









1.实验目的
- 会用Python创建多分类SVM模型;
2.使用多分类SVM模型对手写体数字图片分类;
3.会对分类结果进行评价。
2. 设备与环境
Jupyter notebook
3.实验原理

4.实验内容
使用sklearn.svm类对手写体数字图片进行分类
训练数据:digits_training.csv
测试数据:digits_testing.csv
第1列是类别,其他列是特征属性。
先对1类和2类的数据进行计算,得到1类和2类的分割超平面,然后对2类和3类的数据进行计算,以此类推,直到两两类别分别完成计算。
在用模型做预测时,对两两类别之间的分割超平面分别进行匹配,统计有多少次判别将其华分类1类,多少次判别为2类…,判定所属类别次数最多的就是最后预测的类别。
- 载入训练数据、分出特征属性和类别,对特征属性标准化,显示读入数据的行数
xTrain = trainData[:,1:Ntrain]
yTrain = trainDta[:,0]
标准化函数
Def normalizeData(X):
Return (X – X.mean())/X.max()
2.训练多分类SVM模型
Model = svm.SVC(decision_function_shape=’ovo’)
3.保存训练模型名字为“svm_classifier_modell.m”
4.载入测试数据,分出特征属性和类别,对特征属性标准化,显示读入是数据的行数
5.使用模型对测试集进行预测,显示预测错误数据的数目、预测数据的准确率和模型内建正确率
5.实验结果分析
6.代码
import pandas as pd
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
print("载入训练数据,对数据进行标准化处理.....")
# 1. 载入训练数据、分出特征属性和类别,对特征属性标准化,显示读入数据的行数
train_data = pd.read_csv(r'D:\D\Download\360安全浏览器下载\digits_training.csv')
N_train = train_data.shape[1] # 特征数量
x_train = train_data.iloc[:, 1:N_train].values # 特征属性
y_train = train_data.iloc[:, 0].values # 类别
# # 标准化函数
# def normalize_data(X):
# return (X - X.mean()) / X.max()
# x_train = StandardScaler().fit_transform(x_train) # 标准化特征属性
# 标准化特征属性
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
# PCA降维
pca = PCA(n_components=0.85) # 保留85%的方差
x_train_pca = pca.fit_transform(x_train_scaled)
print("训练数据:", len(train_data), "条")
# 2. 训练多分类SVM模型
print("训练模型...")
model = svm.SVC(decision_function_shape='ovo')
model.fit(x_train_pca, y_train)
print("保存模型...")
# 3. 保存训练模型名字为“svm_classifier_model.m”
model_name = "svm_classifier_model.m"
import joblib
joblib.dump(model, model_name)
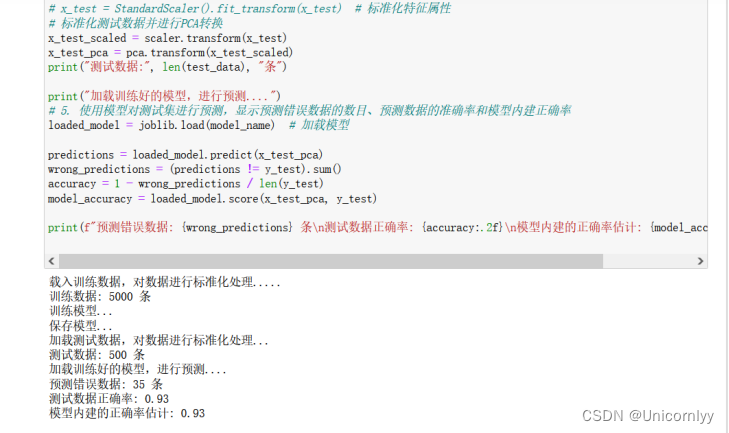
print("加载测试数据,对数据进行标准化处理...")
# 4. 载入测试数据,分出特征属性和类别,对特征属性标准化,显示读入数据的行数
test_data = pd.read_csv(r'D:\D\Download\360安全浏览器下载\digits_testing.csv')
N_test = test_data.shape[1] - 1 # 特征数量
x_test = test_data.iloc[:, 1:N_test + 1].values # 特征属性
y_test = test_data.iloc[:, 0].values # 类别
# x_test = StandardScaler().fit_transform(x_test) # 标准化特征属性
# 标准化测试数据并进行PCA转换
x_test_scaled = scaler.transform(x_test)
x_test_pca = pca.transform(x_test_scaled)
print("测试数据:", len(test_data), "条")
print("加载训练好的模型,进行预测....")
# 5. 使用模型对测试集进行预测,显示预测错误数据的数目、预测数据的准确率和模型内建正确率
loaded_model = joblib.load(model_name) # 加载模型
predictions = loaded_model.predict(x_test_pca)
wrong_predictions = (predictions != y_test).sum()
accuracy = 1 - wrong_predictions / len(y_test)
model_accuracy = loaded_model.score(x_test_pca, y_test)
print(f"预测错误数据: {wrong_predictions} 条\n测试数据正确率: {accuracy:.2f}\n模型内建的正确率估计: {model_accuracy:.2f}\n")

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











