







在深度学习中,优化目标(object function)就是损失函数,希望找到损失最小时对应的参数。
上面提到要让损失最小,这个“最小”有2种,一种是全局最小,一种是局部最小。一般我们使用迭代算法求解,所以一般只能保证找到局部最小。但有特例,比如:凸函数(和一个碗一样),凸优化问题中,局部最小一定是全局最小。但是凸优化问题很少,凸:线性回归,softmax回归,凸函数模型的拟合能力有限;非凸:MLP,CNN,RNN,attention。
下面讲一下各种优化算法。
梯度下降(最简单的迭代求解算法),下图中的x是学习的参数,f是损失,梯度下降的不足:更新参数的时候需要计算损失,计算损失需要样本,梯度下降用到的是所有样本,这样求导很贵!因此有了SGD随机梯度下降。学习率后面乘的是所有样本梯度的均值。

随机梯度下降,每次计算损失只用到一个样本,求梯度只需要用到一个样本。学习率后面乘的是单个样本的梯度。
真正用到的是小批量随机梯度下降,因为随机梯度下降每次只用到一个样本,对硬件资源利用不充分(硬件是可以并行的)。每次更新参数的时候,随机采样一个样本子集,假设这个批量大小为b,学习率后面乘的是b个样本的梯度均值。
权重参数更新的时候,经常见到冲量法:冲量法使用平滑过的梯度对权重更新。维护一个冲量(维护一个惯性,看表达式)。冲量法好处:梯度下降不会抖动的很厉害。

还有一类经常使用的算法:Adam。小批量梯度下降+冲量法效果很好,可以不用Adam。为什么使用Adam?对学习率不敏感,很平滑,不想调参可以用。
Adam算法的:对梯度
平滑。见下图,看
的展开式,相当于给过去的梯度做了一个加权和,所有权的总和为1。t比较大的时候,
趋近于1,但t比较小的时候,
趋于0,所以t小的时候有一个修正。

Adam算法的:对
平滑。见下图,
是向量,
是对每个元素平方。
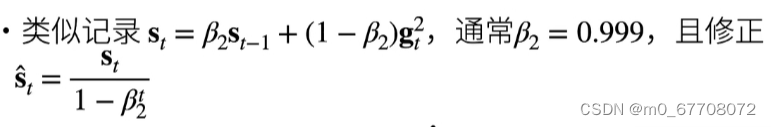
利用更新参数:
的分子让梯度平滑,分母类似于归一化,让
的值处于一定范围。
















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









