







秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录 :《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 | 目前已有90+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
本文介绍了网络设计中“星运算”(逐元素乘法)的潜力,这一操作能在不增加网络规模的情况下,实现输入到高维非线性特征空间的映射。StarNet模型,结构紧凑、高效,展现了出色的性能和低延迟,展示了星运算广阔的应用前景。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
1.原理

论文地址:Rewrite the Stars⭐ ——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
StarNet的主要原理可以总结如下:
StarNet的核心思想
-
星操作(Star Operation):
-
星操作是指元素级乘法(element-wise multiplication),用于融合不同子空间的特征。
-
这种操作能够将输入特征映射到高维非线性特征空间,类似于核技巧(kernel tricks),而不需要增加网络的宽度(通道数)。
-
-
高维非线性特征映射:
-
星操作通过元素级乘法生成一个新的特征空间,这个特征空间具有大约((d\sqrt{2})^2)个线性独立的维度。
-
这种操作与传统神经网络通过增加网络宽度来获得高维特征的方式不同,更像是多项式核函数(polynomial kernel functions)的操作。
-
-
高效的紧凑网络结构:
-
通过堆叠多个星操作层,每一层都显著增加隐含的维度复杂度。
-
即使在紧凑的特征空间中操作,星操作仍然能够利用隐含的高维特征。
-
-
性能和效率:
-
星操作在性能和效率上表现出色,尤其是在网络宽度较小的情况下。
-
StarNet使用星操作设计了一个简单但高效的网络结构,证明了其在紧凑网络中的有效性。
-
StarNet的实现
网 络结构:
-
StarNet通过堆叠多层星操作层构建

- 星操作层的基本形式为
,即通过元素级乘法融合两个线性变换后的特征。
理 论分析和实验验证:
-
通过理论分析证明了星操作能够在一个层内将输入特征映射到一个高维非线性特征空间,并且在多层堆叠下能够递归地显著增加隐含的特征维度。
-
实验结果表明,StarNet在ImageNet-1K验证集上的表现优于许多精心设计的高效模型,并且在实际应用中具有较低的延迟和较高的运行效率。
比较与优势:
-
与现有的高效网络设计相比,StarNet没有复杂的设计和超参数调优,仅依赖于星操作的高效性。
-
StarNet的设计理念与传统方法(如卷积、线性层和非线性激活的结合)有明显的不同,强调利用隐含的高维特征来提升网络效率。
综上所述,StarNet通过星操作实现了在紧凑网络中的高效性和高性能,展示了元素级乘法在特征融合中的巨大潜力和应用前景。
2. 将C3_Star_CAA添加到yolov5网络中
2.1 C3_Star_CAA代码实现
关键步骤一: 将下面的代码粘贴到\yolov5\models\common.py中
class CAA(nn.Module):
def __init__(self, ch, h_kernel_size=11, v_kernel_size=11) -> None:
super().__init__()
self.avg_pool = nn.AvgPool2d(7, 1, 3)
self.conv1 = Conv(ch, ch)
self.h_conv = nn.Conv2d(ch, ch, (1, h_kernel_size), 1, (0, h_kernel_size // 2), 1, ch)
self.v_conv = nn.Conv2d(ch, ch, (v_kernel_size, 1), 1, (v_kernel_size // 2, 0), 1, ch)
self.conv2 = Conv(ch, ch)
self.act = nn.Sigmoid()
def forward(self, x):
attn_factor = self.act(self.conv2(self.v_conv(self.h_conv(self.conv1(self.avg_pool(x))))))
return attn_factor * x
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class Star_Block(nn.Module):
def __init__(self, dim, mlp_ratio=3, drop_path=0.):
super().__init__()
self.dwconv = Conv(dim, dim, 7, g=dim, act=False)
self.f1 = nn.Conv2d(dim, mlp_ratio * dim, 1)
self.f2 = nn.Conv2d(dim, mlp_ratio * dim, 1)
self.g = Conv(mlp_ratio * dim, dim, 1, act=False)
self.dwconv2 = nn.Conv2d(dim, dim, 7, 1, (7 - 1) // 2, groups=dim)
self.act = nn.ReLU6()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(x))
x = input + self.drop_path(x)
return x
class Star_Block_CAA(Star_Block):
def __init__(self, dim, mlp_ratio=3, drop_path=0):
super().__init__(dim, mlp_ratio, drop_path)
self.attention = CAA(mlp_ratio * dim)
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(self.attention(x)))
x = input + self.drop_path(x)
return x
class C3_Star_CAA(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(Star_Block_CAA(c_) for _ in range(n)))2.2 C3_Star_CAA的神经网络模块代码解析
C3_Star_CAA模块结合了卷积神经网络和注意力机制
-
继承自
C2f:-
C3_Star_CAA模块继承自一个自定义模块
C3,它可能实现了一种在多个层上进行特征聚合或处理的机制。这个类负责确定模型的结构,比如通道数(c1,c2)、层数(n)、以及是否有快捷连接(shortcut)。虽然C2f的具体行为依赖于其内部实现,但它提供了一个基础框架来堆叠多个模块。
-
-
使用
Star_Block_CAA:-
C3_Star_CAA的核心处理单元是多个
Star_Block_CAA实例。这一块结合了卷积操作、注意力机制(CAA模块)和 dropout(通过DropPath实现)。 -
每个
Star_Block_CAA包含以下内容:-
深度卷积(
dwconv),这是一个空间卷积,但对每个输入通道独立应用。 -
两个单独的逐点卷积(
f1和f2),将通道维度扩展为mlp_ratio倍,用于复杂的通道间交互建模。 -
一个门控机制,其中
f1的输出(经过ReLU6激活)与f2的输出进行逐元素相乘。 -
CAA(通道注意力增强)模块,通过水平和垂直卷积来捕捉通道间的依赖性,增强空间和通道交互。 -
注意力机制的输出通过额外的深度卷积(
dwconv2)和逐点卷积(g)处理。 -
使用
drop_path应用残差连接,这意味着在正则化过程中可能会随机丢弃部分路径。
-
-
-
注意力机制 (
CAA):-
CAA(通道注意力增强)通过平均池化,然后进行逐通道卷积(水平和垂直方向)来建模通道间的依赖关系。最终输出通过 sigmoid 激活函数生成注意力因子,然后与输入特征图相乘。
-
-
C3_Star_CAA的结构:
-
C3_Star_CAA由一系列的
Star_Block_CAA组成,其中n决定了块的数量。快捷连接(shortcut)机制可能会将模块的输入连接到输出,以确保有效的梯度传播,减少梯度消失问题。
-
主要原理:
-
特征注意力:通过结合
CAA模块,模型能够根据空间和通道信息动态地强调重要特征。 -
残差连接:残差连接确保模型能够学习到更深的表示,同时最小化梯度消失的风险。
-
DropPath 正则化:
DropPath机制作为一种随机深度正则化方法,通过在训练过程中随机丢弃部分网络,提升模型的泛化能力。 -
模块化与灵活性:设计是模块化的,层数(
n)、通道数(c1,c2)和扩展比例(mlp_ratio)都可以配置。
总的来说,C3_Star_CAA 结合了 C3结构的灵活性和 Star_Block_CAA 的强大特征学习能力,后者融合了卷积与注意力机制,用于特征提取和精炼。
2.3 新增yaml文件
关键步骤二:在下/yolov5/models下新建文件 yolov5_C3_Star_CAA.yaml并将下面代码复制进去
- 目标检测yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_Star_CAA, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_Star_CAA, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_Star_CAA, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_Star_CAA, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_Star_CAA, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_Star_CAA, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_Star_CAA, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_Star_CAA, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 语义分割yaml文件
# Ultralytics YOLOv5 🚀, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_Star_CAA, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_Star_CAA, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_Star_CAA, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3_Star_CAA, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_Star_CAA, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_Star_CAA, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_Star_CAA, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_Star_CAA, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Segment, [nc, anchors, 32, 256]], # Segment (P3, P4, P5)
]
2.4 注册模块
关键步骤三:在yolo.py的parse_model函数替换添加C3_Star_CAA

2.5 执行程序
在train.py中,将cfg的参数路径设置为yolov5_C3_Star_CAA.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments
0 -1 1 7040 models.common.Conv [3, 64, 6, 2, 2]
1 -1 1 73984 models.common.Conv [64, 128, 3, 2]
2 -1 3 402112 models.common.C3_Star_CAA [128, 128, 3]
3 -1 1 295424 models.common.Conv [128, 256, 3, 2]
4 -1 6 2934528 models.common.C3_Star_CAA [256, 256, 6]
5 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
6 -1 9 16896256 models.common.C3_Star_CAA [512, 512, 9]
7 -1 1 4720640 models.common.Conv [512, 1024, 3, 2]
8 -1 3 23631360 models.common.C3_Star_CAA [1024, 1024, 3]
9 -1 1 2624512 models.common.SPPF [1024, 1024, 5]
10 -1 1 525312 models.common.Conv [1024, 512, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 3 6245120 models.common.C3_Star_CAA [1024, 512, 3, False]
14 -1 1 131584 models.common.Conv [512, 256, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 3 1598848 models.common.C3_Star_CAA [512, 256, 3, False]
18 -1 1 590336 models.common.Conv [256, 256, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 3 5982976 models.common.C3_Star_CAA [512, 512, 3, False]
21 -1 1 2360320 models.common.Conv [512, 512, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 3 23631360 models.common.C3_Star_CAA [1024, 1024, 3, False]
24 [17, 20, 23] 1 457725 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [256, 512, 1024]]
YOLOv5_C3_Star_CAA summary: 962 layers, 94290109 parameters, 94290109 gradients, 234.7 GFLOPs3. 完整代码分享
https://pan.baidu.com/s/1S_hsjIOaj9jANdtl-HSlQg?pwd=6r52提取码: 6r52
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
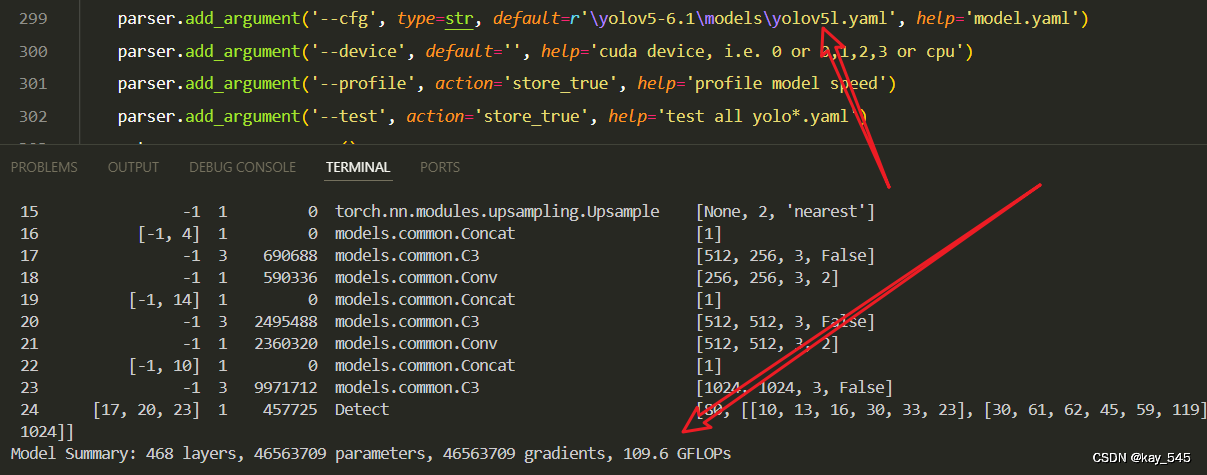
改进后的GFLOPs

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
StarNet通过引入一种称为星操作(Star Operation)的核心创新,实现了在紧凑网络中高效处理图像的目标。星操作通过两个线性变换后的特征进行元素级乘法,生成一个高维非线性特征空间,类似于多项式核函数的效果。StarNet采用一个四阶段的分层架构,每个阶段通过卷积层下采样分辨率并增加通道数,从而逐步抽象图像特征。每个网络块中使用深度卷积、批量归一化和ReLU6激活函数,简化设计以提高效率。通道扩展固定为4倍,网络宽度在每个阶段翻倍,以平衡计算负载和学习能力。通过标准的训练方法和推理时融合批量归一化层,StarNet在ImageNet-1K等基准测试中展示了其简单设计下的高效性能,表现出色。综上所述,StarNet通过巧妙的特征融合策略和高效的网络结构,在保持低计算复杂度的同时,实现了卓越的图像处理性能。

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











