






目录
四、 Batch Normalization 确实能帮助我们更好地训练神经网络
摘要
Batch Normalization (BN) 是一种深度神经网络训练中的优化方法,通过规范化每一层的输出,使其均值为0,方差为1,降低了模型对初始化权重的敏感度,加快了训练速度。BN通过减少内部协变量偏移,降低了梯度消失、爆炸的问题,使得模型能够使用更高的学习率,提高了模型的泛化能力。
ABSTRACT
Batch Normalization (BN) is an optimization technique in deep neural network training. By normalizing the output of each layer to have a mean of 0 and variance of 1, BN reduces the model's sensitivity to weight initialization and accelerates training. BN mitigates internal covariate shift, decreasing the issues of gradient vanishing and explosion, allowing the model to utilize higher learning rates and enhancing the model's generalization capability.
一、Changing Landscape
Batch Normalization就是其中一个把崎岖的error surface变平滑的想法。Batch Normalization,批标准化,和普通的数据标准化类似,是将分散的数据统一的一种做法, 也是优化神经网络的一种方法,具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律。
不要小看 optimization 这个问题,有时候就算你的error surface就是一个碗的形状,也不见得就很好训练。
假设你的现在有一个模型的error surface如下所示,它的两个参数分别是w1 和w2 ,假设w1
是横轴方向,w2是纵轴方向,那么你可以看到这两个参数对 Loss 的斜率差别非常大,在 w1
这个方向上面斜率变化很小,在 w2 这个方向上面斜率变化很大。
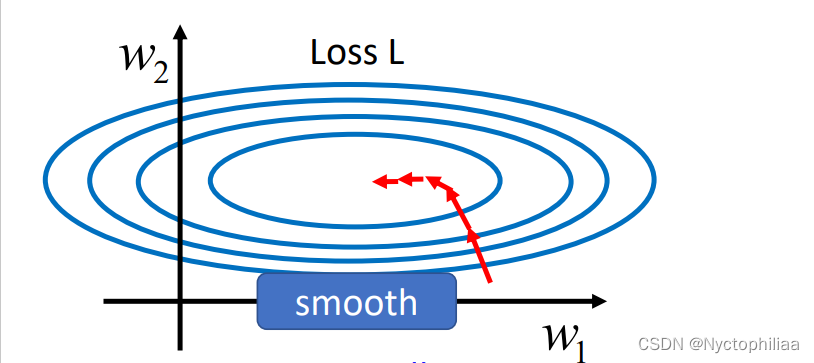 如果是固定的 learning rate,你可能很难得到好的结果,这也正是我们上一节提出adaptive learning rate的原因。但现在我们要试着从另一个角度来解决问题,直接把不好训练的 error surface 改掉,看能不能够改得好做一点。
如果是固定的 learning rate,你可能很难得到好的结果,这也正是我们上一节提出adaptive learning rate的原因。但现在我们要试着从另一个角度来解决问题,直接把不好训练的 error surface 改掉,看能不能够改得好做一点。
在做这件事之前,也许我们第一个要问的问题就是,这种w1跟 w2的斜率差很多的状况到底是怎么出现的。还是用一个例子来说明这件事,假设我们现在有一个非常简单的 linear model,没有 activation function,它的输入是 x1跟x2,它对应的参数是 w1跟 w2 ,如下所示:w1乘 x1,w2 乘 x2,再加上 b 以后就得到 y,然后会计算 y 跟之间的差距当做 e,把所有 training data 的 e 加起来就得到Loss。
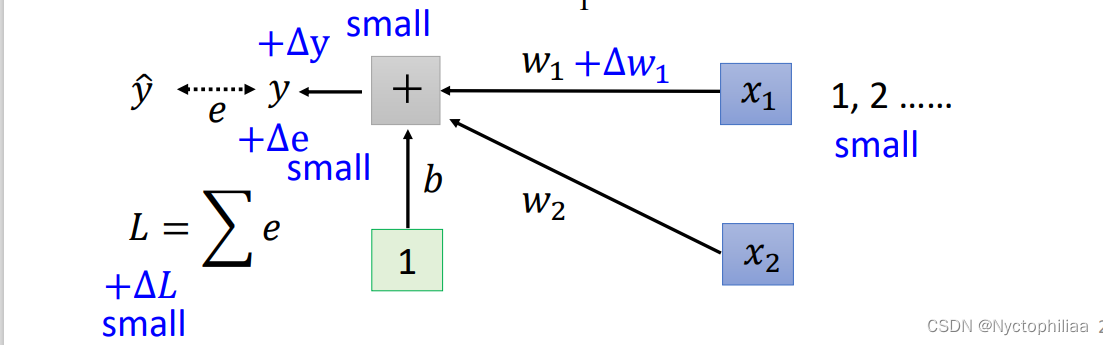
那在怎样的状况下我们会产生像上面那样比较不好 train 的 error surface 呢?
当我们对 w1有一个小小的改变,比如说加上 delta w1的时候,输出的y就会改变,而y的改变又会导致e的改变,最终导致改变了L。这时我们可能会发现,由于x1 会直接乘上 w 1 在 delta w1 不变的情况下,如果x1本身的数量级很大,那么算出的delta就很大,w1 在 error surface 上的斜率就大;如果x1 本身的数量级很小,那么算出的delta就很小,w1在 error surface 上的斜率就小。

所以我们发现在这个 linear 的 model 里面,当我们 input 的 feature,每一个 dimension 的 scale 差距很大的时候,我们就可能产生不同方向坡度非常不同的 error surface。所以一个很自然的想法是:如果我们可以让不同的dimension拥有同样的scale的话,那我们就有可能产生比较容易训练的error surface。这个想法的实现方法就是接下来要提到的Feature Normalization。
二、Feature Normalization
以下所讲的方法只是 Feature Normalization 的一种可能性,并不是 Feature Normalization 的全部,假设 x1 到xR是我们所有的训练资料的feature vector。
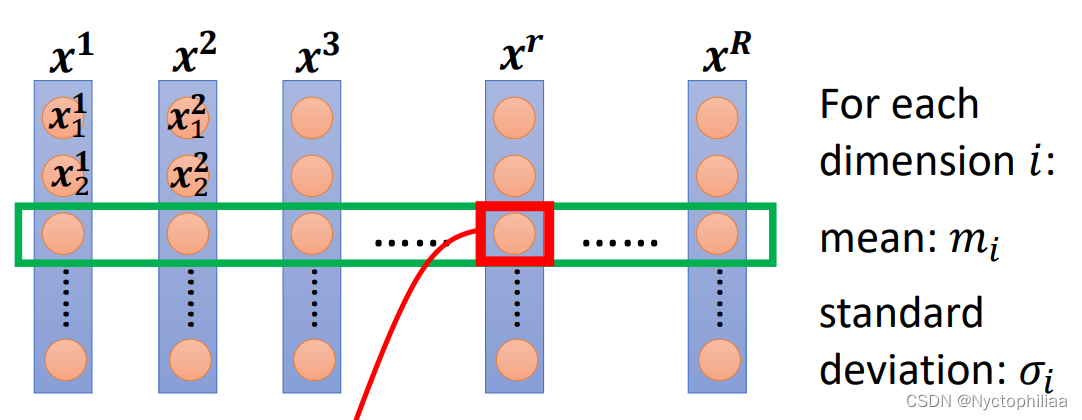
我们把不同笔资料即不同 feature vector的同一个 dimension 里的数值全部取出来(在图中以第i行为例),然后去计算这些数值的平均值mi,再计算它们的标准差,接下来我们来做normalization (也叫standardization):

得到新的数值叫做 ,再用新的数值替换原来位置上的数值。
那做完 normalize 以后有什么好处呢?
做完 normalize 以后,这个 dimension 上面数值的平均值为 0,方差为1,所以这一排数值的分布就都会在 0 上下。
对每一个 dimension都做一样的 normalization,就会发现所有 feature 不同 dimension 的数值都在 0 上下,这样就更可能产生比较容易训练的error surface
三、考虑深度学习的情况
网络的输入经过我们的feature normalization处理之后,数值的分布就很相近了,但在经过网络的第一层之后,也就是这边得到的a1 a2 a3,又需要作为下一层的输入,而对于下一层来说,这里的a1 a2 a3的数值的分布仍然可能又有了很大的差异。对 w2 来说,这边的 a 或 z 其实也是一种 feature,我们应该要对这些 feature 也做 normalization。
接下来你可能会注意到一件有趣的事情,在我们没有对 z zz 做Feature Normalization的时候,如果你改变了 z1 的值,你只会影响到后面a1 的值。
但是现在呢,这边的 μ 跟 σ ,它们其实都是根据 z1 z2 z3 算出来的,当你改变 z1的值的时候,μ 跟 σ 也会跟着改变,μ跟 σ改变以后,a1 a2 a3 的值都会跟着改变。
所以之前,我们每一个 ,
,
,都是独立分开处理的,但是我们在做 Feature Normalization 以后,这三个值却变得彼此关联了,整个系统成为了一个比较大的network。
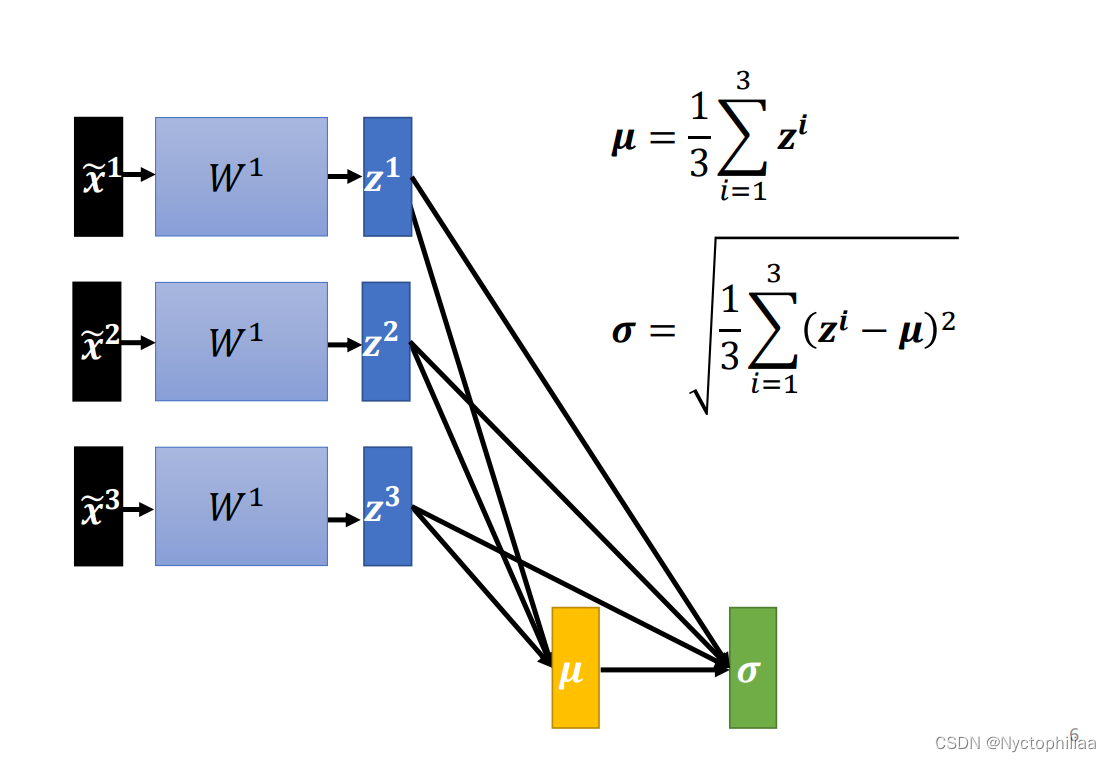
接下来就会有一个问题了,因为你的训练资料里面的 data 非常多,现在一个 data set 动不动就有上百万笔资料, GPU 的 memory 根本没有办法把整个 data set 的 data 都 load 进去。
所以在实践过程中,我们不会让这一个 network 考虑整个 training data 里面的所有 data,我们只考虑一个 batch 里面的 data,举例来说,batch size 设为 64,那这个巨大的 network,就是把 64 笔 data 读进去,算这 64 笔 data 的 μ μμ,算这 64 笔 data 的 σ \sigmaσ,对这 64 笔 data 都去做 normalization。这就是Batch Normalization名字的由来。
但这里又有另一个问题,就是我们一定要有一个够大的 batch,你才算得出比较有用的 μ 跟 σ ,举个极端一点的例子,假如我们的 batch size 设为 1,那你其实就没有什么 μ或 σ 可以算,也没什么意义。换句话说,这里的 μ跟 σ是两个统计量,我们在一个batch上统计这两个量,希望它能够代表整个data set的情况,所以你的batch一定不能太小,不然就不具有代表性。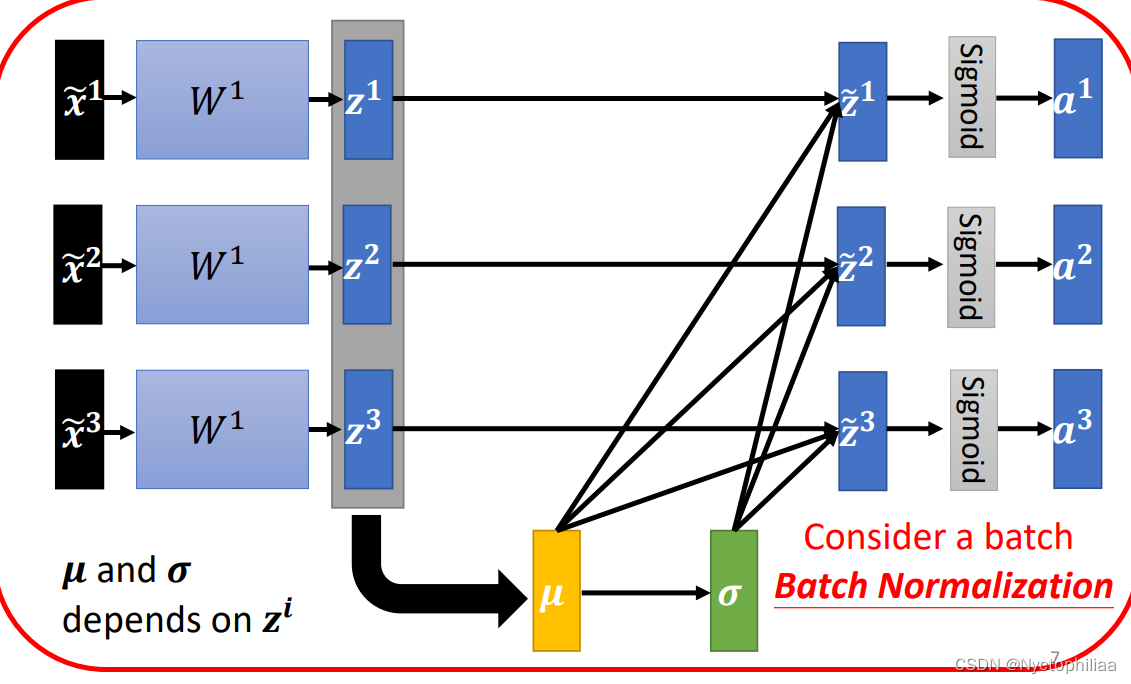
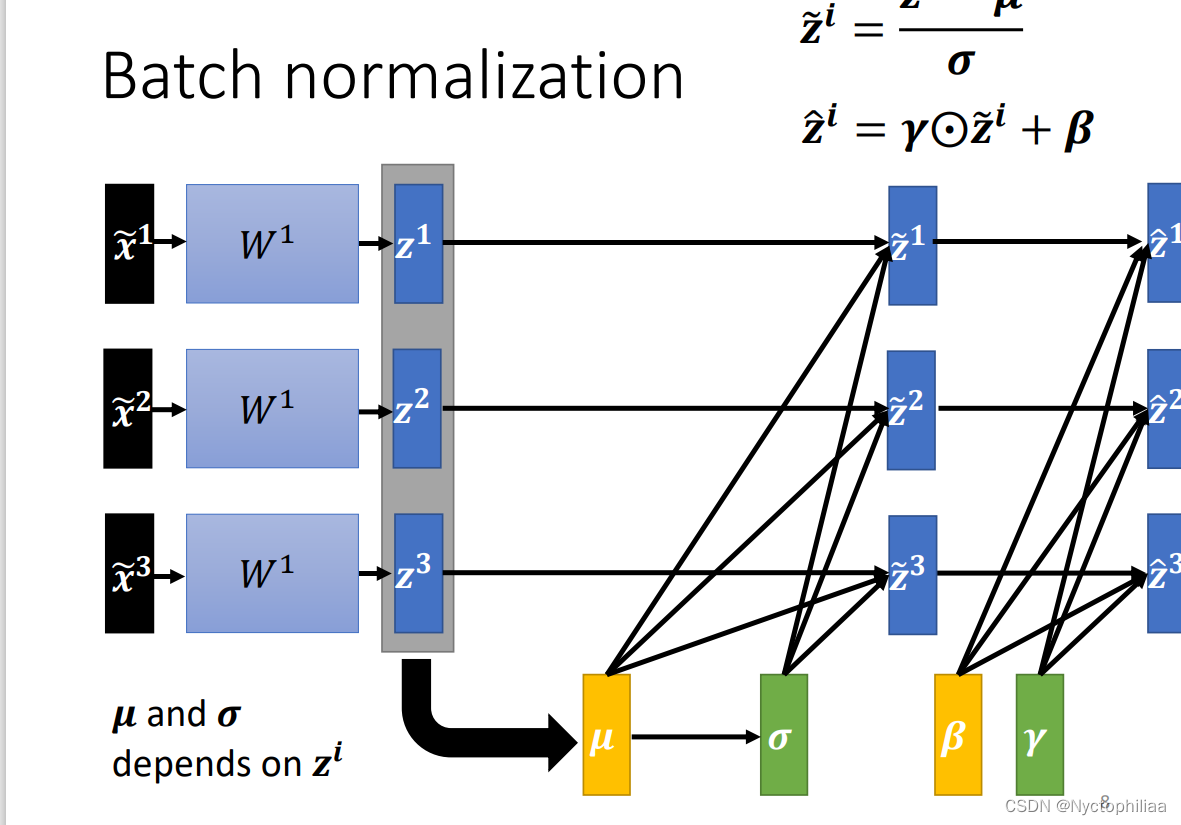
在做 Batch Normalization 的时候,往往还会有这样的设计,在你算出这个以后:
接下来你会把这个 再乘上另外一个向量叫做
,就是把
这个向量里面的element,跟
这个向量里面的对应位置的element两两做相乘。最后再加上β这个向量,得到
这里的 β 跟,可以把它想成是 network 的参数,它们是另外再被learn出来的。
四、 Batch Normalization 确实能帮助我们更好地训练神经网络
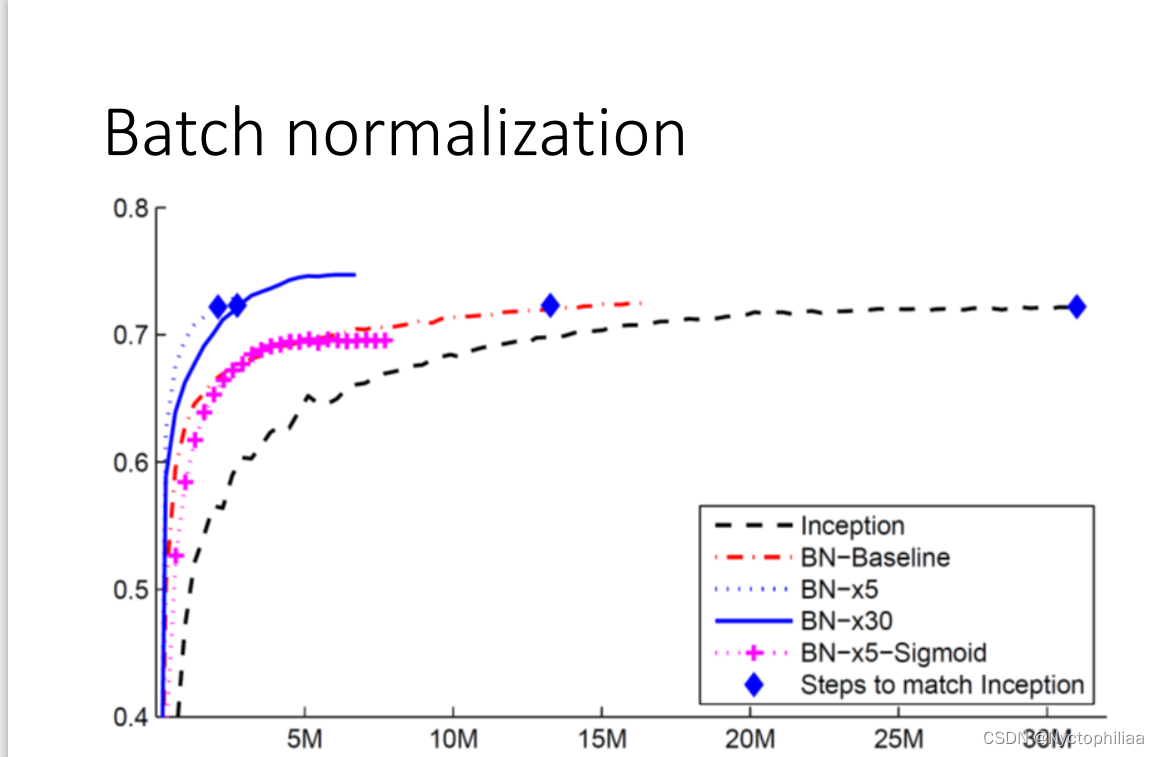
横轴代表的是训练的过程,纵轴代表的是训练出的模型在 validation set 上面的 accuracy
黑色的虚线是没有做 Batch Normalization 的结果,它用的是 inception 的 network,是一种以 CNN 为基础的 network 架构。
如果做了Batch Normalization,你会得到红色的这一条虚线(BN-Baseline),可以发现初期红色虚线训练的速度显然比黑色的虚线快很多,可以看到红色的虚线只用了不到一半的时间就达到了和黑色虚线一样的accuracy。
蓝色的实线(BN-x5)跟这个蓝色的虚线(BN-x30),是把 learning rate 设大一点,x5和x30分别表示learning rate 是原来的 5 倍或30倍。
有一个加号表示的虚线(BN-x5-Sigmoid),是使用 sigmoid 生成了原本比较不好train的 error surface,加上 Batch Normalization 之后还是能够 train 的起来。
五、: COVID-19 每天的病例预测
一、一些实用函数
def same_seed(seed):
'''Fixes random number generator seeds for reproducibility.'''
# 使用确定的卷积算法 (A bool that, if True, causes cuDNN to only use deterministic convolution algorithms.)
torch.backends.cudnn.deterministic = True
# 不对多个卷积算法进行基准测试和选择最优 (A bool that, if True, causes cuDNN to benchmark multiple convolution algorithms and select the fastest.)
torch.backends.cudnn.benchmark = False
# 设置随机数种子
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
def train_valid_split(data_set, valid_ratio, seed):
'''Split provided training data into training set and validation set'''
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)
def predict(test_loader, model, device):
# 用于评估模型(验证/测试)
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
# device (int, optional): if specified, all parameters will be copied to that device)
x = x.to(device) # 将数据 copy 到 device
with torch.no_grad(): # 禁用梯度计算,以减少消耗
pred = model(x)
preds.append(pred.detach().cpu()) # detach() 创建一个不在计算图中的新张量,值相同
preds = torch.cat(preds, dim=0).numpy() # 连接 preds
return preds二、Neural Network Model
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x三、Training Loop
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# TODO: Please check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
# TODO: L2 regularization (optimizer(weight decay...) or implement by your self).
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=config['momentum']) # 设置 optimizer 为SGD
writer = SummaryWriter() # Writer of tensoboard.
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = [] # 初始化空列表,用于记录训练误差
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True) # 让训练进度显示出来,可以去除这一行,然后将下面的 train_pbar 改成 train_loader(目的是尽量减少 jupyter notebook 的打印,因为如果这段代码在 kaggle 执行,在一定的输出后会报错: IOPub message rate exceeded...)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x) # 等价于 model.forward(x)
loss = criterion(pred, y) # 计算 pred 和 y 的均方误差
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record)
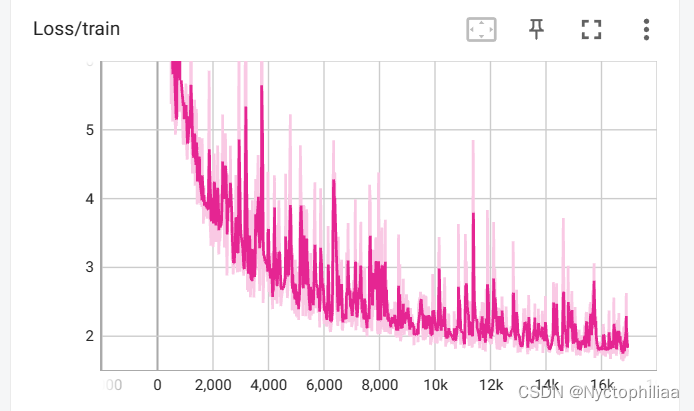
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = [] # 初始化空列表,用于记录验证误差
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
# writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return四、训练集和验证集上的结果
总结
BN通过减少内部协变量偏移,有助于解决梯度消失和爆炸的问题,从而允许使用更高的学习率。BN在诸如卷积神经网络(CNN)、循环神经网络(RNN)和生成对抗网络(GAN)等多种深度学习架构中均有广泛应用。















 2166
2166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









