






Numpy

ndarray元素类型是相同的,数据与数据的地址是连续的
而python列表中元素类型是任意的,只能通过寻址方式找到下一个元素

ndarray的使用
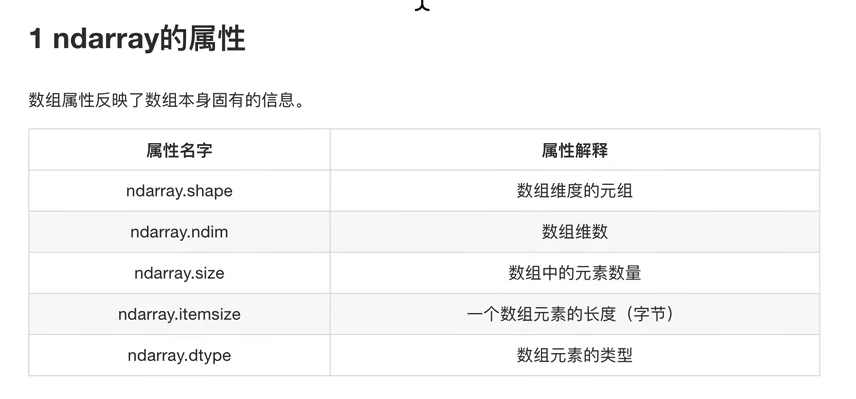
这里主要使用ndarray.shape和ndarray.dtype

三维数组,第一个2是两个二维数组

生成数组的方法


生成固定范围的数组
ndarray.linspace
ndarray.arange
ndarray.logspace
生成随机数组
ndarray.random模块
正态分布,μ决定了其位置,标准差σ决定了其分布的幅度,σ越小,越瘦


#Numpy的基本使用
import numpy as np #先引用一下库,再给它起个别名
这里比较重要的两个模块分别是shape和dtype
#ndarray.shape是数组维度的元组
用法:np.array(object, dtype=None, ndmin=0)
"""
object:任何提供array接口的对象,如列表,元组等
dtype:元素类型,如int,float等
ndmin: nd array的维度(dimention)
"""
用法:np.arange([start,] stop[, step,], dtype=None)
"""
start:起始数字
stop:结束数字,返回的array不包含该数
step:步长
dtype:数据类型,如果不指定则根据给定条件的数据类型来定
"""
用法:linspace(start, stop, num=50, dtype=None, axis=0)
"""
start:起始数字
stop:结束数字,返回的array包含该数
num:返回的值的个数
dtype:数据类型,如果不指定则根据给定条件的数据类型来定
"""总而言之,从这里可以看到,ndarray的主要用法就三种
即:np.array np.arrange np.linspace
其次就是ndarray的属性了
>>> import numpy as np
>>> ary=np.arange(1,10)
>>> ary
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> ary.ndim
1
>>> ary.shape
(9,)
>>> ary.size
9
>>> ary.dtype
dtype('int32')
>>> ary.itemsize
4这是最常用的还是ndarray.shape和ndarray.dtype
代码展示
# 导入所需模块
import pandas as pd
import numpy as np 
# 查看索引、数据类型和内存信息
df.info()
# 查看数值型列汇总统计
df.describe()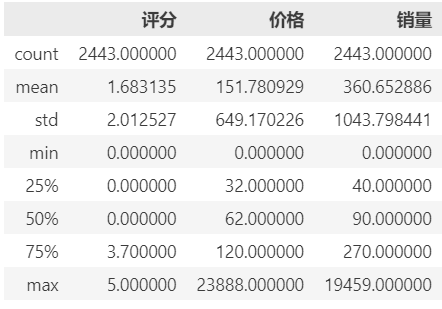
# 查看销量为0 的行
df.loc[df['销量']==0,:].head()
# 按销量排序
df.sort_values('销量', ascending=False).head()
Matplotlib
import matplotlib.pyplot as pltmatplotlib的运用由三部分,首先是数据处理
就是提供一堆数据,就像是数据集一样
然后就是绘制图表,规定一下其长宽和dpi分辨率,对其x轴和y轴进行定义,还可以对其轴刻度进行细分
最后就是就是创建图表了,根据其提供的数据,然后对其进行绘制我们所想得到的线段图表

嗯~ o(* ̄▽ ̄*)o,好像也差不多吧,意思是那个意思,数据处理一个在绘制图像的上面。
现在翻一下代码看看
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['font.family'] = 'SimHei'#这个很重要,用这个就可以识别中文
#准备数据
data = [{'年份': 2016, '收入': 14.5},
{'年份': 2017, '收入': 15.6},
{'年份': 2018, '收入': 17.9},
{'年份': 2019, '收入': 23.4},
{'年份': 2020, '收入': 18.6}
]
year = [str(item['年份']) for item in data]#这里就是对x轴刻度进行定义
income = [item['收入'] for item in data]#这里就是对y轴刻度进行定义
#创建画布
plt.figure(figsize=(10,4),dpi=100)
#绘制图像
plt.plot(year,income) #plt.plot(x,y)
plt.ylim(0, 30) # 设置y轴刻度范围
plt.title('收入情况') #设置标题
plt.xlabel('年份')#x轴内容
plt.ylabel('万元')#y轴内容
#添加x,y轴刻度
#修改x,y轴刻度间隔
# plt.xticks=(x[::5],x_ticks_lable)
# plt.yticks=(y_ticks[::5])
#图像显示
plt.show()Pandas

Pandas是什么
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
在 ndarray 数组(NumPy 中的数组)的基础上构建出了两种不同的数据结构,分别是 Series(一维数据结构)DataFrame(二维数据结构):
#Series的用法
import pandas as pd
s=pd.Series( data, index, dtype, copy)参数名称描述
data输入的数据,可以是列表、常量、ndarray 数组等。
index索引值必须是惟一的,如果没有传递索引,则默认为 np.arrange(n)。
dtypedtype表示数据类型,如果没有提供,则会自动判断得出。
copy表示对 data 进行拷贝,默认为 False。
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print (s)
#这里我好像发现了numpy就像是打工人,负责输入数据,而pandas就像老板,直接让Series经理调用输出一下就好,自己想的形象比喻哈哈这里还可以将键值对dict传进去
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}#这里打工人就不需要了,data默默的承担了所有
s = pd.Series(data)
print(s)
这里就算是吧b后面的1.的.去掉,输出的也是浮点型
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print(s)
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64
#当传递的索引值无法找到与其对应的值时,使用 NaN(非数字)填充这里可以看出经理内部index的地位就是比data打工人高,index赋值多少,就是多少,不管打工人原来给的多少。
这里获取元素位置和切片与原有类似
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[0]) #位置下标
print(s['a']) #标签下标
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])
c 3
d 4
e 5
dtype: int64
emmm看了大牛的文档,发现有一些我都没见过不知道怎么用的,先不管了,嫖过来再说,以后要是用到了呢
axes以列表的形式返回所有行索引标签。
dtype返回对象的数据类型。
empty返回一个空的 Series 对象。
ndim返回输入数据的维数。
size返回输入数据的元素数量。
values以 ndarray 的形式返回 Series 对象。
index返回一个RangeIndex对象,用来描述索引的取值范围。
哎,我仔细一看其实很多我都见过,像什么values值ndim维数size数量dtype数据类型
但这里的empty,
返回一个布尔值,用于判断数据对象是否为空。
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print("是否为空对象?")
print (s.empty)
是否为空对象?
False
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print(s)
#这里先创建一个series对象
0 0.898097
1 0.730210
2 2.307401
3 -1.723065
4 0.346728
dtype: float64
random创建出来的上述示例的行索引标签是 [0,1,2,3,4]
















 2290
2290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











