






import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import datasets
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
import torchsummary as summary
import os,random,pathlib,copy,warnings
warnings.filterwarnings('ignore')
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
data_dir='D://BaiduNetdiskDownload//深度学习p7'
data_dir1='D://BaiduNetdiskDownload//深度学习p7//Dark//dark (1).png'
#最后的文件名没有空格,导致写错
#data_dir1为后面的图片测试函数的地址
data_dir=pathlib.Path(data_dir)
print('data_dir:',data_dir)
#路径格式没有变化,还是之前的data_dir
data_paths=list(data_dir.glob('*'))
print('data_paths:',data_paths)
#生成windowspath地址
classeNames=[str(path).split('\\')[-1] for path in data_paths]
#目前暂时将'\\'理解为//,两者是等价的
#str后面是path,我写成了data_paths
print("classeNames:",classeNames)
#生成类别名,也就是路径中最后的文件名
#到这一步,算是文件预处理,找到了对应的类别名,完成第一步
train_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
])
test_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225]
)
])
total_data=datasets.ImageFolder(data_dir,transform=train_transforms)
print('total_data:',total_data)
#相当于经过数据预处理,数据已经变成我们想要的总的数据集
classes=list(total_data.class_to_idx)
print('classes:',classes)
train_size=int(0.8*len(total_data))
test_size=int(0.2*len(total_data))
train_dataset,test_dataset=torch.utils.data.random_split(total_data,[train_size,test_size])
print('train_dataset:',train_dataset)
print('test_dataset:',test_dataset)
#搞混了,torch.utils.data写成了torch.utils.dataset
batch_size=32
train_dl=torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
test_dl=torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False
)
#这相当于是第二步,数据预处理,将图片数据处理成对应的数据格式,经过各种变化,生成总体样本集
#然后切分成训练集,测试集
#接着切分成一批批的训练子集和测试子集,为最后实现批量处理做好准备
class vgg16(nn.Module):
def __init__(self):
super(vgg16,self).__init__()
self.block1=nn.Sequential(
nn.Conv2d(3,64,kernel_size=(3,3),stride=(1,1),padding=(1,1)),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=(3,3),stride=(1,1),padding=(1,1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2,2),stride=(2,2))
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.block3 = nn.Sequential(
nn.Conv2d(128,256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
self.classifier=nn.Sequential(
nn.Linear(in_features=512*7*7,out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4)
)
#写错了,将ReLU,写成了ReLU
def forward(self,x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
model=vgg16().to(device)
print('model:',model)
print(summary.summary(model,(3,224,224)))
#用图表形式看一下整体的vgg16结构
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset)
num_batches=len(dataloader)
train_loss,train_acc=0,0
for x,y in dataloader:
x,y=x.to(device),y.to(device)
pred=model(x)
loss=loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()
train_loss+=loss.item()
train_acc/=size
train_loss/=num_batches
return train_acc,train_loss
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batches=len(dataloader)
test_acc,test_loss=0,0
with torch.no_grad():
for x,y in dataloader:
x,y=x.to(device),y.to(device)
pred=model(x)
loss=loss_fn(pred,y)
test_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()
test_loss+=loss.item()
test_acc/=size
test_loss/=num_batches
return test_acc,test_loss
#第三步,构建vgg16完成,其中包含init,forward,train,test
optimizer=torch.optim.Adam(model.parameters(),lr=1e-4)
loss_fn=nn.CrossEntropyLoss()
#写错了,将parameters写成了paramters
#第四步,设置优化器和损失函数
train_acc=[]
test_acc=[]
train_loss=[]
test_loss=[]
epochs=20
best_acc=0
epochs_range=range(epochs)
#早的时候,我会将epoch设置成40,认为次数多,效果就会好,后来发现,很多时候,迭代很多次,也只是在那个范围徘徊罢了
#前20次就能看出总体轮廓了,后面次数越多,也只是增长一点点
#刚开始进行代码调试的时候,我会将epochs设置等于1,进行排查错误,将报错的内容一一修改,等没有错误之后,在将epochs改大
#epochs_range为后面画图做准备
for epoch in epochs_range:
model.train()
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,optimizer)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)
if epoch_test_acc>best_acc:
best_acc=epoch_test_acc
best_model=copy.deepcopy(model)
#把最优的模型拷贝出来,命名为best_model
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr=optimizer.state_dict()['param_groups'][0]['lr']
template=('Epoch:{:2d},train_acc:{:.1f}%,test_acc{:.1f}%,train_loss:{:.3f},test_loss:{:.3f},lr:{:.2e}')
result=template.format(epoch+1,epoch_train_acc*100,epoch_test_acc*100,epoch_train_loss,epoch_test_loss,lr)
print(result)
#.2e目前粗浅理解为科学计数法
#path='./best_model.pth'
#torch.save(model.state_dict(),path)
print('Done')
#第五步,开始设立迭代次数,结果输出格式,开始训练
best_model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,best_model,loss_fn)
print('epoch_test_acc:',epoch_test_acc)
#看看最优模型的准确率
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['figure.dpi']=100
plt.figure(figsize=(20,10))
#写错了,sans-serif写成了sans_serif
plt.subplot(1,2,1)
plt.plot(epochs_range,train_acc,label='training accuracy')
plt.plot(epochs_range,test_acc,label='test accuracy')
plt.legend(loc='lower right')
plt.title('training and test accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,train_loss,label='training loss')
plt.plot(epochs_range,test_loss,label='test loss')
plt.legend(loc='upper right')
plt.title('training and test loss')
plt.show()
def predict_one_image(image_path,model,transform,classes):
test_img=Image.open(image_path).convert('RGB')
test_img.show()
#看一下图片长啥样
test_img=transform(test_img)
img=test_img.to(device).unsqueeze(0)
model.eval()
output=model(img)
_,pred=torch.max(output,1)
#输出的结果为最大的数的列索引
pred_class=classes[pred]
print("预测结果是:",pred_class)
predict_one_image(data_dir1,
model=model,
transform=train_transforms,
classes=classes)
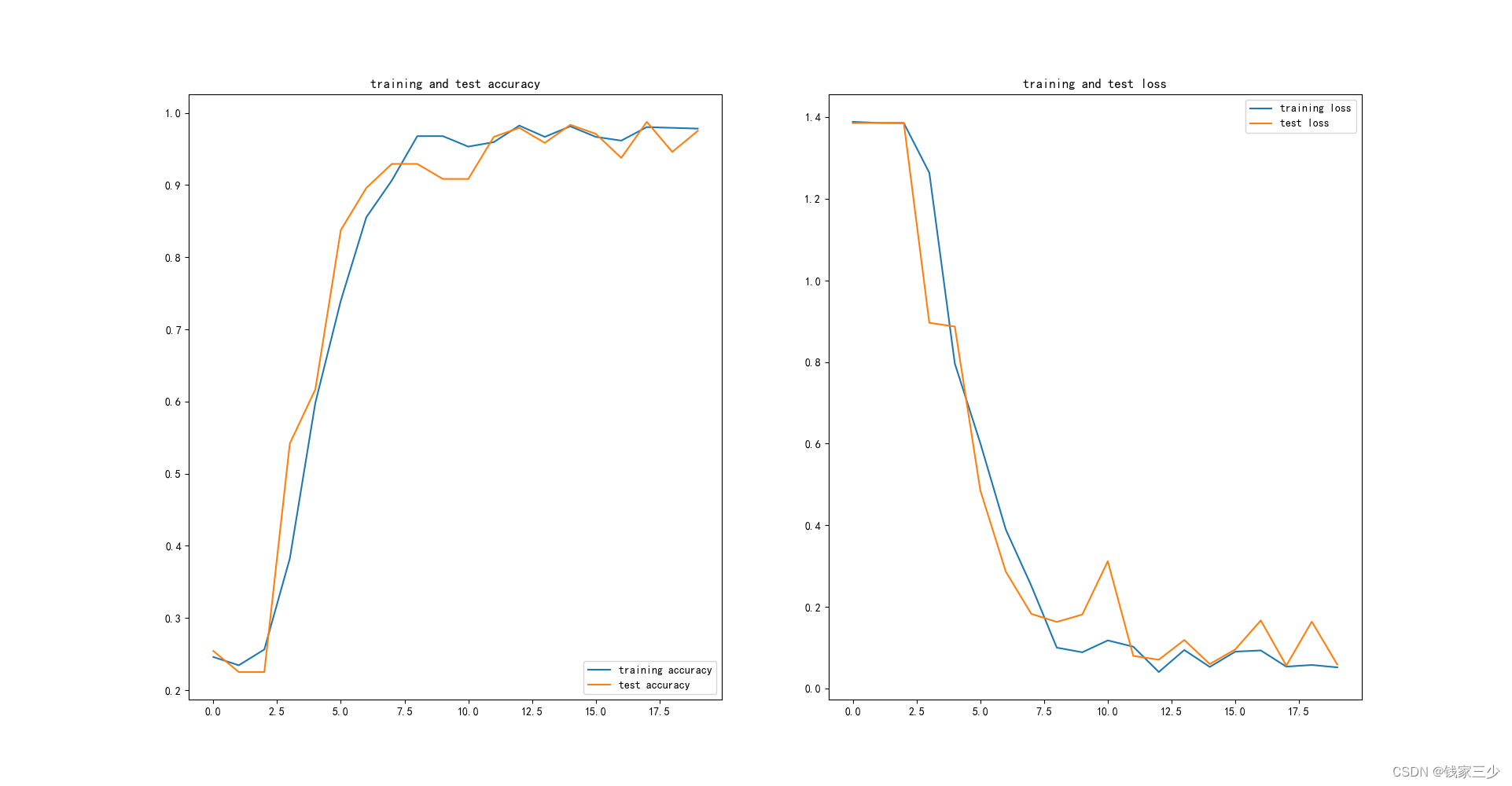
后话,我对于这个结果挺满意的,之前我真的以为vgg16为啥效果这么差,现在一看,我还是不够了解,没有过拟合,损失也降到最低















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









