







一.PCA概念及原理
1.1概念
主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维技术,它通过线性变换将高维数据转换为低维数据,同时保留数据的主要特征。PCA的基本思想是找到数据中的主成分,即数据中最大方差的方向,然后将数据投影到这些主成分上,从而实现数据的降维。通过PCA,可以减少数据的维度,去除数据中的噪音和冗余信息,从而更好地理解和分析数据。PCA在数据分析、模式识别、特征提取等领域都有广泛的应用。
1.2原理
PCA(主成分分析)是一种用于降低数据维度的技术,它通过线性变换将原始数据转换为一组新的特征,这些新特征被称为主成分。PCA的原理可以简要概括如下:
1. 数据中心化:首先将原始数据进行中心化处理,即将每个特征的均值减去该特征的均值,以确保数据的均值为零。
2. 计算协方差矩阵:接下来计算数据的协方差矩阵,该矩阵可以展示数据特征之间的相关性。
3. 特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
4. 选择主成分:根据特征值的大小,选择最大的k个特征值对应的特征向量作为主成分,其中k是希望降维后的维度。
5. 数据转换:将原始数据乘以选定的主成分矩阵,得到降维后的数据。
通过这种方式,PCA可以将原始数据转换为更少的特征,同时尽可能保留原始数据的信息。这种降维的方法可以帮助减少数据的复杂性,提高计算效率,并且在一些数据可视化和模式识别的任务中有很好的应用。
二.PCA算法模型
经典的PCA解决问题可划分为以下步骤:
- 数据的导入与处理(eg.人脸识别中需要将每一张人脸拉成一列或一行)
- 计算数据均值并对数据中心化
- 计算协方差矩阵(散度矩阵)
- 分解协方差矩阵得到按特征值从大到小排序的特征向量(也可用SVD分解)
- 取出前k个特征向量作为投影,使原数据降维到对应投影方向,实现由原本n维数据降到k维
三.PCA应用人脸识别
3.1预处理
预处理包括数据导入处理、求均值去心化、分解协方差矩阵得到特征向量(特征脸)
3.1.1导入数据
clear;
% 1.人脸数据集的导入与数据处理(400张图,一共40人,一人10张)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
reshaped_faces=[];
for i=1:40
for j=1:10
if(i<10)
a=imread(strcat('C:\Users\86158\Desktop\学习资料\机器学习\第九讲 主成分分析\Face_Dataset\Face\ORL_Faces\s3',num2str(i),'-',num2str(j),'.tif'));
else
a=imread(strcat('C:\Users\86158\Desktop\学习资料\机器学习\第九讲 主成分分析\Face_Dataset\Face\ORL_Faces\s3',num2str(i),'-',num2str(j),'.tif'));
end
b = reshape(a,2000,1); %将每一张人脸拉成列向量
b=double(b); %utf-8转换为double类型,避免人脸展示时全灰的影响
reshaped_faces=[reshaped_faces, b];
end
end
% 取出前30%作为测试数据,剩下70%作为训练数据
test_data_index = [];
train_data_index = [];
for i=0:39
test_data_index = [test_data_index 10*i+1:10*i+3];
train_data_index = [train_data_index 10*i+4:10*(i+1)];
end
train_data = reshaped_faces(:,train_data_index);
test_data = reshaped_faces(:, test_data_index);3.1.2数据集求均值与数据中心化
利用mean函数对训练集求平均值,得出平均脸(如图1),将训练集中所有数据减去平均脸,实现中心化(中心化后某些人脸如图2,相对原图灰度值更低)
% 2.图像求均值,中心化
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 求平均脸
mean_face = mean(train_data,2);
%waitfor(show_face(mean_face)); %平均脸展示,测试用
% 中心化
centered_face = (train_data - mean_face);
%用于展示中心化后某些训练图片 测试用
%waitfor(show_faces(centered_face));

3.1.3求协方差矩阵、特征值与特征向量并排序
根据数学推导,协方差矩阵可由cov_matrix = centered_face(中心化人脸数据集) * centered_face'求得,再利用eig函数基于特征值对协方差矩阵进行分解(或使用SVD),并用sort函数将特征向量按从大到小排序好,得到所有特征脸(部分特征脸如图3)。
% 3.求协方差矩阵、特征值与特征向量并排序
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 协方差矩阵
cov_matrix = centered_face * centered_face';
[eigen_vectors, dianogol_matrix] = eig(cov_matrix);
% 从对角矩阵获取特征值
eigen_values = diag(dianogol_matrix);
% 对特征值按索引进行从大到小排序
[sorted_eigen_values, index] = sort(eigen_values, 'descend');
% 获取排序后的征值对应的特征向量
sorted_eigen_vectors = eigen_vectors(:, index);
% 特征脸(所有)
all_eigen_faces = sorted_eigen_vectors;
%用于展示某些特征脸 测试用
waitfor(show_faces(all_eigen_faces));
3.2人脸重构
重构的意义:检测特征脸对人脸的还原度与维数的关系(数据降到多少维才能较好还原原始数据)
从已中心化的centered_faces中取出某人脸,用20,40,60,80,...,160个投影(前n个特征向量)按公式rebuild_face = eigen_faces * (eigen_faces' * single_face) + mean_face来重构此人脸,并观察在不同数量的投影下的还原度,重构效果如图4。
%%人脸重构
% 取出第一个人的人脸,用于重构
single_face = centered_face(:,1);
index = 1;
for dimensionality=20:20:160
% 取出相应数量特征脸(前n大的特征向量,用于重构人脸)
eigen_faces = all_eigen_faces(:,1:dimensionality);
% 重建人脸并显示
rebuild_face = eigen_faces * (eigen_faces' * single_face) + mean_face;
subplot(2, 4, index); %两行四列
index = index + 1;
fig = show_face(rebuild_face);
title(sprintf("dimensionality=%d", dimensionality));
if (dimensionality == 160)
waitfor(fig);
end
end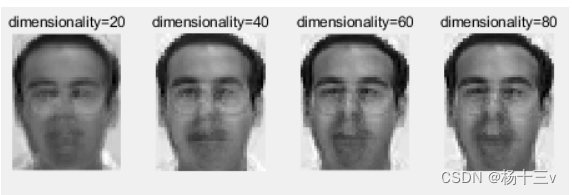
3.3人脸识别
本实验中有两个变量,k从1~6取值,维度从10~160,探究k值及维度对识别率的共同影响
分别对测试集、训练集进行降维,将人脸投影到10,20,30,…,160维空间中,计算未知人脸与所有已知人脸的距离(欧几里得距离),然后使用最近邻分类器KNN进行识别(共同影响如图5 )
% 5.人脸识别
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
index = 1;
Y = [];
% KNN
for k=1:6
for i=10:10:160
% 取出相应数量特征脸
eigen_faces = all_eigen_faces(:,1:i);
% 测试、训练数据降维
projected_train_data = eigen_faces' * (train_data - mean_face);
projected_test_data = eigen_faces' * (test_data - mean_face);
% 用于保存最小的k个值的矩阵
% 用于保存最小k个值对应的人标签的矩阵
minimun_k_values = zeros(k,1);
label_of_minimun_k_values = zeros(k,1);
% 测试脸的数量
test_face_number = size(projected_test_data, 2);
% 识别正确数量
correct_predict_number = 0;
% 遍历每一个待测试人脸
for each_test_face_index = 1:test_face_number
each_test_face = projected_test_data(:,each_test_face_index);
% 先把k个值填满,避免在迭代中反复判断
for each_train_face_index = 1:k
minimun_k_values(each_train_face_index,1) = norm(each_test_face - projected_train_data(:,each_train_face_index));
label_of_minimun_k_values(each_train_face_index,1) = floor((train_data_index(1,each_train_face_index) - 1) / 10) + 1;
end
% 找出k个值中最大值及其下标
[max_value, index_of_max_value] = max(minimun_k_values);
% 计算与剩余每一个已知人脸的距离
for each_train_face_index = k+1:size(projected_train_data,2)
% 计算距离
distance = norm(each_test_face - projected_train_data(:,each_train_face_index));
% 遇到更小的距离就更新距离和标签
if (distance < max_value)
minimun_k_values(index_of_max_value,1) = distance;
label_of_minimun_k_values(index_of_max_value,1) = floor((train_data_index(1,each_train_face_index) - 1) / 10) + 1;
[max_value, index_of_max_value] = max(minimun_k_values);
end
end
% 最终得到距离最小的k个值以及对应的标签
% 取出出现次数最多的值,为预测的人脸标签
predict_label = mode(label_of_minimun_k_values);
real_label = floor((test_data_index(1,each_test_face_index) - 1) / 10)+1;
if (predict_label == real_label)
%fprintf("预测值:%d,实际值:%d,正确\n",predict_label,real_label);
correct_predict_number = correct_predict_number + 1;
else
%fprintf("预测值:%d,实际值:%d,错误\n",predict_label,real_label);
end
end
% 单次识别率
correct_rate = correct_predict_number/test_face_number;
Y = [Y correct_rate];
fprintf("k=%d,i=%d,总测试样本:%d,正确数:%d,正确率:%1f\n", k, i,test_face_number,correct_predict_number,correct_rate);
end
end
% 求不同k值不同维度下的人脸识别率及平均识别率
Y = reshape(Y,k,16);
waitfor(waterfall(Y));
avg_correct_rate=mean(Y);
waitfor(plot(avg_correct_rate));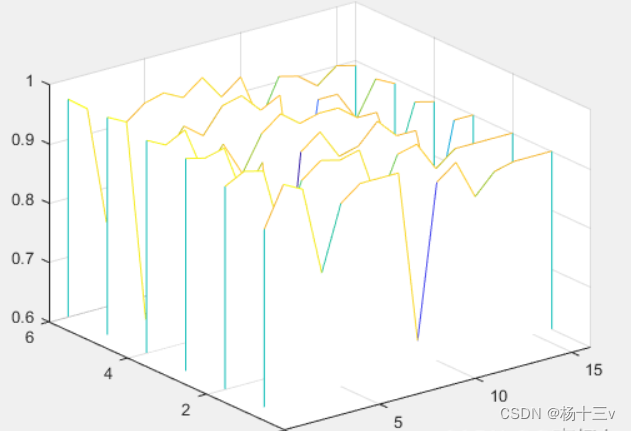
四.小结
1)PCA(主成分分析)为主流的一种线性降维算法。以”最小重构误差“为目标导向,通过降维(投影),用数据中相对重要(最主要)的信息表达(代替)原数据,从而达到降维的目的。















 5535
5535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









