







在我的项目中,采用了 BM25 关键字检索 和 向量语义检索 的混合检索策略。
为什么要融入 BM25,构造混合检索?
- 为什么要引入
BM25?一开始项目是只用向量检索的,有一次我问了一个问题“重排序是什么?”,八条向量检索都没有捕获到“重排序”片段,因为在原文中,“重排序”也只出现了一次,在一个小点中一笔带过。所以光靠向量检索不能够捕捉到这样微小的字眼。

- 向量检索全军覆没
- 通过查阅RAG优化相关文献,我了解到:采用 BM25 捕获特定的关键字的精确匹配,与向量语义检索的互补混合策略。这就是解决我们当前需求的不二法门。
思考怎么实现
-
要实现
BM25和 向量检索 的混合检索策略,首先先要有BM25的检索方法,我们可以用 Langchain 组件BM25Retriever, 要混合检索结果,可以用EnsembleRetriever(挺有意思的是ensemble是合奏的意思) -
接着还要考虑到怎么和重排序逻辑整合?是先混合检索结果再重排序,还是先把向量检索进行重排序再混合?最终我选择了后者,为什么不选前者?因为你看,回到一切都开始,你还记得我们为什么要引入
bm25吗?—— 因为向量检索不到我问的问题“重排序是什么”,为什么检索不到,因为这个片段的向量相似度很低很低;而重排序也是一个根据向量相似度来排序的方法,只不过它精度更高;如果先混合结果再全部重排序,那很可能就把那唯一一个包含了关键字"重排序"的片段给淘汰掉了。所以我选择了先把向量检索进行重排序再混合bm25检索结果。
具体怎么实现的?
BM25Retriever
-
BM25Retriever需要在初始化时传入原始的文档列表 (List[Document])所以现在问题就变成了————怎么提供原文片段列表?
我记得在上传知识库文件的时候,文档分块、向量化后,原文档片段和向量是一起存储在
ChromaDB里的,那能不能直接从ChromaDB拿我们要的原文片段列表?我查阅了
langchain-chroma的文档,发现可以用Chroma实例的get()方法来获取指定集合(由kb_id确定)内的所有文档内容和元数据,只需要在调用时指定include=["documents", "metadatas"]。chroma_get_result = vectorstore.get( where=filter_dict, include=["documents", "metadatas"] ) -
但一个问题只有
get同步方法,这会阻塞事件循环,影响性能。
———— 我们可以用asyncio.to_thread(),解决在异步函数中调用同步阻塞代码
import asyncio
chroma_get_result = await asyncio.to_thread(
vectorstore.get, # 要在线程中运行的函数
where=filter_dict, # 传递给 vectorstore.get 的参数
include=["documents", "metadatas"] # 传递给 vectorstore.get 的参数
)
有的小伙伴可能就要问了:主包主包,为什么asyncio.to_thread()就可以解决这个问题? 这就有意思了,asyncio.to_thread()背后干了什么不为人知的秘密?你想不想知道??哎,欲知后事如何,且听下期分解(诶嘿!【挖坑待填:xx🔗】)
潜在的性能瓶颈
只有get同步方法,会阻塞事件循环。———— 用asyncio.toThread()
以及 chroma 查询文档的性能可能不及 MongoDB
后续可以使用MongoDB来存储一份原文档片段?实现难度:中等
需要查看全文 PDF,可以在这里 0 积分下载: 【免费】RAGLangchain项目BM25与向量语义检索混合策略CSDN文库
EnsembleRetriever
-
有了
BM25Retriever,就需要来考虑具体怎么用EnsembleRetriever混合检索结果了。EnsembleRetriever。这个组件接收一个检索器列表(即BM25Retriever和Chroma的 retriever),并使用倒数排序融合 (Reciprocal Rank Fusion, RRF) 算法来合并和重新排序它们各自返回的文档。
final_retriever= EnsembleRetriever(
retrievers=[bm25_retriever, base_retriever],
weights=[0.5, 0.5],
)
- 与重排序逻辑的整合(
ContextualCompressionRetriever)
-
如果启用了重排序,那么
EnsembleRetriever会组合BM25Retriever和 经过重排序的向量检索器 (ContextualCompressionRetriever实例)。这样可以确保 BM25 的结果和被重排序器优化过的向量检索结果一起进行最终的 RRF 融合。 -
如果未启用重排序,
EnsembleRetriever就直接组合BM25Retriever和原始的向量检索器 (Chroma的 retriever)。 -
核心源码:
# --- 4. 确定最终检索器 ---
final_retriever: BaseRetriever
if self.use_reranker:
# --- 场景 A: 使用重排序 ---
logger.info(
f"启用重排序 (类型: {self.reranker_type}, TopN: {self.rerank_top_n}),正在配置 ContextualCompressionRetriever..."
)
compressor: Optional[BaseDocumentCompressor] = None
# ... (现有创建 compressor 的逻辑不变,基于 self.reranker_type) ...
try:
if self.reranker_type == "local":
# ... (加载本地 reranker) ...
encoder_model = HuggingFaceCrossEncoder(
model_name=self.local_rerank_model_path,
model_kwargs={"device": "cpu"},
) # 示例
compressor = CrossEncoderReranker(
model=encoder_model, top_n=self.rerank_top_n
)
logger.info("本地 CrossEncoderReranker 初始化成功。")
elif self.reranker_type == "remote":
# ... (加载远程 reranker) ...
if self.remote_rerank_config and self.remote_rerank_config.get(
"api_key"
):
compressor = RemoteRerankerCompressor(
api_key=self.remote_rerank_config["api_key"],
model_name=self.remote_rerank_config.get(
"model", DEFAULT_REMOTE_RERANK_MODEL
),
top_n=self.rerank_top_n,
)
logger.info("远程 RemoteRerankerCompressor 初始化成功。")
else:
logger.error("无法初始化远程 Reranker: 缺少 API Key。")
# 这里 compressor 会是 None
# 如果 compressor 创建失败,打印警告
if not compressor:
logger.warning("未能创建 Reranker Compressor。将跳过重排序步骤。")
# 如果 reranker 创建失败,退回到无 reranker 的逻辑
# 检查是否需要 BM25
if self.use_bm25 and bm25_retriever:
logger.info(
"Reranker失败,但启用BM25。使用 EnsembleRetriever 组合 BM25 和基础向量检索器。"
)
final_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, base_retriever],
weights=[0.5, 0.5],
)
else:
logger.info(
"Reranker失败,且未启用BM25。仅使用基础向量检索器。"
)
final_retriever = base_retriever
else:
# Compressor 创建成功,创建 ContextualCompressionRetriever
reranked_vector_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=base_retriever
)
logger.info(
"ContextualCompressionRetriever (重排序向量检索器) 创建成功。"
)
# 根据是否启用 BM25 组合
if self.use_bm25 and bm25_retriever:
logger.info(
"启用重排序和BM25。使用 EnsembleRetriever 组合 BM25 和重排序后的向量检索器。"
)
# 组合 BM25 和 重排序后的向量检索器
final_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, reranked_vector_retriever],
weights=[
0.5,
0.5,
], # weights 可以调整或移除,RRF 主要看排名
)
else:
logger.info(
"启用重排序,但未启用BM25 (或BM25初始化失败)。仅使用重排序后的向量检索器。"
)
final_retriever = reranked_vector_retriever
except Exception as e:
logger.error(
f"创建重排序 Compressor 或 ContextualCompressionRetriever 时出错: {e}",
exc_info=True,
)
# 出错时,回退到基础检索器或 BM25+基础检索器
logger.warning("重排序流程出错,将回退。")
if self.use_bm25 and bm25_retriever:
logger.info(
"回退:使用 EnsembleRetriever 组合 BM25 和基础向量检索器。"
)
final_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, base_retriever], weights=[0.5, 0.5]
)
else:
logger.info("回退:仅使用基础向量检索器。")
final_retriever = base_retriever
else:
# --- 场景 B: 不使用重排序 ---
logger.info("重排序未启用。")
if self.use_bm25 and bm25_retriever:
logger.info(
"未启用重排序,但启用BM25。使用 EnsembleRetriever 组合 BM25 和基础向量检索器。"
)
# 组合 BM25 和 基础向量检索器
final_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, base_retriever],
weights=[0.5, 0.5], # weights 可以调整或移除
)
else:
logger.info(
"未启用重排序,且未启用BM25 (或BM25初始化失败)。仅使用基础向量检索器。"
)
final_retriever = base_retriever
logger.info(f"最终返回的检索器类型: {type(final_retriever)}")
return final_retriever
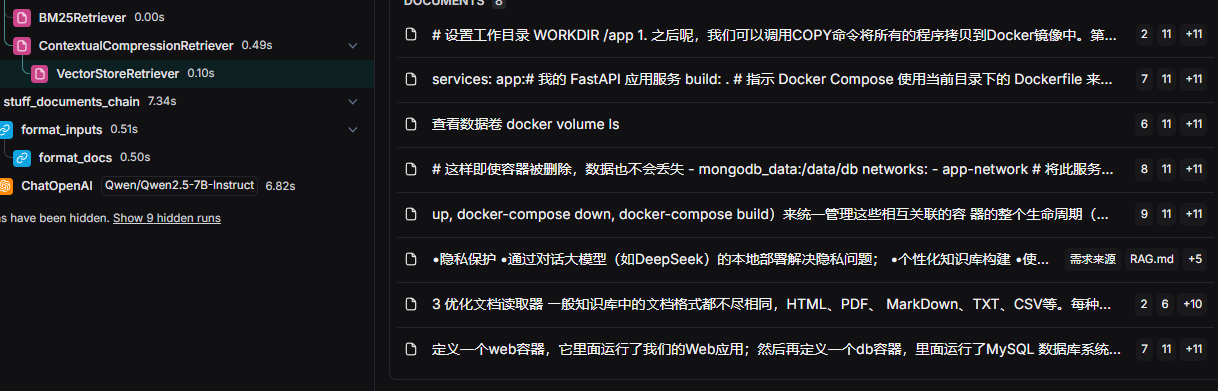
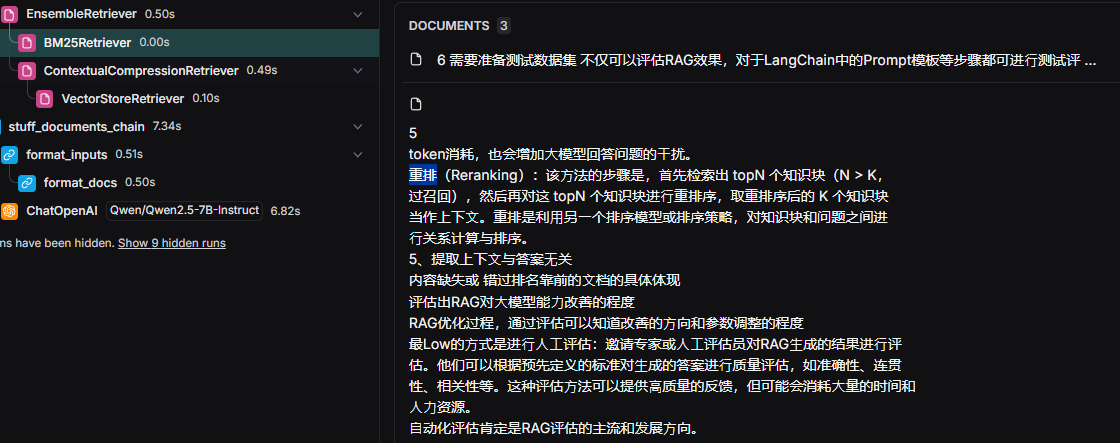
看效果
-
bm25 拿到了相关片段
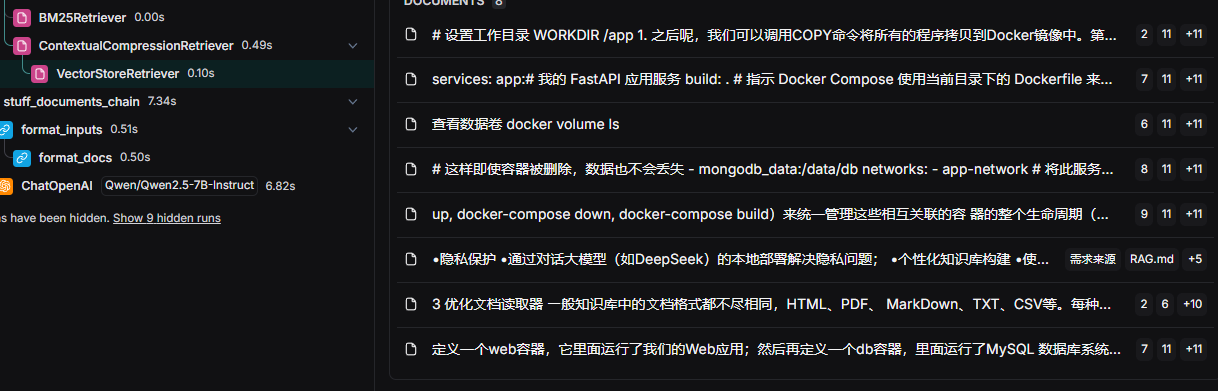
-
向量检索全军覆没
关于作者
- CSDN 大三小白新手菜鸟咸鱼本科生长期更新强烈建议不要关注!
作者的其他文章
RAG调优|AI聊天|知识库问答
- 你是一名平平无奇的大三生,你投递了简历和上线的项目链接,结果HR真打开链接看!结果还报错登不进去QAQ!【RAG知识库问答系统】新增模型混用提示和报错排查【用户反馈与优化-2025.04.28-CSDN博客
- 你知不知道像打字机一样的流式输出效果是怎么实现的?AI聊天项目实战经验:流式输出的前后端完整实现!图文解说与源码地址(LangcahinAI,RAG,fastapi,Vue,python,SSE)-CSDN博客
- 【豆包写的标题…】《震惊!重排序为啥是 RAG 调优杀手锏?大学生实战项目,0 基础也能白嫖学起来》(Langchain-CSDN博客
- 【Langchain】RAG 优化:提高语义完整性、向量相关性、召回率–从字符分割到语义分块 (SemanticChunker)-CSDN博客
- 【RAG】向量?知识库的底层原理:向量数据库の技术鉴赏 | HNSW(导航小世界)、LSH、K-means-CSDN博客


















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











