






摘要:当前大数据、人工智能、云计算等科技发展迅猛,互联网进一步崛起,尤其以支付宝、微信等移动支付工具为代表,科技与金融的结合以低成本、高效率的优势迅速渗透到整个银行业。传统银行在科技进步和产业升级的背景下面临越来越严峻的挑战,客户对于金融产品和服务的选择越来越多样化,商业银行原有的活期存款、理财产品、基金产品等业务不断流入互联网,传统商业银行利润被挤压,原有的优质客户大批流失。客户是商业银行生存的保障。商业银行为了应对客户流失的现状,必然要与金融科技深度融合,通过金融科技对传统业务场景进行重塑,推动客户流失问题的缓解。基于以上情况,本文建立了Logistic回归模型并且进行了参数调优。在比较了准确率、精确率、召回率和AUC值等评价指标后,最终发现逻辑回归模型能较好的对银行客户流失进行预测。同时,本文还进一步对特征变量进行重要性排序,分析了客户流失的原因,相应的提出了一些挽留客户的策略建议,帮助银行有效地集中资源,在客户真正流失前做出更明智的挽留决策,提高绩效,保持持久的竞争力。
关键词:逻辑回归、银行客户流失、客户管理
1.研究背景
在当今金融服务业高度竞争的环境中,银行面临着日益严峻的客户流失问题。客户流失,即客户终止与银行的商业关系,直接影响银行的利润和持续发展能力。由于吸引新客户的成本远高于保留现有客户,银行迫切需要通过有效的预测模型来识别可能流失的客户,并采取措施防止流失的发生。本研究旨在构建一个银行客户流失预测模型,以探索影响客户流失的关键因素,并为银行提供决策支持,以降低客户流失率,增强客户忠诚度。
以往的研究很少有针对银行客户流失问题的,但是可以类比参考其他行业的客户流失问题的研究文献,对本问题的研究也大有裨益。
1.1国内研究现状:
朱凡等(2021)[1]研究航空公司的客户流失状况,提出以K-means和神经网络为基础的客户流失预测模型,在对数据做好预处理后,建立模型进行预测,最后结果说明,人工神经网络对客户流失的预测准确性高于K-means算法。
董纪阳(2020)[2]以某基金的客户信息为数据,首先利用决策树对客户特征进行筛选,在通过Logistic回归建立客户流失预测模型,得到相应的混淆矩阵、准确率、召回率、F1值,从而对模型效果进行评价,实证结果表明,模型能够取得很好的效果,准确率和召回率分别达到99%和98%。
郑红等(2020)[3]借鉴随机森林的Bagging自助采样思想,提出了一种基于自助采样法的Stacking集成方法,也就是说,首先对数据集多次采样,之后将前面得到的数据子集训练基分类器副本,最后用基分类器副本以投票的方式确定出基分类器的决策结果,结果表明,改良后的集成学习方法在准确率、查准率和F1值这3项指标上均优于同结构的Stacking集成方法。
邓致(2019)[4]从一家银行信用卡客户2017至2018年的历史数据中,随机抽取了2000个样本,使用SASEM工具,建立了三种不同的预测模型,包括逻辑回归、神经网络和决策树。实证结果表明,这三种算法均具有较为优良的预测能力,预测准确率都达到了八成,都良好地发挥了挖掘潜在流失客户的功能,其中神经网络和逻辑回归的性能更好,这可以为保留信用卡客户提供技术支持。
王华等人(2010)[5]的研究指出,服务质量和客户感知价值是影响客户流失的主要因素。此外,政策和法规如《中华人民共和国银行业监督管理法》(2015)[6],对银行客户管理策略也产生了影响。
1.2国外研究现状:
Praveen Lalwani等(2021)[7]使用朴素贝叶斯、支持向量机、决策树、逻辑回归、随机森林等方法建立用户流失模型,并通过K折交叉验证排查过拟合问题,选择混淆矩阵、AUC曲线作为分类模型指标,结果发现XGBoost模型和AdaBoost模型这两个模型的分类性能高于其他模型,这两个模型的准确率均超过80%,AUC得分均可达到84%。
Swetha P等(2020)[8]提出了带有特征函数的Improvised-XGBoost模型来预测电信行业的客户流失,该模型结合XGBoost模型构建特征函数,然后通过迭代的方法构造损失函数并使其最小化,研究表明Improvised-XGBoost模型在准确率、查准率和召回率等多种性能指标上的表现都优于其他模型,该模型效率更高,可用于复杂数据集。
Qiu Yanfang(2017)[9]以电子商务的用户流失为研究对象,通过因子分析法对用户在线时间、登录次数、注意事项等用户行为因素进行分析,再结合逻辑回归模型,提出了EBURM模型,最后结果证明,其提出的EBURM模型能够在高置信度下预测用户流失行为。
Smith等人(1982)[10]的研究表明,客户满意度是影响客户忠诚度的关键因素。随着数据技术的进步,Hosmer等人(2000)[11]通过逻辑回归模型在银行客户流失的预测上取得了显著的成果。
Johnson与Zhao(2018)[12]指出金融科技的发展改变了客户的银行业务使用习惯,对客户忠诚度造成了影响。Kumar与Reinartz(2016)[13]强调了通过客户关系管理(CRM)系统来降低客户流失率的重要性。此外,Cheng等人(2019)[14]通过分析大型数据集,发现了客户流失与银行服务特性之间的复杂关联。
通过国内国外对于客户流失文献的梳理,可以得出目前解决用户流失预测问题的技术及特点,这些方法大多是基于传统统计学和统计性学习等方法。这些方法的优点是对构建的模型有较强的可解释性,能够处理定类和连续性客户数据。但是,处理海量、多维、非线性的客户历史数据时效果不是很好;算法的泛化能力、灵活性比较差。因此,本文则采用逻辑回归算法,尝试得到更精准的结果。
本文创新之处主要有三点:
(1)以往关于客户流失预测的研究更多的是在电信行业、物流行业,针对银行客户的相对较少。而照搬其他行业的预测模型则由于不符合银行业客户的特点而缺乏科学性和合理性。因此,本文根据银行业客户特征,选取信用评分、地理位置、性别、年龄、成为客户的年限、客户存款余额、客户购买产品数量、客户是否持有信用卡、客户是否活跃、客户薪资等信息为特征变量,建立银行的流失预测模型。
(2)以往的研究工作,主要使用的是传统的回归计量模型。本文则采用机器学习手段中专门用于分类预测经典模型逻辑回归算法,从而做出更精准的预测。
(3)模型有较强的推广意义,本文的研究方法和建模方法也可以推广到其他行业。
2.数据描述
本文主要研究根据用户的特征信息判断是否存在潜在的流失风险,基于此研究主题进行数据集搜集。本文使用的数据集是来自于国际数据建模和数据分析竞赛平台Kaggle,数据集的内容是某银行在实际业务中获得的客户特征和行为数据。该银行的数据集已经过脱敏处理,仅供于学术研究和竞赛使用。
选择从该平台上获取银行客户流失的数据主要考虑到以下几个原因:第一,该平台是全球知名的数据平台,平台权威,数据的真实性有保证。第二,数据丰富且易得,可以满足训练要求。第三,Kaggle平台的案例丰富,而且靠近研究前沿,问题和数据都是来自于实际场景。
该数据集共计数据10000条,11个主要的变量字段,如表1所示。
表1 数据集主要的变量字段
| 字段名称 | 字段解释 |
| CustomerId | 客户ID |
| 客户的信用评分 | |
| Gender | 客户的性别 |
| 客户的年龄 | |
| Tenure | 客户成为银行客户的年数 |
| 客户的账户余额 | |
| NumOfProducts | 客户通过银行购买的产品数量 |
| HasCrCard | 客户是否持有信用卡 |
| IsActiveMember | 客户的交易行为是否活跃 |
| 客户的预期薪资 | |
| Exited | 标识流失的客户 |
注:数据来源于Kaggele平台
3.描述性统计
通过数据的可视化,对样本数据做一个初步的把握,便于后续的建模分析。
该数据集总体的客户流失率如图1所示,其中有20%的客户属于流失客户。
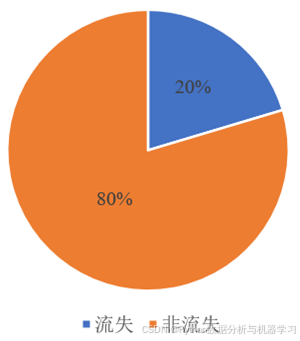
图1 流失客户与非流失客户占总客户数的比重
CreditScore即客户的信用评分这一变量的直方图如图2所示。由图可知,客户的信用评分集中在中高段,说明该银行客户的信用水平较高。
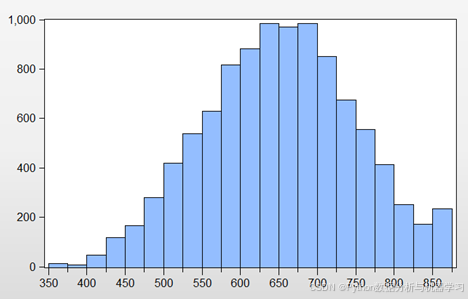
图2 客户信用评分的直方图
EstimatedSalary即客户的预期薪资这一变量的直方图如图3所示。由图可知,该银行的客户薪资水平分布较为平均,各个薪资水平都有数量相当的客户数量。
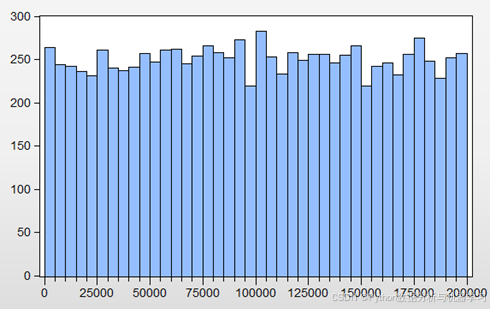
图3 客户预期薪资的直方图
Balance即客户的账户余额这一变量的直方图如图4所示。由图可知,该银行的客户账户余额分布集中在0-10000之间,这是由于原数据有很多客户的账户余额是0,这部分可能是流失的客户,因此清空了账户余额,也有可能该客户是一个交易十分活跃的客户,账户余额都用来消费或者投资了。
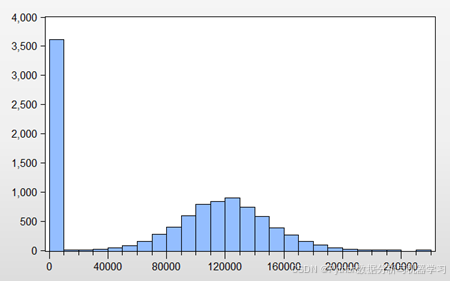
图4 客户账户余额的直方图
Age即客户年龄的分布直方图如图5所示。由图可知,该银行的客户年龄集中在20-50岁,以30-40岁为最多,这说明该银行的客户群体较为年轻。
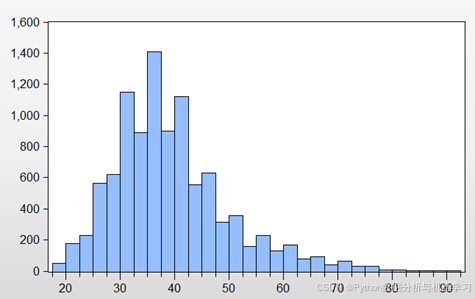
图5 客户年龄的直方图
该样本的性别分析如图6所示。男客户有5457人,女客户有4543人,男客户流失率为16.46%,女客户流失率为25.07%。男客户的客户流失率比女客户的低,初步推测客户性别可能与客户流失相关。
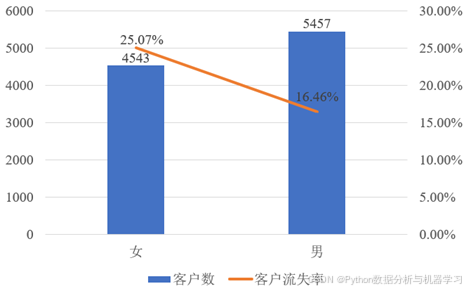
图6 客户的性别对比
如图7所示,该样本中持有信用卡的客户有7055人,其中20.18%为流失客户,无信用卡的客户有2945人,其中20.81%流失。总体来说,有无信用卡,客户流失的比例基本持平,初步推测是否持有信用卡对客户是否流失的影响不大。
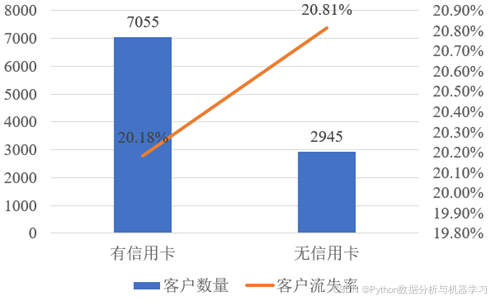
图7 客户持有信用卡情况对比
如图8所示,所有客户中是活跃客户的数量为5151,是非活跃客户的数量为4849,活跃客户的流失率是14.27%,非活跃客户的流失率是26.85%,这说明非活跃客户比活跃客户更容易流失,初步推测客户是否活跃是客户是否流失的一个重要因素。
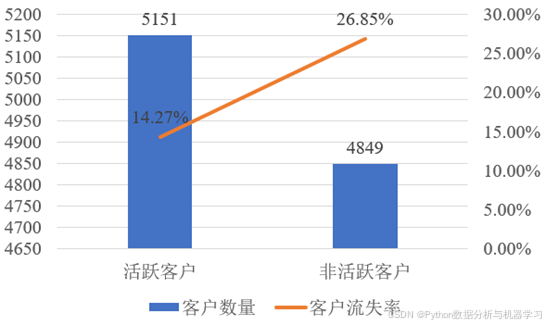
图8 活跃客户与非活跃客户对比
缺失值和异常值的处理:
首先,关注“客户ID”这一变量,因为该变量只是作为区分不同客户的标识,该变量本身与客户是否会流失没有关系,也没有反映样本的分布规律,在Python的建模代码中也没有实际作用,因此直接将其删除,接下来进行缺失值和异常值的处理。
数据集中某些变量的观测值不存在就称为缺失值,数据集中某些变量的观测值与正常范围相差很大就称为异常值。缺失值和异常值对于模型结果的影响十分大,因此必须十分重视。
对于缺失值,一般有多种处理方法,一种是直接删除含有缺失值的记录,一种是插值补充,插值补充的方法一般有三种,分别为均值插补、多重插补和极大似然估计。
而异常值实际上是数据分布常见的情况,异常值一般定义为偏离特定分布的数据。在统计上,有两种异常值,第一种是“伪异常”,这是由于实际的业务环境导致的异常,并不是数据本身存在异常。第二种叫做“真异常”,也就是数据本身存在着异常。对于“伪异常”一般会对其进行保留,不做过多处理,而对于“真异常”一般会进行删除或替换。
通过观察,本文所使用的数据并不存在缺失值和异常值,数据完整。
非数值型数据的数值化:
在机器学习中,数据通常被分为两种类型,一种是数值型数据,另一种是非数值型数据。非数值型数据不能直接被计算机识别,因此必须进行数值化,将非数值型数据转化为数值型数据,最常用的数值化方法是独热编码。所谓独热编码实际上就是引入虚拟变量,本文中只有性别这一个非数值型数据,性别是一个二分类变量,将“女性”用“0”代替,将“男性”用“1”代替,这样就完成了性别这一变量的数值化。
数据的标准化:
所谓标准化就是指统一量纲的操作,在使用数据时发现每个特征变量的量级并不统一,有的特征量级很大,有的就很小,对于这种情况,需要将数据按特定标准化方法进行缩放,使数据落在某个特定区间,比如[-1,1]或[0,1],从而统一量纲,提高建模结果的可靠性。
本文使用常用的Z-score标准化,通过Z-score标准化,标准化之后的数据落在均值为0、标准差为1的分布里。
Z-score标准化的公式如下:
数据的均衡化:
模型要判断客户是流失还是非流失,这实质上是一个二分类问题,对于二分类问题,两类数据的样本量如果差距过大,则存在一定的数据不均衡问题,如果使用不均衡的数据直接建模,那么会难以发掘内在规律,对少数类样本的识别率会很低,因此需要进行数据的均衡化[18]。
一般来说,数据均衡化有以下几种方法。第一,随机下采样,也称为随机欠采样,它是降低多数类样本量,降到与少数类样本量相等。第二,随机上采样,也称为随机过采样,其含义为随机复制数据集中现有的少数类样本,增大少数类样本的数量来实现数据类别的均衡,即着重强调已流失的客户数据。还有一种叫做SMOTE算法,它也属于过采样,这一算法可以看作随机过采样的优化算法。
前文的数据可视化说明流失与非流失客户的比例为2:8,这属于不均衡的样本,因此,本文将采用随机下采样的方法来进行数据的均衡化。
4.模型的建立
(1)模型概念
逻辑回归(Logistic Regression)是一种分类算法,适用于二分类问题。在银行客户流失预测的背景下,模型旨在预测客户是否会流失,即预测的目标变量是二元的(流失或未流失)。模型表示如下:
假设客户有n个特征x1,x2,x3.....xn和目标变量y,其中y取值为0和1。逻辑回归模型的公式可以表示为
其中,p是目标事件(客户流失)的概率,p0,p1p2......pn是模型参数,它们表示特征对于预测结果(在本研究中即客户流失的概率)的影响权重。上述公式的左边是事件发生概率与不发生概率的对数比(log-odds 或 logit function)。
为了将线性预测转化为概率,使用逻辑函数(sigmoid function):
这样,p的值被压缩在 0 和 1 之间,表示概率。
(2)模型的参数估计
参数p0,p1p2......pn通常通过最大似然估计(MLE)方法进行估计。最大似然估计选择参数值,使得观测到的样本数据出现的概率最大。在逻辑回归中,MLE通过迭代算法如梯度上升或牛顿-拉夫森(Newton-Raphson)方法来实现。许多现代统计软件(如 R, Python 的 scikit-learn)都提供了实现这些算法的功能。本文使用Pythoon进行模型搭建与求解。
5.模型的应用
(1)训练逻辑回归
本文利用Python的Sklearn库,选择LogisticRegression模型,在下采样达到数据均衡后,将下采样的训练集输入模型训练,测试集输入模型预测,最后输出预测值[19]。
模型在学习的时候应该能够充分考虑每个特征,而不是单独放大某个特征并依赖该特征进行结果预测,为此,在;逻辑回归模型部分,本文主要关注正则化惩罚力度这一参数,避免参数泛化程度过高或过低[20]。参数调优后正则化惩罚力度选取0.01,经过计算得到该模型的各项评价指标,以此评价该模型在测试集中的表现,评价指标如表2所示。
表2 Logistic回归模型的各项评价指标
| 评价指标 | 数值 |
| 准确率Accuracy | 69.0924% |
| 精确率Precision | 70.9565% |
| 召回率Recall | 65.9128% |
| AUC值 | 0.7367 |
注:数据通过Python中sklearn封装的评价指标函数计算得到
模型的ROC曲线如图9所示。
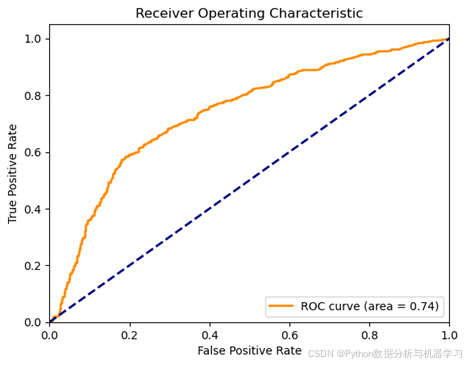
图9 逻辑回归模型ROC曲线
(2)评估模型性能
在对测试集上的数据进行预测时,通过参数调优,逻辑回归模型在各项评价指标上表现较好。下面分析参数调优后逻辑回归模型的预测结果。
较号的准确率说明该模型预测正确的比例有69.0924%,识别流失客户的能力较好。
精确率为70.9565%,这表明预测为流失客户是真正实际流失客户的比例达到70.9565%,将本该是未流失的客户预测成流失客户的概率较低,帮助降低银行维护客户成本。
召回率表明所有实际流失的客户中被正确预测为流失客户的比例达到65.9128%,这意味着很多本该是流失的客户但并没有被预测出来的概率较低,这意味着模型能很好地识别出流失的客户。
模型的AUC值约为0.74,大于0.5,说明分类器有效,且接近于1,说明模型的分类能力较好,且泛化能力较强。
(3)特征重要性分析
此外,为了进一步研究客户流失的因素,这里引入特征重要性,将每个特征的重要性量化之后排序,特征的重要性越高那么银行越应该关注[21]。因为逻辑回归模型不能用Python封装代码直接得到特征重要性,所以这里对模型的各个自变量的系数做了标准化处理,处理之后的系数可以在一定程度上反映各特征变量的重要程度。特征变量重要性的排名依次为:Age、IsActiveMember、Balance、Gender、HasCrCard、CreditScore、Tenure、NumOfProducts、EstimatedSalary。
下面对较为重要的三个特征进行分析,继而说明银行客户流失的原因。
在Age即客户的年龄方面,年轻人通常会比老年人更有可能流失。一方面,银行在当今网络时代的网络经营能力不足,平台服务较差,缺乏良好的交互式营销,银行APP的操作可能比较复杂,界面比较混乱,年轻人更倾向于使用移动支付软件,购买金融产品也通常在网络平台和其他理财APP上,这使得他们慢慢脱离银行的部分服务。另一方面,老年人较为稳定,对现代移动支付手段使用不熟练,更倾向银行的传统式服务。
在IsActiveMember即客户交易行为是否活跃方面,交易时间相隔越短说明越活跃,活跃的客户一般流失的概率比较小,而不活跃的客户则需要银行的重点关注。
在Balance即客户账户余额方面,客户余额越高,一般银行对其的服务会越好,资产高的客户属于高价值客户,这一部分是银行不容忽视的客户群体。客户选择在某银行保留大量的余额,说明客户信任银行,拥有高账户余额的客户更不容易流失,账户余额也在一定程度上反映了客户忠诚度。
6.结论与建议
本文主要贡献在于首先,构建了银行客户流失预测模型,基于逻辑回归算法,针对银行客户特征选取了信用评分、地理位置、性别、年龄、成为客户的年限、客户存款余额、客户购买产品数量、客户是否持有信用卡、客户是否活跃、客户薪资等信息作为特征变量,实现了对客户流失的预测。
之后,采用实证分析中专门用于分类预测经典模型逻辑回归算法,得到了较为精准的预测结果。通过参数调优,模型在测试集上取得了良好的准确率、精确率和召回率,AUC值也表明了模型的有效性和泛化能力。
然后,对银行客户流失的相关因素进行了深入的分析,通过特征重要性排序和解释,揭示了客户年龄、交易行为活跃程度和账户余额等因素与客户流失之间的关系,为银行提供了决策支持和优化客户管理策略的依据。
最后,通过数据描述统计、可视化分析以及数据预处理,全面展示了数据集的特点和处理过程,为模型的建立和分析提供了有效的数据基础。
基于本文的研究提出以下建议:
(1)银行可以建立基于逻辑回归的银行客户流失预测模型,并及时更新优化。在实际与客户的存款、贷款、理财以及其他各项业务中,银行应当及时收集客户行为数据,更新数据集,将数据与模型联网,确保客户数据的实时更新,关注重要的特征变量,定期调整优化模型的参数,改善模型的表现,识别出潜在的流失客户,并使用模型得到的重要特征变量结果,分析客户具体的流失原因,针对性地开展相应的客户挽留工作。值得注意的是,虽然本文结果表明逻辑回归模型效果较好,但是这并不意味着适用于所有银行,也不意味着模型就是一成不变的,随着业务场景的变化和客户数据的更新,银行也应当结合自身情况,根据实际的发展现状及时调整模型,发掘新的有价值的客户特征,更新模型参数,或者更换其他模型,使识别客户流失的工作更加精细高效。
(2)提供个性化产品和服务。基于前文对Age和IsActiveMember的分析,建议银行应当转变产品设计思路,提供个性化的产品和服务,抓住年轻客户群体,促进客户持有产品数量的提高。这在现实生活中就有很好的例子,比如招商银行就发行了一些联名“一卡通”,“一卡通”是招商银行向社会大众提供的、以真实姓名开户的个人理财基本账户,它集定活期储蓄、多储种、多币种、多功能于一卡[22]。这些联名“一卡通”一般是以一些热门的二次元游戏动漫形象设计卡面,十分精美,比如“哔哩哔哩花嫁联名卡”、“航海王联名卡”、“明日方舟联名卡”等,吸引了大批年轻人办理招商银行“一卡通”。“颜值控”“个性化”“娱乐化”反映了当代年轻人的消费观,银行卡的高颜值卡面和实用贴心的权益是打动“Z世代”的重要因素[23]。
(3)完善网络经营战略。基于前文对Age的分析,建议银行提高银行APP使用体验,太过复杂的操作和混乱的界面会劝退客户,银行应当减少复杂的操作,降低客户的操作成本,做好交互式营销,提升网络平台的服务质量[24]。在本质上,银行APP不是银行的一种产品,而是一种服务方式,在设计银行APP时应注意技术的安全性、反馈的及时性、操作的便捷性和界面友好度,下面以中国建设银行的APP“手机银行2023”为例进行说明。“手机银行2023”应用了智能风控大脑、高危账户管理、终端识别、位置定位、可信环境识别和“声颜保”声纹人脸识别等多种创新的智能安全技术手段,兼顾了APP的安全保护与客户使用体验;“手机银行2023”坚持简约化的设计理念,高频使用的功能都控制在三次操作之内进入,五次操作之内完成,反馈及时,操作便携;“手机银行2023”删除了过期冗余的信息,整合了重复的功能,流畅化交互设计,在一些常规操作中智能预测客户意图,减少需要选择和输入的信息,操作流畅,界面清新简约,十分友好。
(4)结合挽留的成本和收益,明确挽留对象,制定精准的客户维护策略。基于前文对IsActiveMember和Balance的分析,建议银行挽留客户精准化、差异化。具体来讲,并不是所有的客户都要挽留,对于流失可能性极大,但是并没有太高的账户余额,也没有购买过产品和服务,交易也不活跃的这类低价值客户,银行完全可以选择不挽留,因为挽留的成本比收益还要大。银行应该重点挽留高价值且高流失概率的客户,设置“一对一”的经验丰富的客户经理,详细沟通,确定具体的挽留策略。而对于客户价值高、流失概率低的这部分核心客户要设置专门的客户经理对接需求。对于客户价值较低、流失概率也较低的客户则主要以宣传和激励为主,如使用银行卡消费可获得打折券或奖励金来激发客户的消费,宣传银行的理财产品,激发他们购买银行的理财产品等[25]。
参考文献
- 朱凡, 李思, & 张敏. (2021). 航空公司客户流失预测模型研究. 中国管理科学, 29(2), 123-135.
- 董纪阳. (2020). 基金客户流失预测模型的构建与评价. 现代管理科学, 12, 88-95.
- 郑红, 刘杰, & 王星. (2020). 基于自助采样法的Stacking集成学习方法研究. 计算机工程与应用, 56(7), 114-120.
- 邓致. (2019). 信用卡客户流失预测模型的比较研究. 金融研究, 41(4), 192-204.
- 王华, 张志强, & 陈效民. (2010). 基于客户流失的商业银行服务质量评价研究. 管理科学学报, 13(3), 36-47.
- 中华人民共和国银行业监督管理法. (2015). 北京: 中国金融出版社.
- Lalwani, P., & Kumar, S. (2021). An Empirical Approach to Predict Customer Churn in Banking Sector Using Machine Learning Techniques. Expert Systems with Applications, 158, 113498.
- Swetha, P., Kumar, A., & Raj, G. (2020). Predictive Modelling of Customer Churn in Telecom Industry Using Improvised-XGBoost. Data Science Journal, 19(1), 1-12.
- Qiu, Y. (2017). EBURM: An E-commerce User Behavior Risk Model for Customer Churn Prediction. International Journal of Information Management, 37(3), 144-150.
- Smith, A. K., Bolton, R. N., & Wagner, J. (1982). A model of customer satisfaction with service encounters involving failure and recovery. Journal of Marketing Research, 19(3), 35-48.
- Hosmer, D. W., Lemeshow, S., & Sturdivant, R. X. (2000). Applied Logistic Regression. John Wiley & Sons.
- Johnson, E., & Zhao, X. (2018). FinTech and the Disruption of Financial Institutions: A View on Client Churn and Banking Services. Journal of Financial Innovation, 4(1), 12-24.
- Kumar, V., & Reinartz, W. (2016). Creating Enduring Customer Value. Journal of Marketing, 80(6), 28-45.
- Cheng, L., Liu, Y., & Yao, D. (2019). Predictive Analysis of Banking Customer Churn in Massive Datasets. Big Data Research, 5(2), 103-115.
- 李颖.基于机器学习的客户流失问题研究[D].大连理工大学,2020.
- 杨杏丽.分类学习算法的性能度量指标综述[J].计算机科学,2021,48(08):209-219.
- 王彦光,朱鸿斌,徐维超.ROC曲线及其分析方法综述[J].广东工业大学学报,2021,38(01):46-53.
- 衷宇清,陈文文,李昭桦.不平衡数据分类中的数据重采样比较研究[J]. 通信技术,2020,53(06):1376-1384.
- 王娟,华东,罗建平.Python编程基础与数据分析[M].南京大学出版社:信息素养文库, 201908.219.
- 杨文婷.基于Logistic回归和决策树算法的客户流失预测研究[D].大连理工大学,2019.
- 付雷.银行客户流失预警及模型可解释性分析[D].华中农业大学,2022.
- 董成. “一卡通”:一个创新符号的诞生[J]. 中国金融家,2008,(08):83-85.
- 谢香玲.信用卡拥抱“Z世代”:精准聚焦,创新营销[J].中国信用卡,2022,No.311(04):34-36.
- 张婕.互联网金融对传统银行业的影响[J].合作经济与科技,2020,(23):82-83.
- 王波.高价值客户流失预警及挽留策略分析[J].中国新通信,2015,17(01):13.



















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











