采用 Slim-neck by GSConv 的模型相较于传统模型,计算量和参数量都有明显减少,同时性能并未显著下降,甚至在某些情况下有所提升。
总结
Slim-neck by GSConv 是一种有效的神经网络优化技术,通过分组卷积和空间卷积的结合,以及在网络颈部部分的优化,达到了降低计算复杂度和参数量的目的,适用于多种计算资源受限的应用场景。
2. GSConv、VoVGSCSP代码实现
2.1 将GSConv、VoVGSCSP添加到YOLOv5中
关键步骤一: 在/ultralytics/ultralytics/nn/modules/下新建文件gsconv.py,并在该文件的粘贴下面的代码。
import torch
from torch import nn
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class GSConv(nn.Module):
# GSConv https://github.com/AlanLi1997/slim-neck-by-gsconv
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__()
c_ = c2 // 2
self.cv1 = Conv(c1, c_, k, s, None, g, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_ , act)
def forward(self, x):
x1 = self.cv1(x)
x2 = torch.cat((x1, self.cv2(x1)), 1)
# shuffle
# y = x2.reshape(x2.shape[0], 2, x2.shape[1] // 2, x2.shape[2], x2.shape[3])
# y = y.permute(0, 2, 1, 3, 4)
# return y.reshape(y.shape[0], -1, y.shape[3], y.shape[4])
b, n, h, w = x2.data.size()
b_n = b * n // 2
y = x2.reshape(b_n, 2, h * w)
y = y.permute(1, 0, 2)
y = y.reshape(2, -1, n // 2, h, w)
return torch.cat((y[0], y[1]), 1)GSCONV 处理图片的主要流程可以概括为以下几个步骤:
1. 输入图片:
-
GSCONV 的输入是一张或多张图片,这些图片首先会经过预处理,例如缩放、归一化等操作,使其符合模型的输入要求。
2. 特征提取:
-
输入图片经过一系列卷积层和激活函数,提取出不同尺度和深度的特征图。这些特征图包含了图片中物体的位置、形状、纹理等信息。
3. GSConv 层:
-
特征图进入 GSConv 层进行处理。GSConv 层首先使用 SC 进行通道密集的卷积操作,保留通道间的信息连接。
-
然后,使用 shuffle 操作将 SC 的输出与 DSC 的输出进行混合,实现通道信息的均匀融合。
-
最后,GSConv 层输出融合后的特征图,这些特征图包含了更加丰富和准确的信息。
4. 特征融合:
-
不同尺度和深度的特征图通过特征融合模块进行融合,例如特征金字塔网络(FPN)或特征金字塔网络(FPN)+路径聚合网络(PAN)。
-
特征融合模块将不同层次的特征图进行拼接或求和,生成更全面和细致的特征图。
5. 目标检测:
-
融合后的特征图进入检测头进行目标检测。
-
检测头会根据特征图预测物体的类别、位置和大小等信息。
-
最终,模型输出检测结果,例如检测框、类别标签和置信度等。
总结: GSCONV 处理图片的主要流程可以概括为:输入图片 -> 特征提取 -> GSConv 层 -> 特征融合 -> 目标检测。其中,GSConv 层是 GSCONV 的核心部分,它通过结合 SC 和 DSC,并使用 shuffle 操作实现通道信息融合,从而在保持模型精度的同时降低计算成本。

2.2 更改init.py文件
关键步骤二:修改modules文件夹下的__init__.py文件,先导入函数
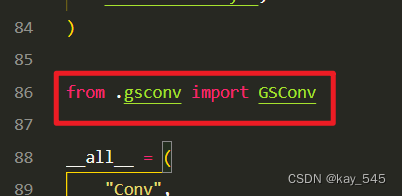
然后在下面的__all__中声明函数
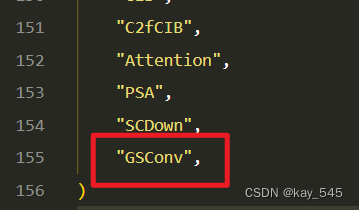
2.3 新增yaml文件
关键步骤三:在 \ultralytics\ultralytics\cfg\models\v10下新建文件 yolov10_GS.yaml并将下面代码复制进去
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 512]
backbone:
# [from, repeats, module, args]
- [-1, 1, GSConv, [64, 3, 2]] # 0-P1/2
- [-1, 1, GSConv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, GSConv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2fCIB, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2fCIB, [512, True]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2fCIB, [512, True]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
温馨提示:因为本文只是对yolov10基础上添加模块,如果要对yolov10n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv10n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channels: 1024 # max_channels
# YOLOv10s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channels: 1024 # max_channels
# YOLOv10l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
max_channels: 512 # max_channels
# YOLOv10m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
max_channels: 768 # max_channels
# YOLOv10x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
max_channels: 512 # max_channels2.4 注册模块
关键步骤四:在parse_model函数中进行注册,添加GSConv,
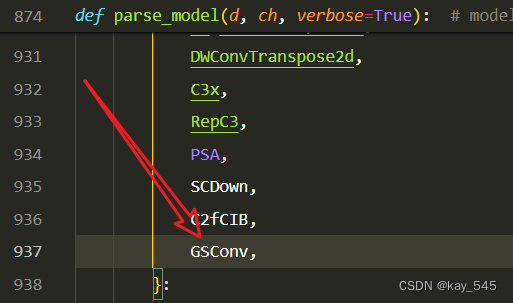
2.5 执行程序
在train.py中,将model的参数路径设置为yolov10_GS.yaml的路径
建议大家写绝对路径,确保一定能找到
from ultralytics import YOLO
# Load a model
# model = YOLO('yolov10n.yaml') # build a new model from YAML
# model = YOLO('yolov10n.pt') # load a pretrained model (recommended for training)
model = YOLO(r'/projects/ultralytics/ultralytics/cfg/models/v10/yolov10_GS.yaml') # build from YAML and transfer weights
# Train the model
model.train(device = [3], batch=16)🚀运行程序,如果出现下面的内容则说明添加成功🚀
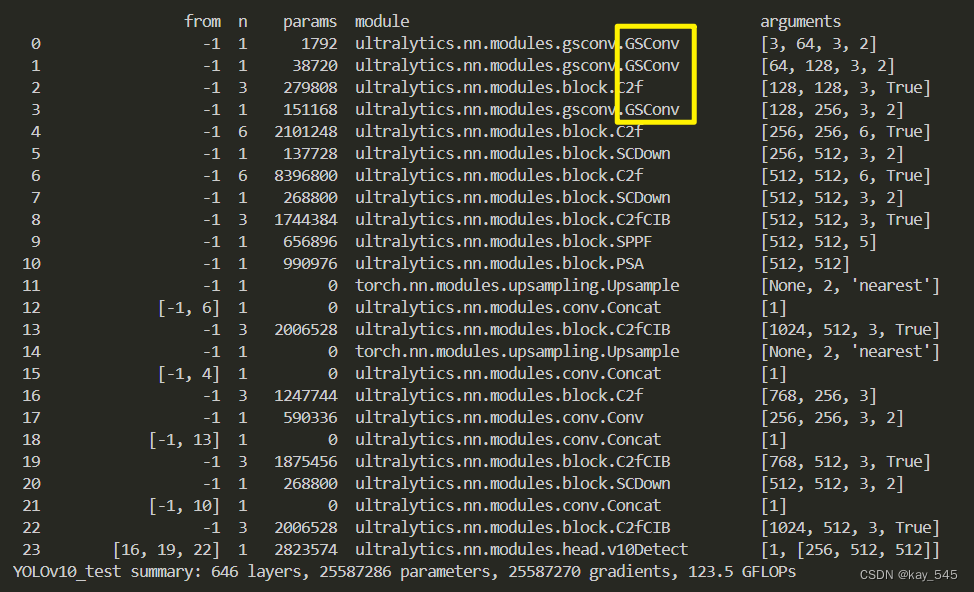
3. 完整代码分享
https://pan.baidu.com/s/1eP_v-IFz2ni2oqGA2GslGg?pwd=aa9k提取码: aa9k
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的YOLOv10l GFLOPs
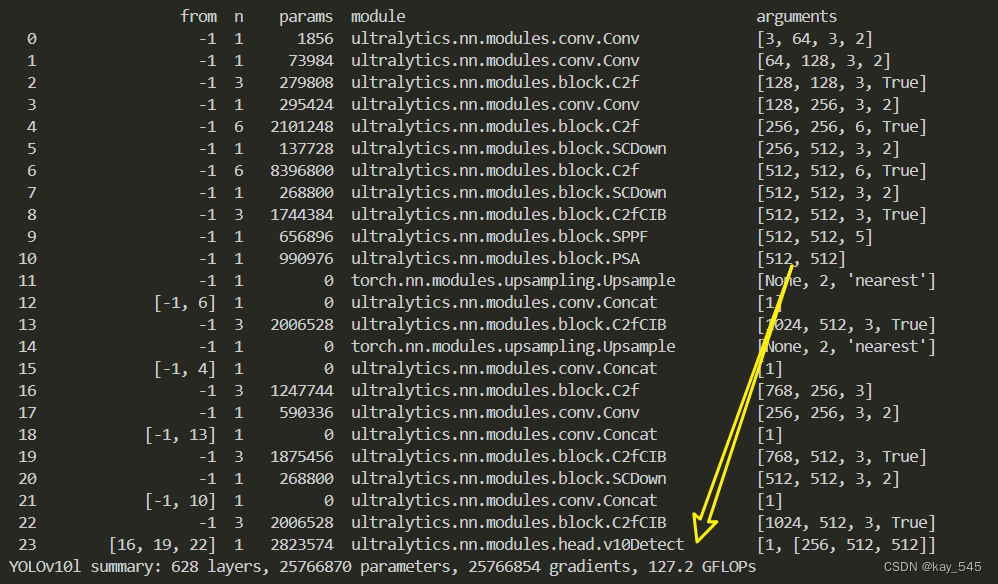
改进后的GFLOPs
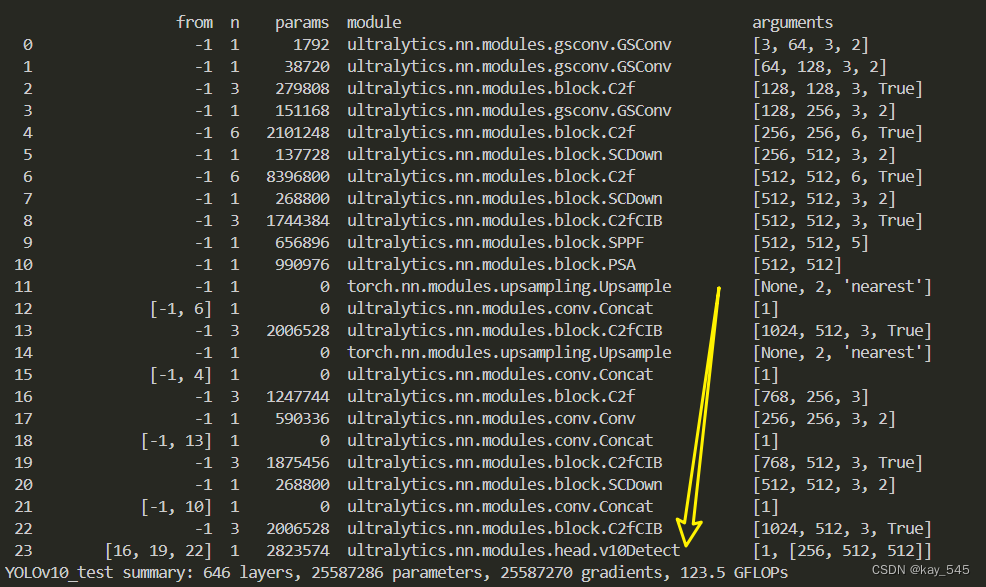
5. 进阶
可以结合损失函数或者注意力机制进行多重改进
6. 总结
GSCONV(Generalized Shuffle Convolution)是一种创新的轻量级卷积技术,旨在解决深度可分离卷积(DSC)在信息分离方面存在的缺陷,同时保持模型的精度和效率。GSCONV 通过结合标准卷积(SC)和 DSC,并引入 shuffle 操作,实现了通道信息的有效融合,从而克服了 DSC 的局限性。具体来说,GSCONV 首先使用 SC 进行通道密集的卷积操作,保留通道间的信息连接,然后通过 shuffle 操作将 SC 的输出与 DSC 的输出进行混合,实现通道信息的均匀融合。这种设计不仅保留了 SC 的特征提取能力,还降低了 DSC 的计算成本,实现了精度与速度的平衡。GSCONV 的优势使其成为构建轻量级目标检测模型的一种有效选择,尤其适用于自动驾驶汽车和边缘计算设备等对实时性和精度要求较高的场景。

















 2960
2960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











