







写在前面:数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集,若无法下载可关注后私信领取。关注免费领取整理好的数据集资料!今天分享一个非常好的非常小众的研究方向,有应用创新,可有利于发小论文和大论文,有需要的朋友可私信我。
百度网盘链接:https://pan.baidu.com/s/1VbuZlaFcCPuTPf9XuyOV0w
提取码:关注后私信
话不多说直接上图:本天池布匹瑕疵数据集样本图如下所示 ,分为7个类别names:
0:污渍
1:三丝
2:结头
3:浆斑
4:松经
5:粗维




对数据集进行可视化分析,得到如图所示:
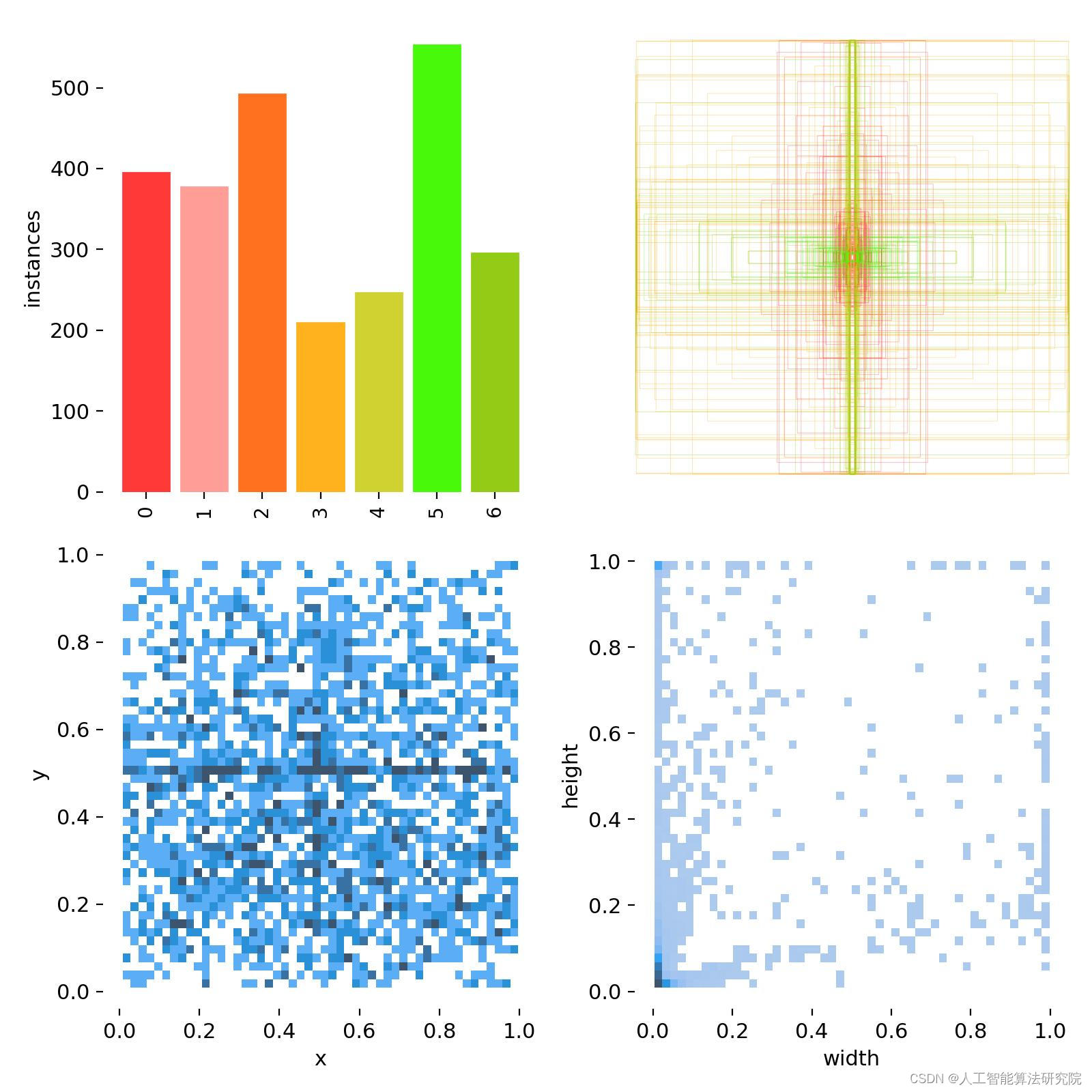
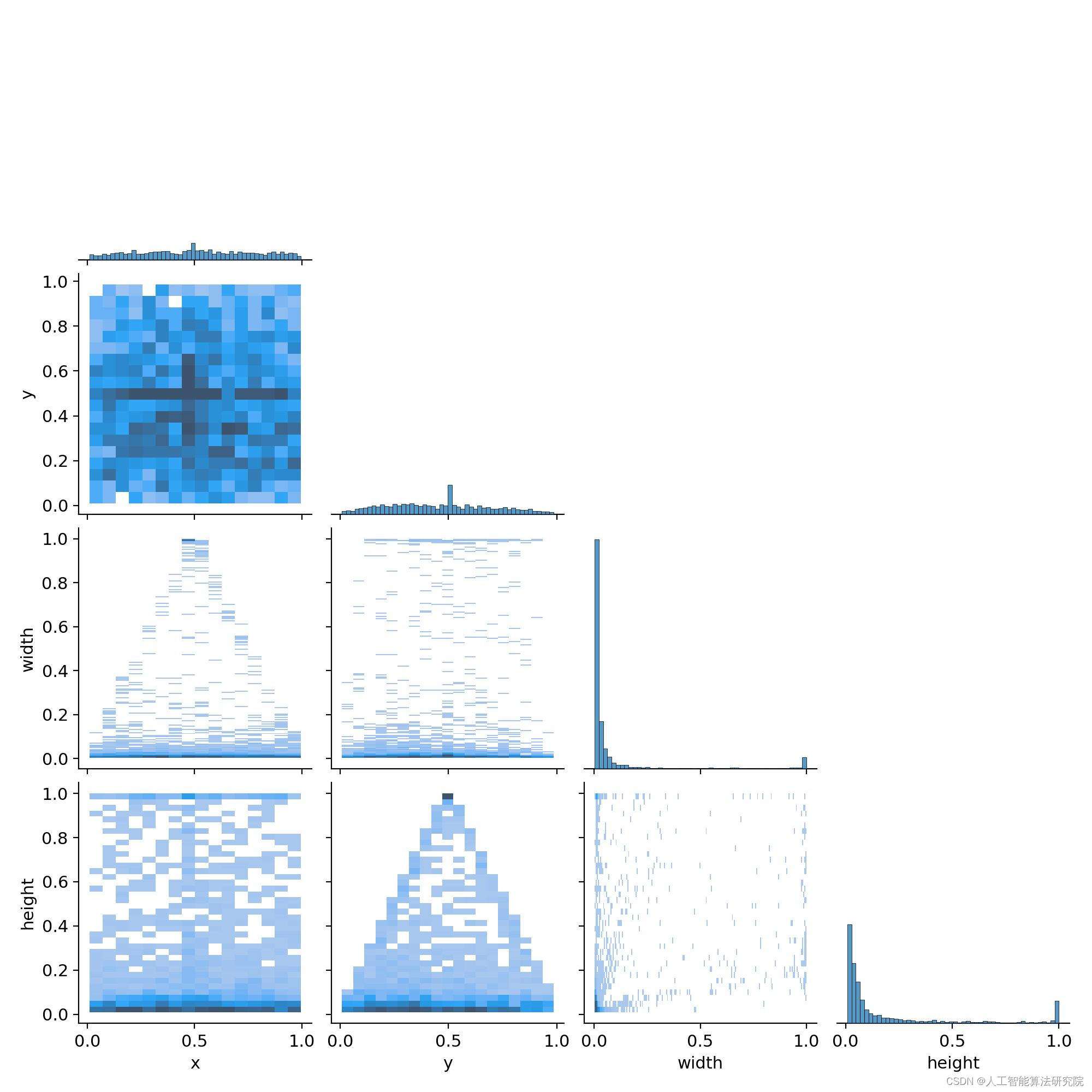

数据集一共2496张图片。原数据集格式为json格式,已转换为YOLO格式。
非常好的非常小众的研究方向,有应用创新,可有利于发小论文和大论文,有需要的朋友可私信我。
















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











