







如何用AMD显卡部署模型/进行推理
引言
为什么要用AMD显卡进行部署或者推理呢?也许有很多理由比如N卡太贵了、或者公司要求之类的。但不管怎么样,我们的目标就是在linux上用A卡进行推理(本文不涉及windows)。
本文将从两方面进行介绍
- 如何在A卡上是用pytorch
- 如何使用C++调用模型
前置知识
众所周知,使用N卡进行训练或推理的话,首先要有驱动,然后要有cuda。那么A卡同理,驱动是什么应该不用多说,那么A卡下对标cuda的是身儿么东西呢?这个东西AMD官方称之为ROCm。只要装了这个东西,就可以愉快地进行A卡的模型部署以及推理了。
下面,我们首先讲一下如何安装ROCm。
注意,本文是用的环境为7900xtx, ubuntu 22.04.3桌面版,rocm5.7.1。下面将不再赘述,另外由于A卡目前兼容性过差,若读者遵循本文教程无法成功,请去官网查询三者版本是否兼容。本文所提到的内容均已在上述环境下跑通。
如何安装A卡驱动与ROCm
驱动
由于A卡开源的特性,linux的发行版中,基本上都已经集成了A卡驱动。那么这是否意味着我们可以不用做任何操作就可以直接用了呢?答案是否定的。
试想一下,ubuntu一个长期发行版会有五年的官方支持。假设说ubuntu 22.04.3是2022年发布的,硬件厂家在2024年推出了新的驱动。那么2022年的ubuntu 22.04.3该怎么支持这个新的驱动呢?至少在这里,答案是HWE(Hardware Enablement,即硬件支持)。通过升级内核来完成对新的硬件的支持。当然,如果您使用的是较老版本的显卡,请忽略此条。
通过HWE堆栈,Ubuntu LTS用户可以在不升级到新的Ubuntu发行版的情况下获得对新硬件的支持。这对于企业和其他组织来说特别有用,因为它允许它们在不改变系统稳定性的情况下使用新硬件。
上面简述完了原理,那我们来看一下具体怎么操作:
sudo apt install linux-generic-hwe-22.04
说起来很复杂,其实只要上面一行代码即可实现,然后重启一下即可。
在上面这行代码执行之后,应该通过执行 uname -r看到类似下面的输出:

这得注意的是,在执行sudo apt install linux-generic-hwe-22.04这条命令前后,uname -r的输出结果是不一样的,如果不一样,那就说明HWE升级完成。
ROCm
ROCm对标cuda。那么自然会有类似nvcc之类的东西。但我们并不需要了解这是什么。毕竟能用就行了。住需要按照下述步骤执行:
下载ROCm安装程序(如果您要安装其他版本的ROCm,请自行编辑):
curl -O https://repo.radeon.com/amdgpu-install/5.7.1/ubuntu/jammy/amdgpu-install_5.7.50701-1_all.deb
sudo dpkg -i amdgpu-install_5.7.50701-1_all.deb
进行安装:
sudo amdgpu-install --usecase=hiplibsdk,rocm
将用户组添加到video与render组(这一条不知道为什么,如果您有足够的精力,也许可以试一试不执行这个步骤会发生什么,欢迎您的留言):
sudo usermod -aG video $USER
sudo usermod -aG render $USER
最后重启,即可完成rocm的安装。如果一切顺利的话,执行rocminfo将会出现如下界面:
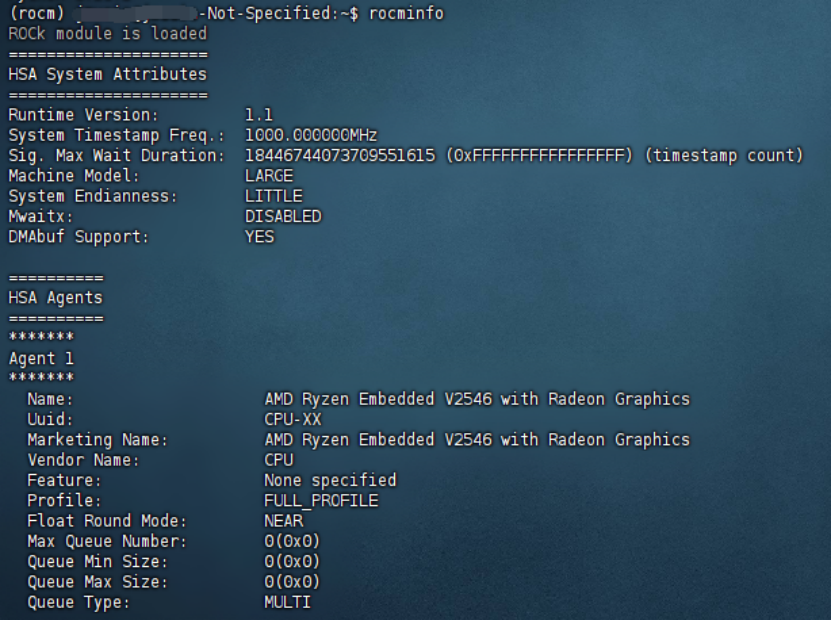
由于我手上的服务器cpu也是amd的,也许上图中是核显,请忽略。或者您也可以输入dpkg -l | grep rocm,通过查看rocm版本检查是否安装成功:
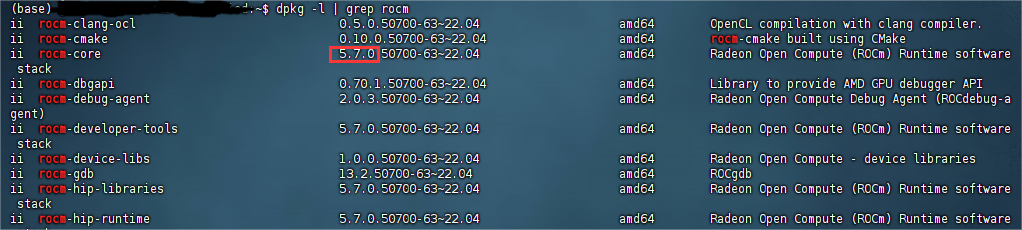
驱动与rocm安装完成
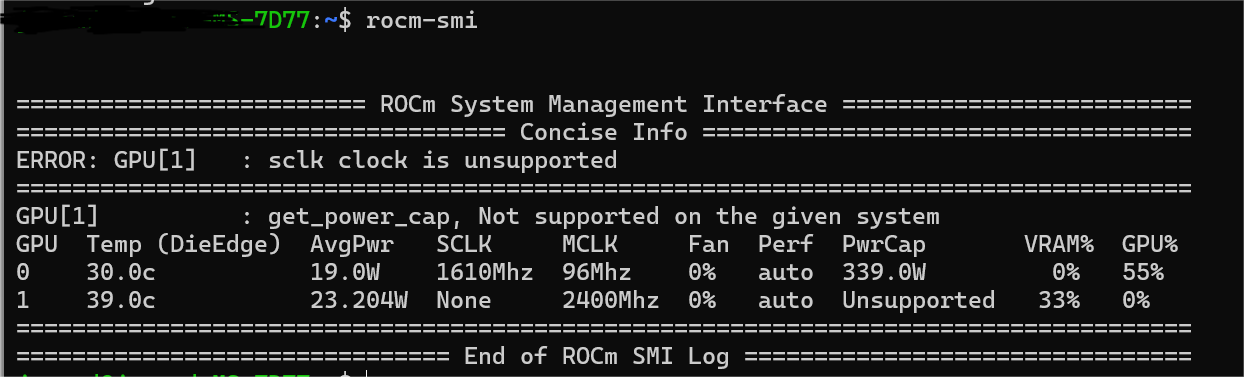
如果一切顺利的话,现在您执行rocm-smi会出现类似nvidia-smi的界面,如下图:
如何使用pytorch
首先我们要知道,pytorch 是用 python 其实只是一个兼容层,底层还是用 C(或者说 cuda,反正是对硬件的调用,怎么理解都可以)来写的。因此,我们只需要安装兼容 ROCm 版本的 pytorch 即可。
下面我们将简单介绍如何安装兼容 ROCm 版本的 pytorch、如何检查是否能够调用 A 卡。
如何安装兼容 ROCm 版本的 pytorch
前置的如何安装 python、conda 等,此处已默认您有相应的基础知识,此处不再赘述。假设您已经有了python 环境,那么只需要一行代码即可安装:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.7
当然,假设您的服务器无法联网,也可以自行将文件下载后本地安装,可以参考下面的代码:
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-5.7/torch-2.0.1%2Brocm5.7-cp310-cp310-linux_x86_64.whl
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-5.7/torchvision-0.15.2%2Brocm5.7-cp310-cp310-linux_x86_64.whl
pip3 install --force-reinstall torch-2.0.1+rocm5.7-cp310-cp310-linux_x86_64.whl torchvision-0.15.2+rocm5.7-cp310-cp310-linux_x86_64.whl
再次温馨提示,由于 A 卡兼容性较差,请随时确认 ROCm 版本与您使用的显卡是否兼容,假设不兼容的话请去官网翻阅文档进一步确认。作者暂时没有发现那种兼容性表格,因此这一步实在是爱莫能助,还请见谅。
如何检查是否能够调用 A 卡
还记得本节开头说过的话吗,torch 是用 python 只是为了提供一个兼容层。因此,您可以使用下面的代码检查能否调用 A 卡:
torch.cuda.is_available()
如果没问题的话,这一步应当返回 True。也许您会奇怪,不是 ROCm 吗,为什么调用的是 cuda?我个人猜测是因为 pytroch 为了保证对老程序的兼容性而做的改变,反正底层具体调用的什么代码,我们也不知道,完全可以把底层调用的 cuda 换成 rocm 嘛。总之,我个人还是比较喜欢这种风格的写法,毕竟目前的 ROCm 并没有展现出什么不同于 cuda 的能力。
非常重要但是不知道怎么取名字的一段
如果您完成了前述的所有内容,并且torch.cuda.is_available()返回为 True 的情况下,依旧无法进行推理/训练,那么请将下面的代码设置为环境变量:
export PYTORCH_ROCM_ARCH="gfx1100"
export HIP_DEVICE=0
export ROCM_PATH=/opt/rocm
export HIP_VISIBLE_DEVICES=0
export HSA_OVERRIDE_GFX_VERSION=11.0.0
这段代码摘自其他博客,但是由于时间太久我已经找不到出处了,在此说一声抱歉,如果您是原作者欢迎联系我。虽然 7900xtx 是 rdna3 架构,而 gfx1100 是rdna2 架构,但是这段代码能让程序正常运行起来,作者也就没有去深究原因了。由于本段只是提供一个思路,如果您的程序跑不起来,很有可能是环境变量的问题;因此就不再过多赘述了。下面是 chatgpt 对这段代码的解释,仅供参考:
这段代码主要是设置了一些环境变量,通常用于配置 PyTorch 和 ROCm(Radeon Open Compute)的相关参数。让我解释一下每个环境变量的作用:
PYTORCH_ROCM_ARCH="gfx1100":这个变量指定了 ROCm 的架构版本,"gfx1100" 表示 AMD GPU 的 RDNA 2 架构,这是一种针对深度学习任务优化过的 GPU 架构。
HIP_DEVICE=0:这个变量指定了使用的 HIP 设备编号。HIP 是一个类似于 CUDA 的平台,用于在 AMD GPU 上进行并行编程。在这里,设备编号为0意味着使用第一个可用的 HIP 设备。
ROCM_PATH=/opt/rocm:这个变量指定了 ROCm 的安装路径。ROCm 是 AMD 提供的用于支持 GPU 加速计算的开发工具集。
HIP_VISIBLE_DEVICES=0:这个变量类似于 CUDA_VISIBLE_DEVICES,指定了在 HIP 应用程序中可见的设备。这里的值为0,表示只有第一个 HIP 设备可见。
HSA_OVERRIDE_GFX_VERSION=11.0.0:这个变量用于覆盖 HSA(Heterogeneous System Architecture)中 GPU 的版本号。在这里,指定了 GPU 的版本号为11.0.0。
综上所述,这段代码主要是配置了使用 PyTorch 在 ROCm 平台上进行深度学习任务时所需的环境变量。
如何使用C++调用模型
正常情况下,我们应该是用 onnxruntime-gpu 调用显卡进行加速推理,毕竟 A 卡兼容性虽差,但也只是相对于 N 卡来讲,整体而言还是不错的。然而截止到目前,我们没能成功在 7900xtx 上配置好 onnxruntime-gpu 的环境。为此,我们在 ROCm 的文档中发现了MIGraphX(官方文档,GitHub)
下面,我将介绍如何安装MIGraphX,以及MIGraphX的简单使用。
如何安装MIGraphX
以二进制形式安装的话,只需一行代码即可:
sudo apt update && sudo apt install -y migraphx
安装目录将会在/opt/rocm下,比如在作者机器上:

可以看到migraphx目录,至此,我们所需要的全部依赖已经安装完成,下面介绍下如何是用MIGraphX。
如何使用MIGraphX
首先,我们需要知道,MIGraphx,至少经过我的实验,加载的模型是mxr。mxr模型需要由onnx模型转化而来。那么我们就得到了一条很清晰的模型转化路径。通常而言这条路径是pth->onnx->mxr。
如何将pth转化为onnx此处不再赘述,网上已经有了相当多的介绍。我们直接来看onnx如何转化为mxr,但是在此之前,我们需要先知道如何编译。因此,本节将从以下几方面展开:
- 如何编译程序
- 如何将onnx转为mxr
- 如何调用mxr进行推理
如何编译程序
可以参考作者或官方的介绍,首先设置CMakeLists.txt文件:
cmake_minimum_required(VERSION 3.5)
project (CAI)
set (CMAKE_CXX_STANDARD 14)
set (EXAMPLE inception_inference)
list (APPEND CMAKE_PREFIX_PATH /opt/rocm/hip /opt/rocm)
find_package (migraphx)
message("source file: " ${EXAMPLE}.cpp " ---> bin: " ${EXAMPLE})
add_executable(${EXAMPLE} ${EXAMPLE}.cpp)
target_link_libraries(${EXAMPLE} migraphx::c)
然后在该目录下智行以下命令:
mkdir build
cd build
cmake ..
make -j$(nproc)
最后将会生成名为inception_inference的可执行文件,然后就可以愉快的运行了。
值得注意的是,cmake版本似乎不能低于14,否则会不支持。
如何将onnx转为mxr
有了上面的介绍就可以顺利的把代码运行起来了。那么,该如何将onnx转为mxr呢?您可以参考官方github代码,或者参考下面作者自己写的代码:
#include <migraphx/migraphx.hpp>
int main(int argc, char** argv)
{
migraphx::program prog;
migraphx::onnx_options onnx_opts;
// import and parse onnx file into migraphx::program
prog = parse_onnx("your_model.onnx", onnx_opts);
prog.print();
migraphx::target targ = migraphx::target("gpu");
migraphx::compile_options comp_opts;
comp_opts.set_offload_copy();
// compile for the GPU
prog.compile(targ, comp_opts);
// print the compiled program
prog.print();
migraphx::file_options options;
options.set_file_format("msgpack");
migraphx::save(prog, "your_model.mxr", options);
std::cout << "Program has been saved as ./" << "your_model.mxr" << std::endl;
return 0;
}
到这里,您就可以将onnx保存为mxr文件,下面可以愉快的进行推理了。
如何调用mxr进行推理
调用mxr进行推理也是很简单的,只需加载模型,定义输入输出即可。值得注意的是,输入是vector,输出需要自己进行解析,下面是arcface检测人脸的示例代码:
#include <vector>
#include <string>
#include <algorithm>
#include <ctime>
#include <random>
#include <migraphx/migraphx.hpp>
#include <opencv2/opencv.hpp>
#include <chrono>
int main(int argc, char** argv)
{
// 定义如何加载、读取模型
migraphx::program prog;
migraphx::onnx_options onnx_opts;
migraphx::file_options options;
options.set_file_format("msgpack");
std::cout << "************start***************" << std::endl;
prog = migraphx::load("arcface.mxr", options);
std::cout << "************load done***************" << std::endl;
std::srand(unsigned(std::time(nullptr)));
// 定义如何读取图片并转为合适的格式
cv::Mat image = cv::imread("input_arcface.jpg", cv::IMREAD_COLOR);
std::vector<float> input_image;
input_image.reserve(image.channels() * image.rows * image.cols);
for (int k = 0; k < image.channels(); ++k) {
for (int i = 0; i < image.rows; ++i) {
for (int j = 0; j < image.cols; ++j) {
input_image.push_back(static_cast<float>(image.at<cv::Vec3b>(i, j)[k]) / 255.0f);
}
}
}
// 定义输入形状
migraphx::program_parameters prog_params;
auto param_shapes = prog.get_parameter_shapes();
auto input = param_shapes.names().front();
auto start_time = std::chrono::high_resolution_clock::now();
// 循环推理,测试时间
for(int i = 0; i<10; i++){
// 加载输入到显卡
prog_params.add(input, migraphx::argument(param_shapes[input], input_image.data()));
// 推理
auto outputs = prog.eval(prog_params);
// 读取输出
float* results = reinterpret_cast<float*>(outputs[0].data());
// 解析输出,这一段后需要读者自行去处理,此处仅为示例
float* max = std::max_element(results, results + 1000);
int answer = max - results;
std::cout << "##############" << answer << "##############" << std::endl;
}
// 计算时间差并输出总时长
auto end_time = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(end_time - start_time);
std::cout << "Execution Time: " << duration.count() << " microseconds" << std::endl;
}
让我们看看这段代码做了什么(假设我们没有进行循环等额外操作):
首先我们加载了模型,然后我们读取了图片到内存,再后定义输入形状并加载数据到显卡,最后进行推理并读取输出。至此,推理完成。
以上便是本篇博客所有内容。我们首先讲了如何安装ROCm并安装对应的pytorch以进行训练。随后讲了如何安装MIGraphX并进行推理,还说明了为什么不用onnx进行推理。文章多有不足之处,如有不正确的地方,欢迎指正。














 2561
2561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









