









目录
1. 前言
随着人工智能技术的飞速发展,神经网络在众多领域展现出了巨大的潜力。前馈神经网络,作为神经网络的一种基本类型,以其简单而强大的函数逼近能力,在控制领域同样发挥着重要作用。本文将深入探讨前馈神经网络在控制任务中的应用,通过理论讲解与实际代码示例相结合的方式,帮助读者全面理解前馈神经网络控制的原理与实现。
2. 前馈神经网络控制与神经网络直接逆控制的区别与联系
-
前馈神经网络控制:通过构建一个前馈神经网络,将系统的当前状态或输入信号作为网络的输入,经过网络的非线性变换,直接输出控制信号,以实现对系统的控制。该控制方法侧重于利用神经网络强大的非线性映射能力,学习输入与期望输出之间的关系,从而实现对系统的精确控制。
-
神经网络直接逆控制:原理是构建一个神经网络来近似被控对象的逆模型,即直接逆模型。输入为期望的系统输出,输出为实现该期望输出应施加的控制信号。在控制过程中,将期望的输出输入到直接逆模型中,得到相应的控制信号并作用于实际系统,从而使系统输出接近期望值。其核心在于利用神经网络对被控对象的逆过程进行建模,通过逆模型来生成合适的控制信号。
3. 前馈神经网络控制的应用场景
前馈神经网络控制可以广泛应用于各种控制系统,包括但不限于以下场景:
-
工业过程控制:如温度、压力、流量等参数的精确控制。
-
机器人控制:实现机器人的运动轨迹规划与姿态控制。
-
自动驾驶:用于车辆的路径规划与障碍物避让。
-
无人机控制:实现无人机的飞行姿态调整与航线跟踪。
-
智能家居:控制家电设备的智能运行,如空调的温度调节、智能灯光的亮度控制等。
4. 前馈神经网络控制的实现步骤
-
定义网络结构:确定输入层、隐藏层和输出层的神经元数量,并选择合适的激活函数。
-
初始化网络参数:对网络的权重和偏置进行初始化。
-
构建控制环境:建立被控系统的数学模型或仿真环境。
-
设计控制算法:将前馈神经网络的输出与被控系统的输入相结合,形成控制闭环。
-
训练网络:利用历史数据或仿真数据,通过反向传播算法对网络进行训练,优化网络参数。
-
评估与优化:对训练后的网络进行性能评估,根据评估结果对网络结构或训练参数进行调整优化。
5. 前馈神经网络控制实例:无人机高度控制
以下是一个使用 Pytorch 构建前馈神经网络控制无人机高度的完整实例。
5.1 定义网络结构
import torch
import torch.nn as nn
import torch.optim as optim
# 定义前馈神经网络控制器
class FFNNController(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(FFNNController, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x5.2 初始化网络参数
# 输入为无人机当前高度和目标高度,输出为控制信号(如桨速调整)
input_size = 2
hidden_size = 128
output_size = 1
# 初始化网络
model = FFNNController(input_size, hidden_size, output_size)
# 初始化权重和偏置
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
model.apply(init_weights)在 Xavier 初始化中,权重矩阵的元素从一个均匀分布中采样:
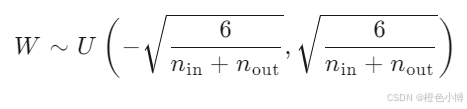
其中:
-
W 是权重矩阵;
-
U 表示均匀分布;
-
nin 是当前层的输入单元数;
-
nout 是当前层的输出单元数。
这样初始化的目的是使得每一层的输入和输出的方差大致相同,从而保证信号在神经网络中的稳定传播。
5.3 构建控制环境(无人机高度模拟)
class DroneEnvironment:
def __init__(self):
self.current_height = 0.0 # 初始高度
self.target_height = 5.0 # 目标高度
self.dt = 0.1 # 时间步长
def step(self, control_signal):
# 根据控制信号更新无人机高度(简化模型)
self.current_height += control_signal * self.dt
# 计算高度误差
height_error = self.target_height - self.current_height
# 计算奖励(与高度误差成反比)
reward = -abs(height_error)
return height_error, reward
def reset(self):
self.current_height = 0.0
return self.current_height - self.target_height5.4 设计控制算法(训练过程)
# 训练超参数
num_episodes = 1000
learning_rate = 0.001
discount_factor = 0.99
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 训练过程
for episode in range(num_episodes):
env = DroneEnvironment()
state = env.reset()
state = torch.tensor([state, 0.0], dtype=torch.float32) # 输入包括当前高度误差和上一时刻的高度误差
total_reward = 0.0
episode_loss = 0.0
for t in range(100): # 每个episode的最大时间步数
# 前向传播
control_signal = model(state)
# 与环境交互
next_state_val, reward = env.step(control_signal.item())
next_state_val_with_diff = next_state_val # 本例中简化了状态表示
next_state = torch.tensor([next_state_val_with_diff, next_state_val], dtype=torch.float32)
# 计算损失(这里简化为直接使用当前状态误差作为损失)
target = torch.tensor([next_state_val], dtype=torch.float32)
loss = criterion(control_signal, target)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新状态和累积奖励
state = next_state
total_reward += reward
episode_loss += loss.item()
# 打印训练进度
if (episode + 1) % 100 == 0:
print(f"Episode [{episode+1}/{num_episodes}], Loss: {episode_loss:.4f}, Total Reward: {total_reward:.2f}")5.5 测试控制效果
# 测试训练好的控制器
env_test = DroneEnvironment()
state = env_test.reset()
state = torch.tensor([state, 0.0], dtype=torch.float32)
height_trajectory = [env_test.current_height]
for t in range(100):
control_signal = model(state)
_, _ = env_test.step(control_signal.item())
state = torch.tensor([env_test.target_height - env_test.current_height, env_test.current_height - env_test.target_height], dtype=torch.float32)
height_trajectory.append(env_test.current_height)
# 绘制高度变化曲线
import matplotlib.pyplot as plt
plt.plot(height_trajectory)
plt.axhline(y=env_test.target_height, color='r', linestyle='--')
plt.xlabel('Time Step')
plt.ylabel('Height')
plt.title('Drone Height Tracking using FFNN Controller')
plt.grid(True)
plt.show()5.6 完整代码
完整代码如下方便调试:
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import tqdm
# 定义前馈神经网络控制器
class FFNNController(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(FFNNController, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
# 输入为无人机当前高度和目标高度,输出为控制信号(如桨速调整)
input_size = 2
hidden_size = 128
output_size = 1
# 初始化网络
model = FFNNController(input_size, hidden_size, output_size)
# 初始化权重和偏置
def init_weights(m):
if type(m) == nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
model.apply(init_weights)
class DroneEnvironment:
def __init__(self):
self.current_height = 0.0 # 初始高度
self.target_height = 5.0 # 目标高度
self.dt = 0.1 # 时间步长
def step(self, control_signal):
# 根据控制信号更新无人机高度(简化模型)
self.current_height += control_signal * self.dt
# 计算高度误差
height_error = self.target_height - self.current_height
# 计算奖励(与高度误差成反比)
reward = -abs(height_error)
return height_error, reward
def reset(self):
self.current_height = 0.0
return self.current_height - self.target_height
# 训练超参数
num_episodes = 1000
learning_rate = 0.001
discount_factor = 0.99
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
# 训练过程
for episode in range(num_episodes):
env = DroneEnvironment()
state = env.reset()
state = torch.tensor([state, 0.0], dtype=torch.float32) # 输入包括当前高度误差和上一时刻的高度误差
total_reward = 0.0
episode_loss = 0.0
for t in range(100): # 每个episode的最大时间步数
# 前向传播
control_signal = model(state)
# 与环境交互
next_state_val, reward = env.step(control_signal.item())
next_state = torch.tensor([next_state_val, state[0].item()], dtype=torch.float32)
# 计算损失(这里简化为直接使用当前状态误差作为损失)
target = torch.tensor([next_state_val], dtype=torch.float32)
loss = criterion(control_signal, target)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新状态和累积奖励
state = next_state
total_reward += reward
episode_loss += loss.item()
# 打印训练进度
if (episode + 1) % 100 == 0:
print(f"Episode [{episode + 1}/{num_episodes}], Loss: {episode_loss:.4f}, Total Reward: {total_reward:.2f}")
# 测试训练好的控制器
env_test = DroneEnvironment()
state = env_test.reset()
state = torch.tensor([state, 0.0], dtype=torch.float32)
height_trajectory = [env_test.current_height]
for t in range(100):
control_signal = model(state)
_, _ = env_test.step(control_signal.item())
state = torch.tensor(
[env_test.target_height - env_test.current_height, state[0].item()],
dtype=torch.float32)
height_trajectory.append(env_test.current_height)
plt.plot(height_trajectory)
plt.axhline(y=env_test.target_height, color='r', linestyle='--')
plt.xlabel('Time Step')
plt.ylabel('Height')
plt.title('Drone Height Tracking using FFNN Controller')
plt.grid(True)
plt.show()6. 前馈神经网络控制的优势与挑战
-
优势:
-
非线性控制能力:能够处理复杂的非线性系统,解决传统线性控制方法难以应对的问题。
-
自适应性:通过训练可以自动调整控制策略,适应系统的动态变化。
-
泛化能力:在训练数据覆盖范围内,对未见过的输入情况也能产生合理的控制输出。
-
-
挑战:
-
训练数据需求:需要大量高质量的训练数据来保证网络的性能。
-
训练时间:复杂网络的训练过程可能非常耗时,需要强大的计算资源支持。
-
超参数调整:网络结构、学习率等超参数的选择对控制效果有重要影响,需要进行大量实验进行优化。
-
稳定性保障:由于网络的黑箱特性,保证控制系统的稳定性具有一定难度,需要结合稳定性分析方法。
-
7. 总结
前馈神经网络控制作为一种新兴的控制技术,在理论研究和实际应用中都展现出了巨大的潜力。通过本文的介绍和实例演示,我们深入了解了前馈神经网络控制的基本原理、实现步骤以及在无人机高度控制中的具体应用。我是橙色小博,关注我,一起在人工智能领域学习进步!


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











