







 本文详细介绍了随机存取存储器(RAM)的原理、与只读存储器(ROM)的区别,以及RAM在FPGA中的IP核配置,特别是涉及到了双口RAM的乒乓操作,展示了如何通过状态机实现无缝数据处理。此外,文章还讨论了乒乓操作的优势,如数据流处理和空间效率提升。
本文详细介绍了随机存取存储器(RAM)的原理、与只读存储器(ROM)的区别,以及RAM在FPGA中的IP核配置,特别是涉及到了双口RAM的乒乓操作,展示了如何通过状态机实现无缝数据处理。此外,文章还讨论了乒乓操作的优势,如数据流处理和空间效率提升。
一、RAM资源介绍
RAM的英文全称是Random Access Memory,即随机存取存储器,它可以随时把数据写入任一指定地址的存储单元,也可以随时从任一指定地址中读出数据,其读写速度是由时钟频率决定的。RAM主要用来存放程序及程序执行过程中产生的中间数据、运算结果等。
单端口:只有一个端口,读写数据不能同时进行,共用数据通道。
伪双端口:拥有两个数据通道,一个用来写一个用来读。
真双端口:拥有两个数据通道,一个用来写一个用来读。
RAM区别于ROM:
RAM(Random Access Memory)和ROM(Read-Only Memory)是计算机中常见的两种存储器件,它们有以下主要区别:
1. 可读写性:
- RAM是一种可读写的内存,用于临时存储数据和程序。数据可以随时被写入、修改和读取,但在断电或重启计算机后数据会消失。
- ROM是一种只读的内存,其中存储了固定的数据或程序,用户无法对其进行修改。即使在断电或重启计算机后,其中的数据也会保持不变。
2. 数据保存:
- RAM用于存储正在运行的程序和临时数据,可以被CPU频繁读写,速度较快,但数据不稳定。
- ROM用于存储固化的系统程序和数据,通常包括启动程序和固件等,数据稳定不易丢失。
3. 容量和成本:
- RAM容量相对较大,通常用于临时存储大量数据和程序,但成本较高。
- ROM容量通常较小,主要用于存储固定的程序和数据,成本相对较低。
综上所述,RAM和ROM在功能、读写性质、数据保存方式以及成本等方面有明显的区别,它们在计算机系统中发挥着不同的作用。
二、RAM IP核使用
1、具体配置
(1)Basic
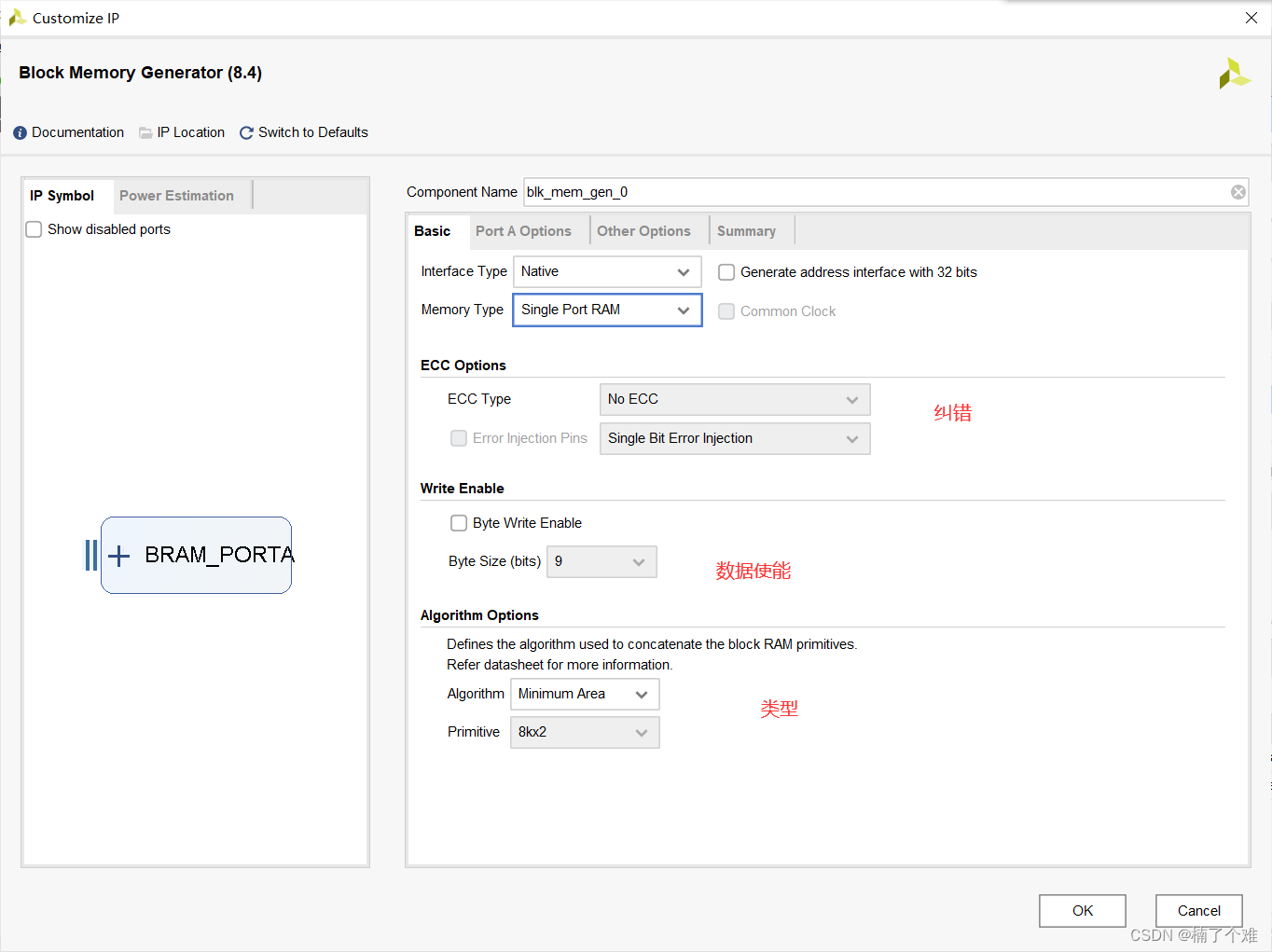
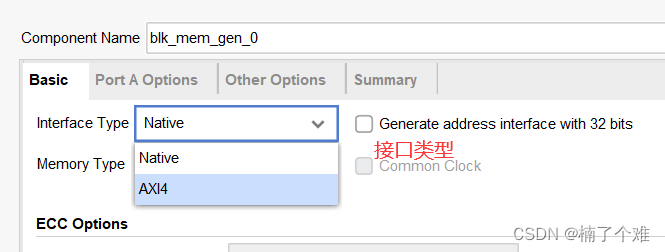
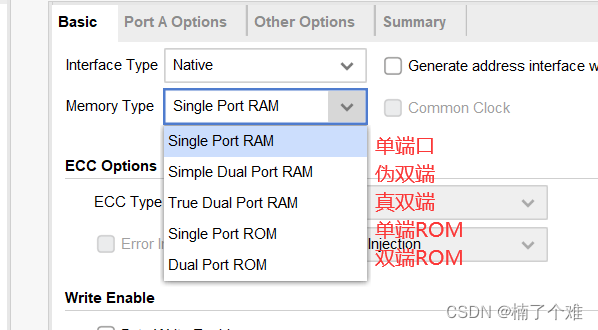
FPGA中没有ROM资源,ROM资源利用RAM资源模拟生成
(2)Port A Options
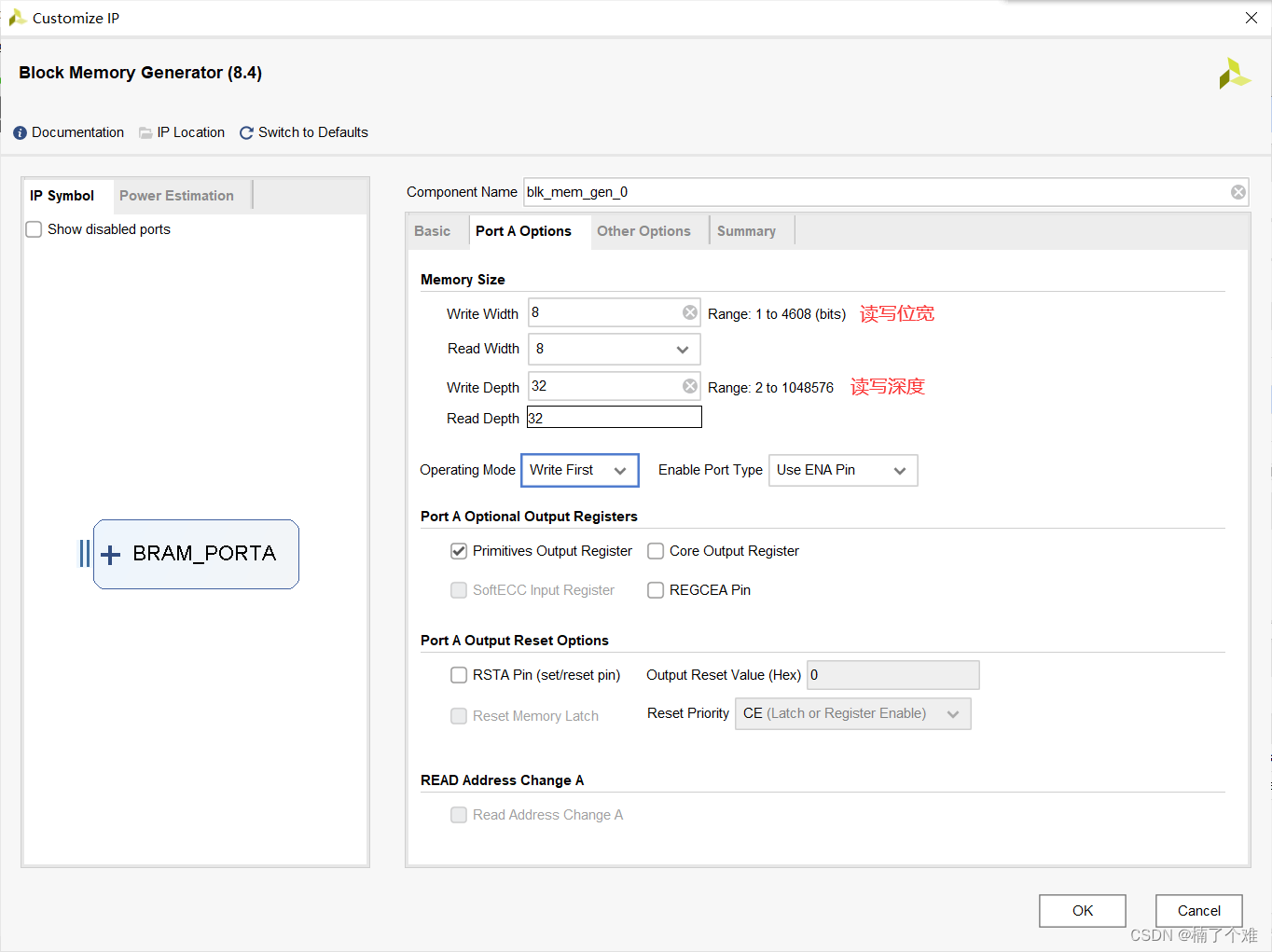
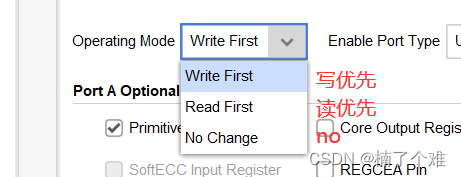
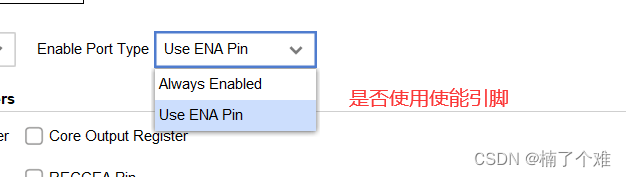

使用输出寄存器,数据会延后一个时钟

其他保持默认
2、代码驱动
使用三个计数器分别控制读写切换、写入数据、读写地址
`timescale 1ns / 1ps
//
// Company:
// Engineer:
//
// Create Date: 2024/02/20 09:25:45
// Design Name:
// Module Name: rw_ram
// Project Name:
// Target Devices:
// Tool Versions:
// Description:
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
//
module rw_ram(
input clk,
input rst_n,
output ram_en ,
output ram_wea ,
output reg[4:0]ram_addr ,
output reg[7:0]ram_wr_data ,
output reg[7:0]ram_rd_data
);
reg[5:0]rw_cnt;
//读写切换 1写 0读
assign ram_wea=((rw_cnt <= 6'd31)&&(ram_en == 1'b1)) ? 1'b1 : 1'b0;
assign ram_en=rst_n;
//读写状态计数器
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
rw_cnt <= 6'b0;
end
else if(rw_cnt < 6'd63)begin
rw_cnt <= rw_cnt + 1'b1;
end
else begin
rw_cnt <= 6'b0;
end
end
//读写数据计数器
always @(posedge  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8117
8117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









