






import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision
import torchsummary as summary
from torchvision import datasets
import os,PIL,pathlib,warnings,copy
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')
device=torch.device("cuda" if torch.cuda.is_available() else"cpu")
print(device)
data_dir=pathlib.Path(r'D:\BaiduNetdiskDownload\第5天\data')
print(data_dir)
#直接将地址生成路径
train_transforms=transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485,0.56,0.06],
std=[0.229,0.224,0.225]
)
#设定数据变化的过程,先调整大小,然后变成tensor,接着进行三通道标准化
])
total_data=datasets.ImageFolder(data_dir,transform=train_transforms)
print(total_data)
#根据路径生成ImageFolder对象,中间是将数据根据上面的流程进行转化,然后形成一个初级加工的数据total_data
leibie=total_data.class_to_idx
print(leibie)
#total_data这个对象,有一个自带属性也就是class_to_idx,也就是根据文件夹的名字,对应一个类别索引,也就是文件名:索引,一共四个,也就是多分类任务
train_size=int(0.8*len(total_data))
test_size=int(0.2*len(total_data))
train_dataset,test_dataset=torch.utils.data.random_split(total_data,[train_size,test_size])
print(train_size,test_size)
print(train_dataset,test_dataset)
#total_data毕竟是一个总的数据,我们肯定要将其切分成训练集和测试集,这里是自主选定切分比例,用整数表示,然后借助图像数据切分模块torch.utils.data的random_split,进行切分,以后会用到很多次torch.utils.data,切分的时候,第一个参数是数据,第二个是大小,用中括号括起来
batch_size=8
train_dl=torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
test_dl=torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True)
#记住这里又一次用到了torch.utils.data,只不过这里做的是将训练集/测试集切分成小批次,刚才那个random_split可以理解为切分成一刀两断,这里是把这两段切成数刀,变成统一大小的一批批数据
for x,y in test_dl:
print('shape of x[N,C,H,W]:',x.shape)
print('shape of y:',y.shape,y.dtype)
break
#一批8张图,每张图三通道,宽224,高224
import torch.nn.functional as F
def autopad(k,p=None):
if p is None:
p=k//2 if isinstance(k,int) else [x//2 for x in k]
return p
#这里的p为k的一半,如果k不为整数,则向下取整数的一半,反正一定是整数
class Conv(nn.Module):
def __init__(self,c1,c2,k=1,s=1,p=None,g=1,act=True):
super().__init__()
self.conv=nn.Conv2d(c1,c2,k,s,autopad(k,p),groups=g,bias=False)
self.bn=nn.BatchNorm2d(c2)
self.act=nn.SiLU() if act is True else (act if isinstance(act,nn.Module) else nn.Identity())
#只能粗略说一下,SiLU可以看成是ReLU的升级版,当x为负数的时候,左半边不再是0,而是凹进去的,增加了可导性,效果理论上要比ReLU好,认知只能做到这一步
def forward(self,x):
return self.act(self.bn(self.conv(x)))
#其实forward这个函数,很大程度是将之前初始化的属性全都穿起来,表现为先怎么做,再怎么做,最后怎么做
class Bottleneck(nn.Module):
def __init__(self,c1,c2,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c_,c2,3,1,g=g)
self.add=shortcut and c1==c2
#这里提一下shortcut,这个有点意思,就是走捷径,也就是假设从第一层跨到第十层,然后接着训练,因为有时候,大家发现,梯度不是增加的层数越多越好,效果可能会变差,如果我们将上述跨层效果和一层层训练效果叠加,可能效果会不错
def forward(self,x):
return x*self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
def __init__(self,c1,c2,n=1,shortcut=True,g=1,e=0.5):
super().__init__()
c_=int(c2*e)
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c1,c_,1,1)
self.cv3=Conv(2*c_,c2,1)
self.m=nn.Sequential(*(Bottleneck(c_,c_,shortcut,g,e=1.0) for _ in range(n)))
def forward(self,x):
return self.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),dim=1))
class SPPF(nn.Module):
def __init__(self,c1,c2,k=5):
super().__init__()
c_=c1//2
self.cv1=Conv(c1,c_,1,1)
self.cv2=Conv(c_*4,c2,1,1)
self.m=nn.MaxPool2d(kernel_size=k,stride=1,padding=k//2)
def forward(self,x):
x=self.cv1(x)
with warnings.catch_warnings():
y1=self.m(x)
y2=self.m(y1)
return self.cv2(torch.cat([x,y1,y2,self.m(y2)],1))
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone,self).__init__()
self.Conv_1=Conv(3,64,3,2,2)
self.Conv_2=Conv(64,128,3,2)
self.C3_3=C3(128,128)
self.Conv_4=Conv(128,256,3,2)
self.C3_5=C3(256,256)
self.Conv_6=Conv(256,512,3,2)
self.C3_7=C3(512,512)
self.Conv_8=Conv(512,1024,3,2)
self.C3_9=C3(1024,1024)
self.SPPF=SPPF(1024,1024,5)
self.classifier=nn.Sequential(
nn.Linear(in_features=65536,out_features=100),
nn.ReLU(),
nn.Linear(in_features=100,out_features=4)
)
def forward(self,x):
x=self.Conv_1(x)
x=self.Conv_2(x)
x=self.C3_3(x)
x=self.Conv_4(x)
x=self.C3_5(x)
x=self.Conv_6(x)
x=self.C3_7(x)
x=self.Conv_8(x)
x=self.C3_9(x)
x=self.SPPF(x)
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
model=YOLOv5_backbone().to(device)
print(model)
import torchsummary as summary
summary.summary(model,(3,224,224))
#这个函数挺不错的,不用print,第一个参数是模型,第二个参数是每一张图片的初始转换后的大小,我们在这里,会看到每一层的参数变化,以及输出形状,这里的第一个-1代表批次数量,后面三个代表一张图片转化后的大小
def train(dataloader,model,loss_fn,optimizer):
size=train_size
num_batches=int(size/batch_size+0.99)
#这里我又改了一下,这样的话,更好理解,也就是size就是训练集的大小,num_batches就是迭代次数,但是size/batch_size可能有小数,我想追求向上取整,所以改为int(size/batch_size+0.99)即可
train_loss,train_acc=0,0
for x,y in dataloader:
x,y=x.to(device),y.to(device)
y_pred=model(x)
loss=loss_fn(y_pred,y)
optimizer.zero_grad()#优化器先初始化
loss.backward()#损失函数反向求导
optimizer.step()#参数更新一次
train_acc+=(y_pred.argmax(1)==y).type(torch.float).sum().item()
train_loss+=loss.item()
train_acc/=size
train_loss/=num_batches
return train_acc,train_loss
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batches=len(dataloader)
test_loss,test_acc=0,0
with torch.no_grad():#设定梯度不求导的前提
for x, y in dataloader:
x, y = x.to(device), y.to(device)
y_pred=model(x)
loss=loss_fn(y_pred,y)
test_acc+=(y_pred.argmax(1)==y).type(torch.float).sum().item()
test_loss+=loss.item()
test_acc/=size
test_loss/=num_batches
return test_acc,test_loss
import copy
lr=1e-4
optimizer=torch.optim.Adam(model.parameters(),lr)
print(optimizer)
loss_fn=nn.CrossEntropyLoss()#多分类继续使用交叉熵损失函数
epochs=20
#一般我会将epochs设置为1,进行模型报错更正,如果模型不再报错,就将值设为20,后面如果你将数值设置更大,其实提升的效果有限,不会有多大的提升
train_loss=[]
train_acc=[]
test_acc=[]
test_loss=[]
best_acc=0
epoch_range=range(epochs)#变量名epoch_range也可以储存为range(epochs)
print(epoch_range)
for epoch in epoch_range:
model.train()#先进行第一轮训练
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,optimizer)#然后导出训练结果
model.eval()#根据第一轮训练模型,以及参数,进行验证
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)#然后导出测试结果
if epoch_test_acc>best_acc:
best_acc=epoch_test_acc#开始比大小,确认最优的验证精确率,因为不一定是最后一次迭代,效果是最好的
best_model=copy.deepcopy(model)#将效果最好的模型,进行拷贝,然后复制给best_model
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr=optimizer.state_dict()['param_groups'][0]['lr']#这个代码的意思就是给定一个optimizer,我就根据这一串代码,获得该优化器的学习率,但是我认为如果学习率不变的话,不用最后打印出来,因为上面代码有设定
template = ('epoch:{},train_acc:{:.1f}%,test_acc:{:.1f}%,train_loss:{:.3f},test_loss:{:.3f},lr:{:.2e}')
result = template.format(epoch + 1, epoch_train_acc * 100, epoch_test_acc * 100, epoch_train_loss, epoch_test_loss,lr)
print(result)
print(best_acc)
#torch.save(best_model.state_dict(),'./best_model.pth')#这里我细看了一下,第一个参数是最优模型参数,第二个参数是保存地址,以后有需要的话,可以将这个模型启用,将保存的参数加载进来
print('好了')
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['figure.dpi']=100
plt.figure(figsize=[20,10])
plt.subplot(1,2,1)
plt.plot(epoch_range,train_acc,label='train_acc')
plt.plot(epoch_range,test_acc,label='test_acc')
plt.legend(loc='lower right')
plt.title('train_acc and test_acc')
plt.subplot(1,2,2)
plt.plot(epoch_range,train_loss,label='train_loss')
plt.plot(epoch_range,test_loss,label='test_loss')
plt.legend(loc='upper right')
plt.title('train_loss and test_loss')
plt.show()
D:\anaconda\envs\torch\python.exe "D:/pycharm/PyCharm Community Edition 2022.1.1/pythonProject19/main.py"
cuda
D:\BaiduNetdiskDownload\第5天\data
Dataset ImageFolder
Number of datapoints: 1125
Root location: D:\BaiduNetdiskDownload\第5天\data
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=warn)
ToTensor()
Normalize(mean=[0.485, 0.56, 0.06], std=[0.229, 0.224, 0.225])
)
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}
900 225
<torch.utils.data.dataset.Subset object at 0x0000011FAC6F9970> <torch.utils.data.dataset.Subset object at 0x0000011FAC6F9A00>
shape of x[N,C,H,W]: torch.Size([8, 3, 224, 224])
shape of y: torch.Size([8]) torch.int64
YOLOv5_backbone(
(Conv_1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(Conv_2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_4): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_5): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_6): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_7): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_8): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_9): C3(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(SPPF): SPPF(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 113, 113] 1,728
BatchNorm2d-2 [-1, 64, 113, 113] 128
SiLU-3 [-1, 64, 113, 113] 0
Conv-4 [-1, 64, 113, 113] 0
Conv2d-5 [-1, 128, 57, 57] 73,728
BatchNorm2d-6 [-1, 128, 57, 57] 256
SiLU-7 [-1, 128, 57, 57] 0
Conv-8 [-1, 128, 57, 57] 0
Conv2d-9 [-1, 64, 57, 57] 8,192
BatchNorm2d-10 [-1, 64, 57, 57] 128
SiLU-11 [-1, 64, 57, 57] 0
Conv-12 [-1, 64, 57, 57] 0
Conv2d-13 [-1, 64, 57, 57] 4,096
BatchNorm2d-14 [-1, 64, 57, 57] 128
SiLU-15 [-1, 64, 57, 57] 0
Conv-16 [-1, 64, 57, 57] 0
Conv2d-17 [-1, 64, 57, 57] 36,864
BatchNorm2d-18 [-1, 64, 57, 57] 128
SiLU-19 [-1, 64, 57, 57] 0
Conv-20 [-1, 64, 57, 57] 0
Bottleneck-21 [-1, 64, 57, 57] 0
Conv2d-22 [-1, 64, 57, 57] 8,192
BatchNorm2d-23 [-1, 64, 57, 57] 128
SiLU-24 [-1, 64, 57, 57] 0
Conv-25 [-1, 64, 57, 57] 0
Conv2d-26 [-1, 128, 57, 57] 16,384
BatchNorm2d-27 [-1, 128, 57, 57] 256
SiLU-28 [-1, 128, 57, 57] 0
Conv-29 [-1, 128, 57, 57] 0
C3-30 [-1, 128, 57, 57] 0
Conv2d-31 [-1, 256, 29, 29] 294,912
BatchNorm2d-32 [-1, 256, 29, 29] 512
SiLU-33 [-1, 256, 29, 29] 0
Conv-34 [-1, 256, 29, 29] 0
Conv2d-35 [-1, 128, 29, 29] 32,768
BatchNorm2d-36 [-1, 128, 29, 29] 256
SiLU-37 [-1, 128, 29, 29] 0
Conv-38 [-1, 128, 29, 29] 0
Conv2d-39 [-1, 128, 29, 29] 16,384
BatchNorm2d-40 [-1, 128, 29, 29] 256
SiLU-41 [-1, 128, 29, 29] 0
Conv-42 [-1, 128, 29, 29] 0
Conv2d-43 [-1, 128, 29, 29] 147,456
BatchNorm2d-44 [-1, 128, 29, 29] 256
SiLU-45 [-1, 128, 29, 29] 0
Conv-46 [-1, 128, 29, 29] 0
Bottleneck-47 [-1, 128, 29, 29] 0
Conv2d-48 [-1, 128, 29, 29] 32,768
BatchNorm2d-49 [-1, 128, 29, 29] 256
SiLU-50 [-1, 128, 29, 29] 0
Conv-51 [-1, 128, 29, 29] 0
Conv2d-52 [-1, 256, 29, 29] 65,536
BatchNorm2d-53 [-1, 256, 29, 29] 512
SiLU-54 [-1, 256, 29, 29] 0
Conv-55 [-1, 256, 29, 29] 0
C3-56 [-1, 256, 29, 29] 0
Conv2d-57 [-1, 512, 15, 15] 1,179,648
BatchNorm2d-58 [-1, 512, 15, 15] 1,024
SiLU-59 [-1, 512, 15, 15] 0
Conv-60 [-1, 512, 15, 15] 0
Conv2d-61 [-1, 256, 15, 15] 131,072
BatchNorm2d-62 [-1, 256, 15, 15] 512
SiLU-63 [-1, 256, 15, 15] 0
Conv-64 [-1, 256, 15, 15] 0
Conv2d-65 [-1, 256, 15, 15] 65,536
BatchNorm2d-66 [-1, 256, 15, 15] 512
SiLU-67 [-1, 256, 15, 15] 0
Conv-68 [-1, 256, 15, 15] 0
Conv2d-69 [-1, 256, 15, 15] 589,824
BatchNorm2d-70 [-1, 256, 15, 15] 512
SiLU-71 [-1, 256, 15, 15] 0
Conv-72 [-1, 256, 15, 15] 0
Bottleneck-73 [-1, 256, 15, 15] 0
Conv2d-74 [-1, 256, 15, 15] 131,072
BatchNorm2d-75 [-1, 256, 15, 15] 512
SiLU-76 [-1, 256, 15, 15] 0
Conv-77 [-1, 256, 15, 15] 0
Conv2d-78 [-1, 512, 15, 15] 262,144
BatchNorm2d-79 [-1, 512, 15, 15] 1,024
SiLU-80 [-1, 512, 15, 15] 0
Conv-81 [-1, 512, 15, 15] 0
C3-82 [-1, 512, 15, 15] 0
Conv2d-83 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-84 [-1, 1024, 8, 8] 2,048
SiLU-85 [-1, 1024, 8, 8] 0
Conv-86 [-1, 1024, 8, 8] 0
Conv2d-87 [-1, 512, 8, 8] 524,288
BatchNorm2d-88 [-1, 512, 8, 8] 1,024
SiLU-89 [-1, 512, 8, 8] 0
Conv-90 [-1, 512, 8, 8] 0
Conv2d-91 [-1, 512, 8, 8] 262,144
BatchNorm2d-92 [-1, 512, 8, 8] 1,024
SiLU-93 [-1, 512, 8, 8] 0
Conv-94 [-1, 512, 8, 8] 0
Conv2d-95 [-1, 512, 8, 8] 2,359,296
BatchNorm2d-96 [-1, 512, 8, 8] 1,024
SiLU-97 [-1, 512, 8, 8] 0
Conv-98 [-1, 512, 8, 8] 0
Bottleneck-99 [-1, 512, 8, 8] 0
Conv2d-100 [-1, 512, 8, 8] 524,288
BatchNorm2d-101 [-1, 512, 8, 8] 1,024
SiLU-102 [-1, 512, 8, 8] 0
Conv-103 [-1, 512, 8, 8] 0
Conv2d-104 [-1, 1024, 8, 8] 1,048,576
BatchNorm2d-105 [-1, 1024, 8, 8] 2,048
SiLU-106 [-1, 1024, 8, 8] 0
Conv-107 [-1, 1024, 8, 8] 0
C3-108 [-1, 1024, 8, 8] 0
Conv2d-109 [-1, 512, 8, 8] 524,288
BatchNorm2d-110 [-1, 512, 8, 8] 1,024
SiLU-111 [-1, 512, 8, 8] 0
Conv-112 [-1, 512, 8, 8] 0
MaxPool2d-113 [-1, 512, 8, 8] 0
MaxPool2d-114 [-1, 512, 8, 8] 0
MaxPool2d-115 [-1, 512, 8, 8] 0
Conv2d-116 [-1, 1024, 8, 8] 2,097,152
BatchNorm2d-117 [-1, 1024, 8, 8] 2,048
SiLU-118 [-1, 1024, 8, 8] 0
Conv-119 [-1, 1024, 8, 8] 0
SPPF-120 [-1, 1024, 8, 8] 0
Linear-121 [-1, 100] 6,553,700
ReLU-122 [-1, 100] 0
Linear-123 [-1, 4] 404
================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 137.59
Params size (MB): 82.89
Estimated Total Size (MB): 221.06
----------------------------------------------------------------
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
capturable: False
differentiable: False
eps: 1e-08
foreach: None
fused: None
lr: 0.0001
maximize: False
weight_decay: 0
)
range(0, 20)
epoch:1,train_acc:37.9%,test_acc:44.9%,train_loss:1.419,test_loss:3.758,lr:1.00e-04
epoch:2,train_acc:45.7%,test_acc:45.8%,train_loss:1.132,test_loss:1.013,lr:1.00e-04
epoch:3,train_acc:52.1%,test_acc:50.2%,train_loss:1.007,test_loss:0.880,lr:1.00e-04
epoch:4,train_acc:54.0%,test_acc:49.3%,train_loss:0.966,test_loss:0.823,lr:1.00e-04
epoch:5,train_acc:58.6%,test_acc:60.4%,train_loss:0.878,test_loss:0.758,lr:1.00e-04
epoch:6,train_acc:58.6%,test_acc:63.1%,train_loss:0.873,test_loss:0.818,lr:1.00e-04
epoch:7,train_acc:69.3%,test_acc:77.3%,train_loss:0.705,test_loss:0.730,lr:1.00e-04
epoch:8,train_acc:77.4%,test_acc:84.0%,train_loss:0.587,test_loss:0.395,lr:1.00e-04
epoch:9,train_acc:77.1%,test_acc:85.3%,train_loss:0.588,test_loss:0.727,lr:1.00e-04
epoch:10,train_acc:84.4%,test_acc:88.0%,train_loss:0.393,test_loss:0.360,lr:1.00e-04
epoch:11,train_acc:82.4%,test_acc:84.4%,train_loss:0.457,test_loss:0.358,lr:1.00e-04
epoch:12,train_acc:83.9%,test_acc:90.2%,train_loss:0.405,test_loss:0.256,lr:1.00e-04
epoch:13,train_acc:84.7%,test_acc:86.7%,train_loss:0.389,test_loss:0.341,lr:1.00e-04
epoch:14,train_acc:86.8%,test_acc:87.6%,train_loss:0.355,test_loss:0.376,lr:1.00e-04
epoch:15,train_acc:87.6%,test_acc:90.7%,train_loss:0.347,test_loss:7.222,lr:1.00e-04
epoch:16,train_acc:90.3%,test_acc:88.4%,train_loss:0.271,test_loss:0.289,lr:1.00e-04
epoch:17,train_acc:88.3%,test_acc:90.2%,train_loss:0.296,test_loss:0.317,lr:1.00e-04
epoch:18,train_acc:90.8%,test_acc:88.0%,train_loss:0.241,test_loss:0.395,lr:1.00e-04
epoch:19,train_acc:90.1%,test_acc:93.3%,train_loss:0.246,test_loss:0.193,lr:1.00e-04
epoch:20,train_acc:92.6%,test_acc:92.4%,train_loss:0.217,test_loss:0.235,lr:1.00e-04
0.9333333333333333
好了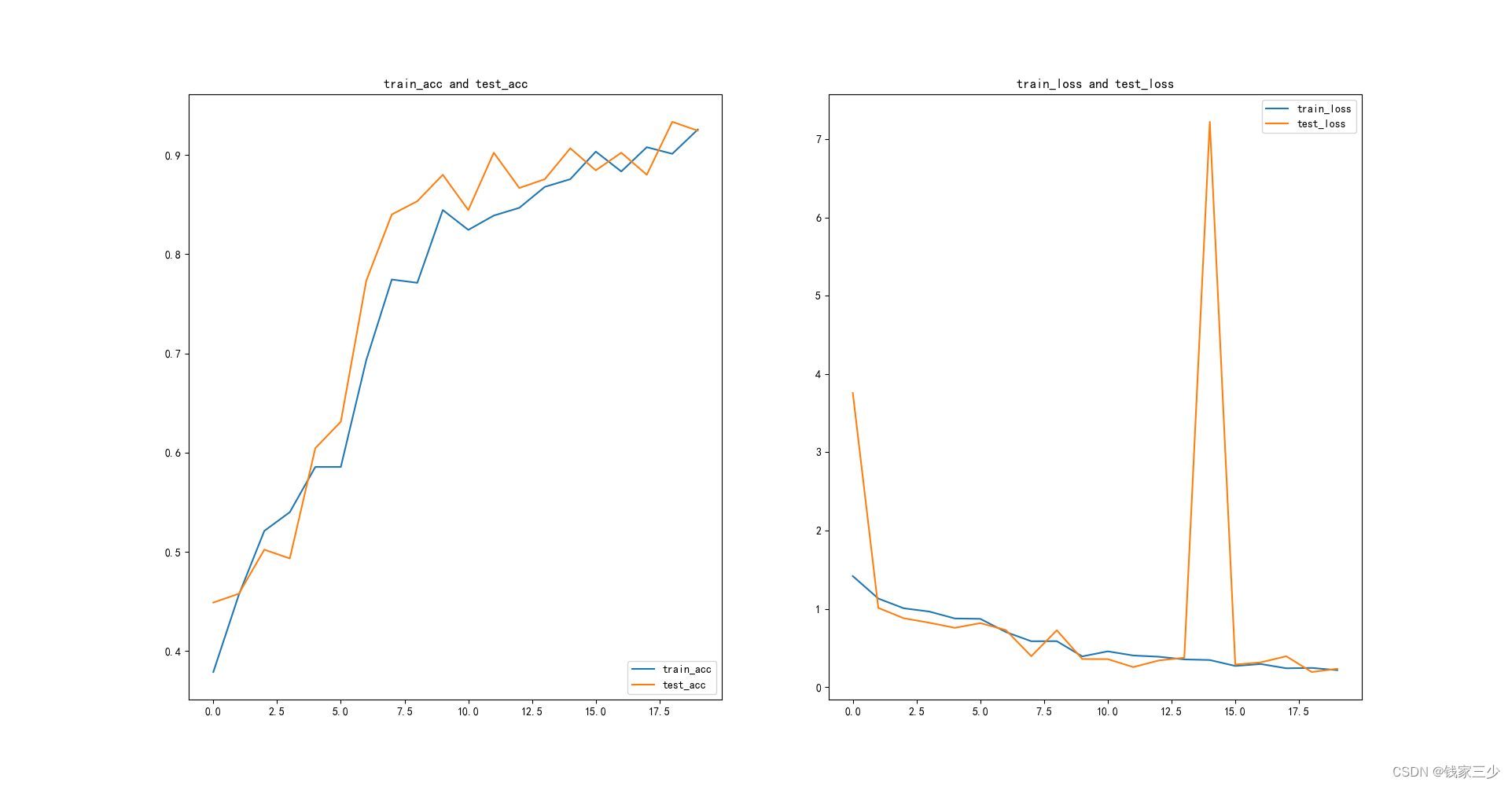
最后我来评价一下这张图,首先泛化性能不错,不存在过拟合,然后可能是因为学习率固定的关系,所以导致损失这一块,有一个大幅度的起伏,总体趋势还是收敛的,模型效果不错,只不过我用的batch_size有点小,而数值大一点,效果就会差很多,目前这一块,没有想通,反正我对这个代码进行了一定的修改和创新,但是最关键的yolo,我还是没有彻底学好,感觉不是朝夕就能搞定,还需要花费更多时间,进一步去理解,主要是层数太多,又经过各种变换,我短时间搞不定。















 2203
2203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









