






量表使用论文来源:Lighting environmental assessment in enclosed spaces based on emotional model
论文原话:CATA 方法是一种用于快速从消费者处获取产品感官特征的提问形式,在食品研究领域应用较为广泛(Vidal 等,2019(Vidal, L., Antúnez, L., Ares, G., Cuffia, F., Lee, P.-Y., Le Blond, M., Jaeger, S.R., 2019. Sensory product characterisations based on check-all-that-apply questions: further insights on how the static (CATA) and dynamic (TCATA) approaches perform. Food Res. Int. 125, 108510. https://doi.org/10.1016/j.foodres.2019.108510.);Varela 和 Ares,2012(Varela, P., Ares, G., 2012. Sensory profiling, the blurred line between sensory and consumer scienceA review of novel methods for product characterization. Food Research Interna tional 48 (2), 893–908. https://doi.org/10.1016/j.foodres.2012.06.037.))。
参与者首先会看到一个属性列表,并被要求指出表中哪些短语或单词能恰当地描述被评估对象的感官体验。从列表中选择描述词的任务非常简单直观,减轻了参与者的答题负担。因此,近年来在各种对象的特征描述中应用越来越广泛。使用 CATA 方法时,通常还会结合参与者对被评估对象的偏好得分,但偏好容易受到描述项的影响,所以参与者的偏好得分通常放在 CATA 问题之前。在选择用于封闭空间照明环境主观情感评价的词语时,参考了 VA 模型中的情感词汇进行组织和总结,最终选择了 25 个描述词用于实验(图 6)。为避免实验误差,参与者在评估不同照明设置时,列表中描述词的顺序会被打乱。情感模型在本实验中的作用是提供一组合理的情感形容词。我们目前仅基于 CATA 完成对照明设置的氛围评估,暂不考虑开发惩罚分析来指导照明设计方向,所以没有设计喜好程度评分问卷。

matlab代码复现
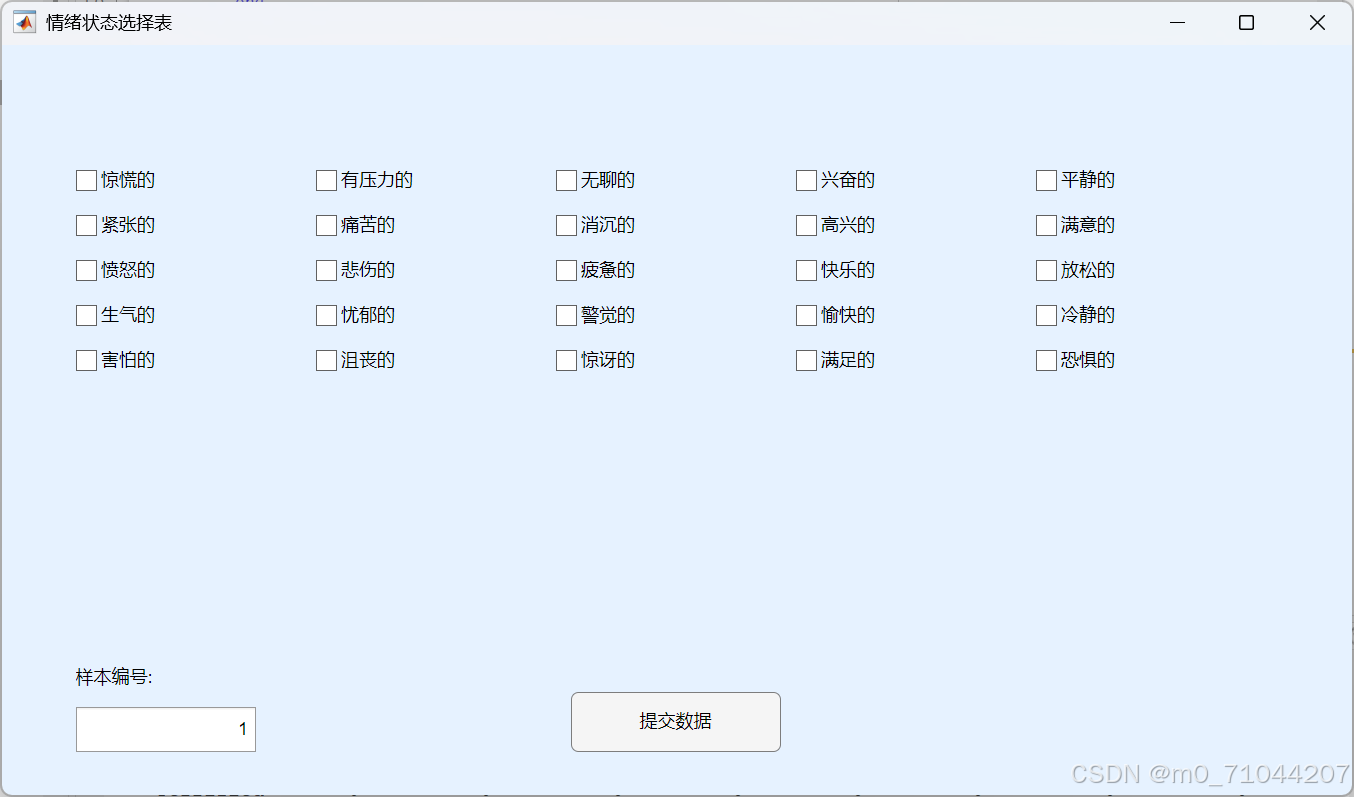
function CATA_Table()
% 严格匹配图片中的原始英文词汇(含大小写和拼写)
emotions_en = {
'Alarmed', 'Stressed', 'Bored', 'Excited', 'Serene',...
'Tense', 'Miserable', 'Droopy', 'Delighted', 'Satisfied',...
'Furious', 'Sad', 'Fatiqued', 'Happy', 'Relaxed',...
'Angry', 'Gloomy', 'Alert', 'Pleased', 'Calm',...
'Afraid', 'Depressed', 'Astonised', 'content', 'Terrified' % 保持图片原样
};
% 中文翻译与英文严格对应
emotions_cn = {
'惊慌的', '有压力的', '无聊的', '兴奋的', '平静的',...
'紧张的', '痛苦的', '消沉的', '高兴的', '满意的',...
'愤怒的', '悲伤的', '疲惫的', '快乐的', '放松的',...
'生气的', '忧郁的', '警觉的', '愉快的', '冷静的',...
'害怕的', '沮丧的', '惊讶的', '满足的', '恐惧的'
};
% 创建图形界面(五列布局)
fig = uifigure('Name','情绪状态选择表','Position',[100 100 900 500],'Color',[0.9 0.95 1]);
% 生成复选框矩阵
checkbox_handles = gobjects(25,1); % 严格对应25个选项
startY = 400;
for i = 1:25
col = mod(i-1,5)+1;
row = floor((i-1)/5);
xPos = 50 + (col-1)*160;
yPos = startY - row*30;
checkbox_handles(i) = uicheckbox(fig,...
'Position',[xPos yPos 160 22],...
'Text',emotions_cn{i},...
'Tag',matlab.lang.makeValidName(emotions_en{i}),... % 关键修复点
'FontSize',12);
end
% 样本管理系统
uilabel(fig,'Position',[50 70 120 20],'Text','样本编号:');
sampleInput = uieditfield(fig,'numeric',...
'Position',[50 30 120 30],...
'Limits',[1 Inf],'Value',1);
% 提交按钮
uibutton(fig,'push',...
'Position',[380 30 140 40],...
'Text','提交数据',...
'ButtonPushedFcn',@(src,event) saveData(checkbox_handles, sampleInput.Value));
end
function saveData(handles, sampleID)
try
% 生成合法变量名(强制转换+唯一性处理)
varNames = matlab.lang.makeValidName({handles.Tag});
[uniqueVars, idx] = unique(varNames,'stable');
if length(uniqueVars) < length(varNames)
error('存在重复变量名,请检查Tag属性');
end
% 构建有效数据表
data = array2table(double([handles.Value]),...
'VariableNames',varNames,...
'RowNames',{});
% 添加样本标识
data.SampleID = repmat(sampleID,height(data),1);
% 智能追加数据
if isfile('CATA_data.mat')
load('CATA_data.mat','all_data');
all_data = [all_data; data];
else
all_data = data;
end
% 保存数据
save('CATA_data.mat','all_data');
writetable(all_data,'CATA_data.xls');
msgbox(sprintf('样本%d保存成功!',sampleID),'操作成功');
catch ME
errordlg(sprintf('错误原因:%s\n请检查:\n1.变量名合法性\n2.数据维度一致性',ME.message),'保存失败');
end
end数据格式:数据会在一个表格中生成,如下所示:

数据分析:(数据分析方式,与Lighting environmental assessment in enclosed spaces based on emotional model来源论文一致)
1、计算总得分(使用频率:计算了25个情感描述词在6种照明设置下的使用频率。)
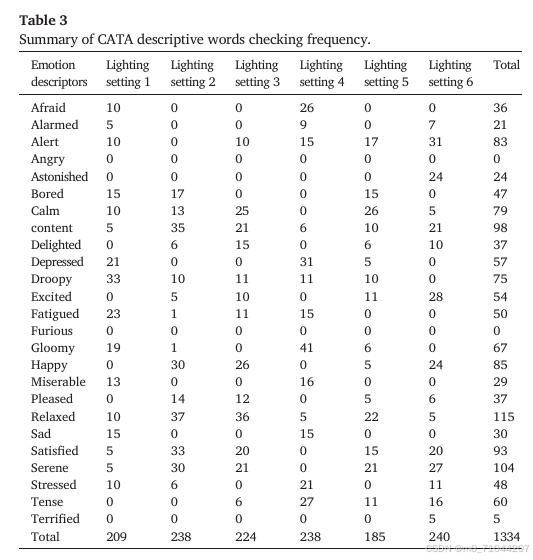
数据汇总后使用 IBM SPSS Statistics 26 进行数据分析。Cochran's Q 检验(Cochran,1950)是一种用于确定问卷多选数据中多个感兴趣样本之间是否存在显著差异的研究方法。表 3 显示了在 6 种照明设置下 CATA 中 25 个情感描述词的使用频率。对这些描述词整体进行 Cochran's Q² 分析,统计结果显示存在显著差异(P = 0.01)。每位参与者平均选择 4.04 个描述词,在 6 种照明设置中选择的描述词数量没有统计差异(P > 0.05),性别之间也没有显著差异。(表中没有直接体现Cochran's Q 检验,只是说明了结果)
2、Cochran's Q检验:用于确定问卷多选数据中多个样本之间是否存在显著差异。论文中使用这种方法来计算25个情感属性的变异性。
Cochran's Q 检验:论文使用 Cochran's Q 检验计算 25 个情感属性的变异性,P <0.05 表示存在差异,反之 P> 0.05 表示无差异。对应分析(CA)现在广泛用于可视化柱状表,可视为主成分分析(PCA)对普通数据的推广,能够将数据投影到正交分量上(Meyners 等,2013)。论文使用这两种方法对 CATA 数据进行统计分析。
3、对应分析(CA):用于可视化列联表,并可视为对普通数据的主成分分析(PCA)的推广。论文中使用这种方法来分析CATA数据,以获得6种照明设置和25个情感描述词的轮廓。
使用 CA 可以得到 6 种照明设置和 25 个描述词的轮廓。图 10 不仅可视化了照明设置之间的差异或相似性,还显示了照明设置与情感描述词之间的关系。CA 中前两个维度代表的实验数据方差为 83.3%(χ² = 1241.37,P < 0.001),表明使用这两个维度进行分析是可靠的。维度 1(59.6%)比维度 2(23.8%)携带更多信息,能更好地解释两个变量之间的关联程度。其中,“Afraid(X = -1.718)” 和 “Miserable(X = -1.616)” 在维度 1 得分最低,“Astonished(Y = -2.774)” 和 “Terrified(Y = -2.774)” 在维度 2 得分最低。描述词 “Angry” 和 “Furious” 在环境评估中未被参与者勾选,因此未在二维图中显示。前两个维度解释83.3%方差(维度1:59.6%,维度2:23.8%)
卡方检验结果:χ²=1241.37(P<0.001)
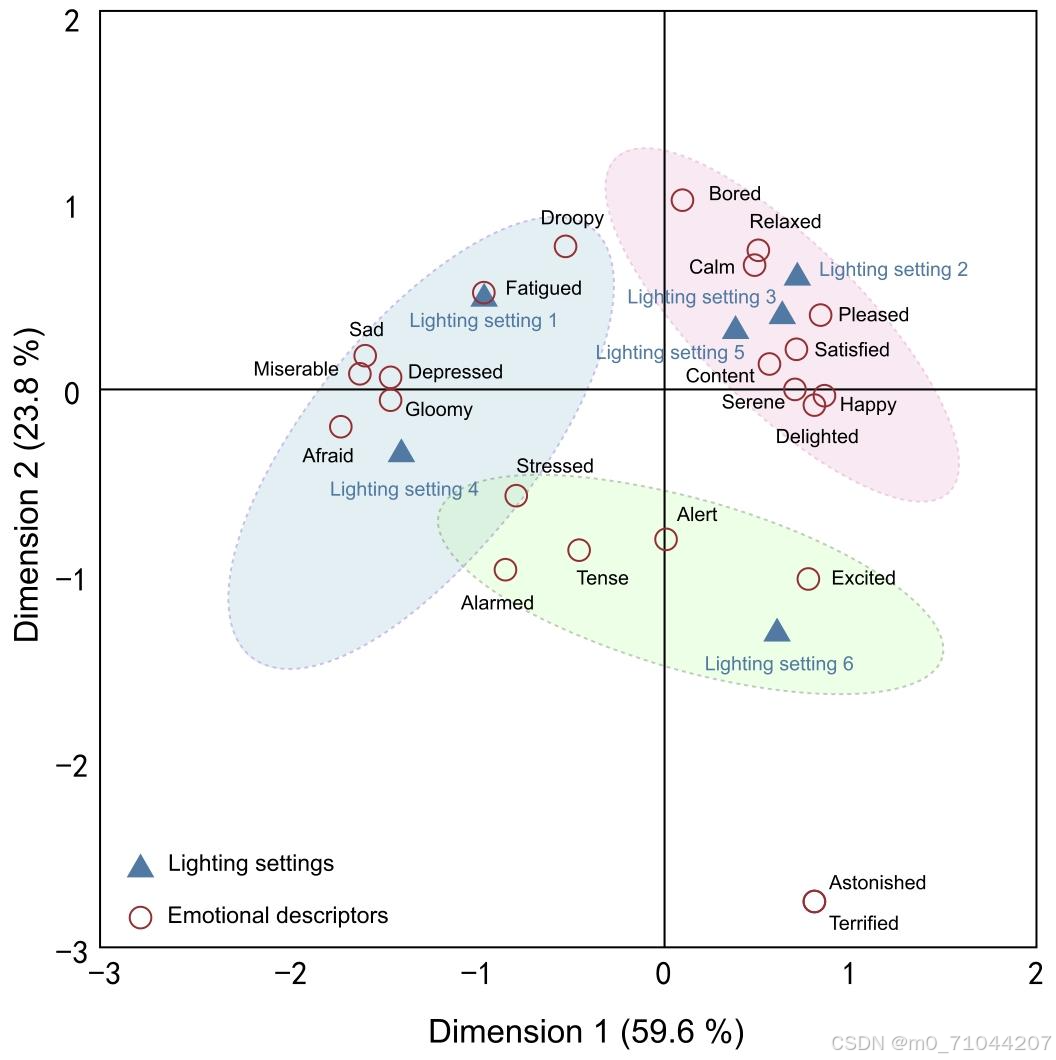 图10
图10
图形分析:横轴(维度1)解释59.6%方差,纵轴(维度2)23.8%
用椭圆标记不同光照设置的聚类区域:粉色椭圆:Setting 2/3/5(与"Calm""Relaxed"等词相关)蓝色椭圆:Setting 1/4(与"Gloomy""Afraid"相关)绿色椭圆:Setting 6(与"Excited""Alert"相关)
数据分析代码(没有可视化,只实现了计算总得分使用频率和Cochran's Q检验,并加入了交叉表分析部分代码)
Cochran's Q检验:是一种非参数统计方法,用于确定多个相关样本之间是否存在显著差异。它适用于分析配对设计或多组相关样本的数据,尤其是在处理二分类或多分类的响应变量时。

-
数据准备:将CATA量表中25个情感描述词的使用频率数据整理成一个矩阵,其中行表示参与者,列表示情感描述词。(提供代码以实现整理为矩阵形式)
-
计算Q统计量:根据上述公式计算Q值。
-
确定显著性水平:通过查表或使用软件计算得到P值,判断是否拒绝原假设。
-
结果解释:如果P值小于显著性水平(通常为0.05),则认为不同情感描述词的使用频率之间存在显著差异。
交叉表分析:是统计学中用于研究两个或多个分类变量之间关系的基本方法。通过将数据整理成交叉表格形式,可以直观展示变量间的分布规律,并进一步检验其关联性。举例:
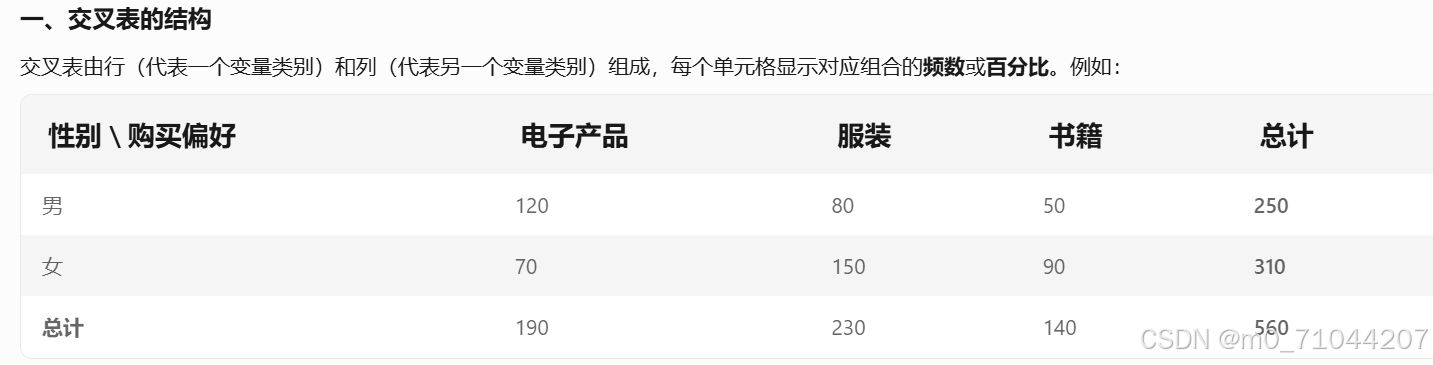
交叉表分析的用途:1、描述性分析:展示分类变量间的联合分布(如性别与产品偏好的关联)。计算条件概率(如女性购买服装的比例)。
2、推断性分析:检验变量间是否存在统计显著性关联(如性别是否影响购买偏好)。量化关联强度(如关联程度的效应量)。
交叉表可以进行可视化:
1、堆叠条形图:展示不同类别在另一变量中的占比分布。
2、马赛克图(Mosaic Plot):通过面积和颜色反映频数和残差(实际-期望频数)。
3、热力图:用颜色深浅表示频数或百分比的高低。
其核心分析方法为:

matlab数据分析代码
function analyze_CATA()
% 读取数据(自动获取第一行列名)
data = readtable('CATA_data.csv', 'PreserveVariableNames', true);
% 提取有效情绪项列名(排除SampleID)
all_columns = data.Properties.VariableNames;
sample_id_idx = strcmpi(all_columns, 'SampleID');
emotion_columns = all_columns(~sample_id_idx);
% 验证列名有效性(基于图片中的特征)
assert(sum(~sample_id_idx) == 25, '列数不符合图片中的25个情绪项');
assert(any(contains(emotion_columns, 'Fatiqued')), '缺少图片关键特征项Fatiqued');
% 提取分析数据
q_data = table2array(data(:, emotion_columns));
% ========== 核心分析流程 ==========
% 1. 计算选择频率(保持图片中的百分比格式)
freq = mean(q_data) * 100;
% 添加频率输出
fprintf('\n=== 情绪项选择频率 ===\n');
freq_table = table(emotion_columns', freq', 'VariableNames', {'情绪项', '频率(%)'});
disp(freq_table);
% 2. Cochran's Q检验(适配动态列名)
[p_q, Q] = manual_cochran_qtest(q_data);
% 添加Q检验结果输出
fprintf('\n=== Cochran''s Q检验结果 ===\n');
fprintf('Q统计量 = %.2f, p值 = %.4f\n', Q, p_q);
if p_q < 0.05
fprintf('(p < 0.05,存在显著差异,进行多重比较)\n');
else
fprintf('(p >= 0.05,无显著差异)\n');
end
% 3. 频次分析
fprintf('\n=== 情绪项选择频次 ===\n');
freq_count = sum(q_data);
freq_count_table = table(emotion_columns', freq_count', 'VariableNames', {'情绪项', '频次'});
disp(freq_count_table);
% 4. 交叉表分析
fprintf('\n=== 情绪项交叉表分析 ===\n');
cross_tab = create_cross_tab(q_data, emotion_columns);
disp(cross_tab);
end
function [pval, Q] = manual_cochran_qtest(data)
% 手动实现Q检验(公式与图片文献一致)
k = size(data, 2);
n = size(data, 1);
Lj = sum(data); % 各列求和
Ti = sum(data, 2); % 各行求和
Q = (k-1) * (k * sum(Lj.^2) - sum(Lj)^2) / (k * sum(Ti) - sum(data(:).^2));
pval = 1 - chi2cdf(Q, k-1);
end
function cross_tab = create_cross_tab(data, col_names)
% 创建交叉表
num_emotions = length(col_names);
cross_tab = zeros(num_emotions, num_emotions);
for i = 1:num_emotions
for j = 1:num_emotions
if i == j
cross_tab(i, j) = sum(data(:, i) & data(:, j));
else
cross_tab(i, j) = sum(data(:, i) & data(:, j));
end
end
end
% 添加列名和行名
cross_tab = array2table(cross_tab, 'VariableNames', col_names, 'RowNames', col_names);
end部分结果显示如下:


















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









