









在机器学习实战中——是否需要归一化(Normalization)或标准化(Standardization),取决于所使用的模型类型。
✅ LightGBM / XGBoost 是否需要归一化或标准化?
不需要。
🔧 原因:
LightGBM 和 XGBoost 都是 基于决策树的模型,它们对特征的数值分布不敏感:
- 决策树只关心特征的相对大小和分裂点,而不是绝对数值或分布形态。
- 不存在权重乘以特征的问题,所以不需要归一化或标准化。
❓归一化和标准化是什么,有什么区别?
| 方法 | 名称 | 作用 | 公式 | 使用场景 |
|---|---|---|---|---|
| ✅ 归一化 | Min-Max Normalization | 把数据压缩到 [0,1] 范围 | x' = (x - min) / (max - min) | 深度学习(如Keras) 或欧几里得距离计算 |
| ✅ 标准化 | Z-score Standardization | 转换为均值为0、方差为1的数据 | x' = (x - mean) / std | 线性回归、SVM、KNN、神经网络 |
🔍 举个例子:
假设温度范围是 [60°C, 120°C],振动范围是 [0.1, 10.0] mm/s
如果你用神经网络,振动的数值对损失函数的影响将远大于温度 —— 所以需要归一化/标准化。
而 LightGBM/XGBoost 会自动找到“哪个值做分裂点最好”,不会因为振动数值更大就更“重视”它。
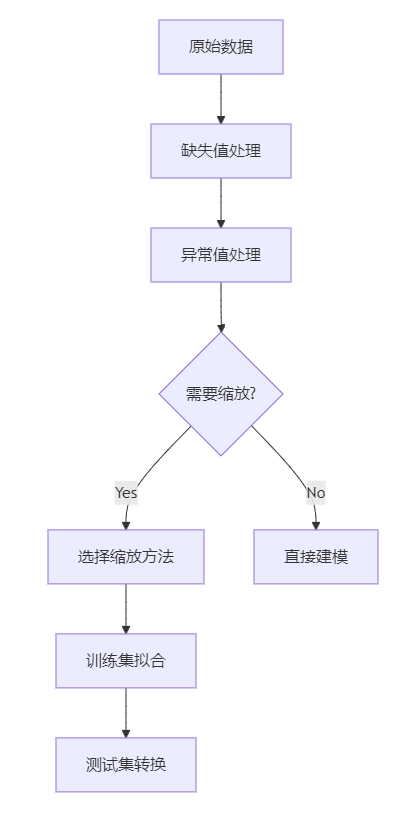
✅ 总结
| 问题 | 回答 |
|---|---|
| 是否需要对 LightGBM / XGBoost 做归一化或标准化? | ❌ 不需要 |
| 是否建议你预处理? | ✅ 建议做缺失值处理,但不需要缩放 |
| 哪些模型必须做归一化或标准化? | 神经网络、KNN、SVM、线性模型等 |
如果未来使用 类似于Keras 的神经网络模型(比如你前面提到的 CNN、LSTM),那就必须做归一化或标准化。
在实际应用中,归一化(Normalization)和标准化(Standardization)通常只选一个,其实我们不需要两个都做,选择哪一个取决于所用模型和数据分布。
✅ 选择哪一个的判断依据:
| 场景 | 推荐操作 | 原因 |
|---|---|---|
| 神经网络(Keras, TensorFlow, PyTorch) | 🔹归一化 或 🔹标准化都可,但选其一即可 | 网络更稳定、收敛更快 |
| 数据近似服从正态分布 | ✅ 标准化 | 把数据压成均值为0、标准差为1 |
| 数据在固定范围内分布(如0-255图像) | ✅ 归一化 | 保持原分布特性,缩放到[0,1]或[-1,1] |
| KNN、SVM、线性模型 | ✅ 标准化更常见 | 对欧几里得距离和梯度敏感 |
| 决策树类模型(XGBoost、LightGBM) | ❌ 都不需要 | 树模型对数据缩放不敏感 |
🔍 区别总结
| 操作 | 名称 | 结果 | 应用常见于 |
|---|---|---|---|
x' = (x - min) / (max - min) | 归一化 | 数据压缩到 [0, 1] | 图像像素、深度学习输入 |
x' = (x - μ) / σ | 标准化 | 数据均值为0,标准差为1 | KNN/SVM/回归/神经网络 |
🧪 举例代码:
✅ 1. 标准化(Z-score):
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 用于训练集 & 测试集
✅ 2. 归一化(Min-Max):
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
⚠️ 注意:训练集用
fit_transform,测试集用transform,不能重新fit!
✅ 最终结论:
| 问题 | 回答 |
|---|---|
| 是否需要同时做归一化和标准化? | ❌ 不需要,只选其一 |
| 选哪个? | 神经网络用归一化或标准化都可以,推荐标准化更通用 |
| 树模型要不要做? | ❌ 都不做,直接用原始数据即可 |

















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









