







 该文章介绍了如何从DREAMER数据集中提取和处理EEG和ECG信号,以及被试对电影片段情绪的评分,使用Python脚本将数据转换为numpy数组并分别保存为npy文件。
该文章介绍了如何从DREAMER数据集中提取和处理EEG和ECG信号,以及被试对电影片段情绪的评分,使用Python脚本将数据转换为numpy数组并分别保存为npy文件。
DREAMER数据集包含了一个实验的被试的评分和生理记录,23个志愿者看了由Gabert-Quillen等人挑选和评价的18个电影片段。EEG和ECG信号被记录,并且每个被试通过报告5个点量表上感觉到的唤醒,效价和支配度来对他们的情绪打分。
下面是Dreamer数据提取程序,并把每个人的数据保分别存到npy文件中
import scipy.io as sio
import seaborn as sns
import pandas as pd
import numpy as np
import time
import mne
path = "E:/DREAMER.mat"
raw = sio.loadmat(path)
participant =0
video = 0
electrode = 0
B, S = [], []
basl = (raw["DREAMER"][0, 0]["Data"][0, participant]["EEG"][0, 0]["baseline"][0, 0][video, 0][:, electrode])
stim = (raw["DREAMER"][0, 0]["Data"][0, participant]["EEG"][0, 0]["stimuli"][0, 0][0, 0][:, ])
print(basl.shape)
print(stim.shape)(7808,)
(25472, 14)
def feat_extract_EEG(raw):
EEG_tmp = np.zeros((23, 18, 107520))
for participant in range(0, 23):
for video in range(0, 18):
column=0
for electrode in range(0,14):
stim = (raw["DREAMER"][0, 0]["Data"][0, participant]["EEG"][0, 0]["stimuli"][0, 0][video, 0][:, electrode])
for i in range(0,7680):
EEG_tmp[participant,video,column]= stim[i]
column+=1
col = []
for i in range(0, 7680):
col.append("Electrode1_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode2_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode3_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode4_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode5_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode6_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode7_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode8_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode9_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode10_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode11_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode12_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode13_"+str(i + 1))
for i in range(0, 7680):
col.append("Electrode14_"+str(i + 1))
EEG_tmp = EEG_tmp.reshape(-1,EEG_tmp.shape[2])
data_EEG = pd.DataFrame(EEG_tmp, columns=col)
# print(data_EEG)
# from sklearn import preprocessing
# x = data_EEG.values
# min_max_scaler = preprocessing.MinMaxScaler()
# x_scaled = min_max_scaler.fit_transform(x)
# data_EEG = pd.DataFrame(x_scaled)
# data_EEG.columns = col
# print(data_EEG)
return data_EEGdef participant_affective(raw):
a = np.zeros((23, 18, 4), dtype=object)
for participant in range(0, 23):
for video in range(0, 18):
# a[participant, video, 0] = (raw["DREAMER"][0, 0]["Data"]
# [0, participant]["Age"][0][0][0])
# a[participant, video, 1] = (raw["DREAMER"][0, 0]["Data"]
# [0, participant]["Gender"][0][0][0])
# a[participant, video, 2] = int(participant+1)
# a[participant, video, 3] = int(video+1)
# a[participant, video, 4] = ["Searching for Bobby Fischer",
# "D.O.A.", "The Hangover", "The Ring",
# "300", "National Lampoon\'s VanWilder",
# "Wall-E", "Crash", "My Girl",
# "The Fly", "Pride and Prejudice",
# "Modern Times", "Remember the Titans",
# "Gentlemans Agreement", "Psycho",
# "The Bourne Identitiy",
# "The Shawshank Redemption",
# "The Departed"][video]
a[participant, video, 0] = ["calmness", "surprise", "amusement",
"fear", "excitement", "disgust",
"happiness", "anger", "sadness",
"disgust", "calmness", "amusement",
"happiness", "anger", "fear",
"excitement", "sadness",
"surprise"][video]
a[participant, video, 1] = int(raw["DREAMER"][0, 0]["Data"]
[0, participant]["ScoreValence"]
[0, 0][video, 0])
a[participant, video, 2] = int(raw["DREAMER"][0, 0]["Data"]
[0, participant]["ScoreArousal"]
[0, 0][video, 0])
a[participant, video, 3] = int(raw["DREAMER"][0, 0]["Data"]
[0, participant]["ScoreDominance"]
[0, 0][video, 0])
b = pd.DataFrame(a.reshape((23*18, a.shape[2])),
columns=[ "target_emotion", "valence", "arousal", "dominance"])
return b
def_EEG3 = feat_extract_EEG(raw)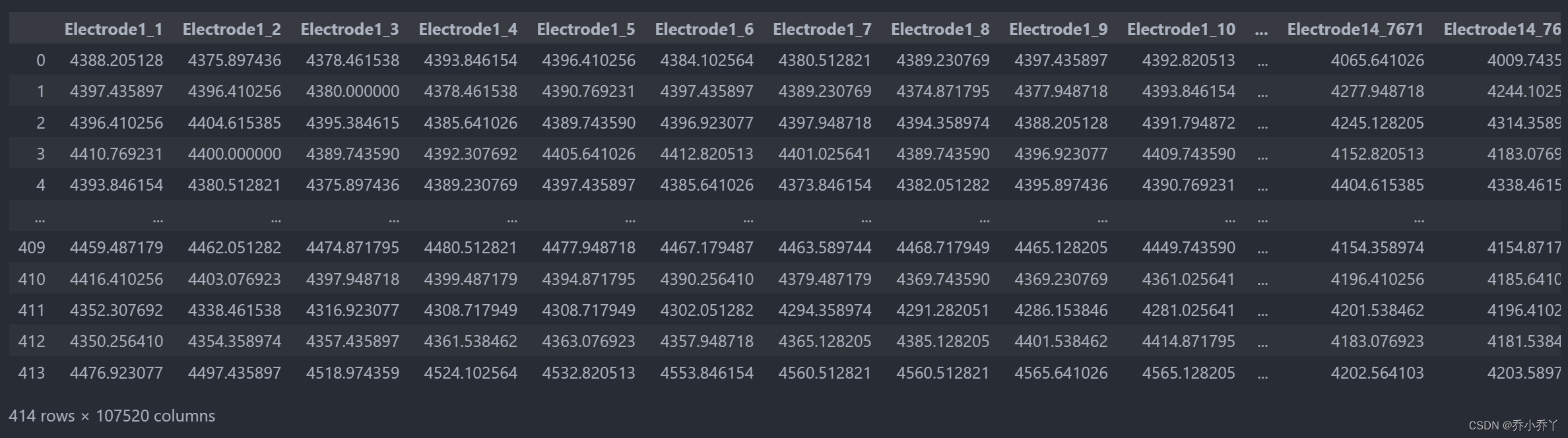
df_participant_affective = participant_affective(raw)
df_participant_affective
df = pd.concat([def_EEG3, df_participant_affective], axis=1)
df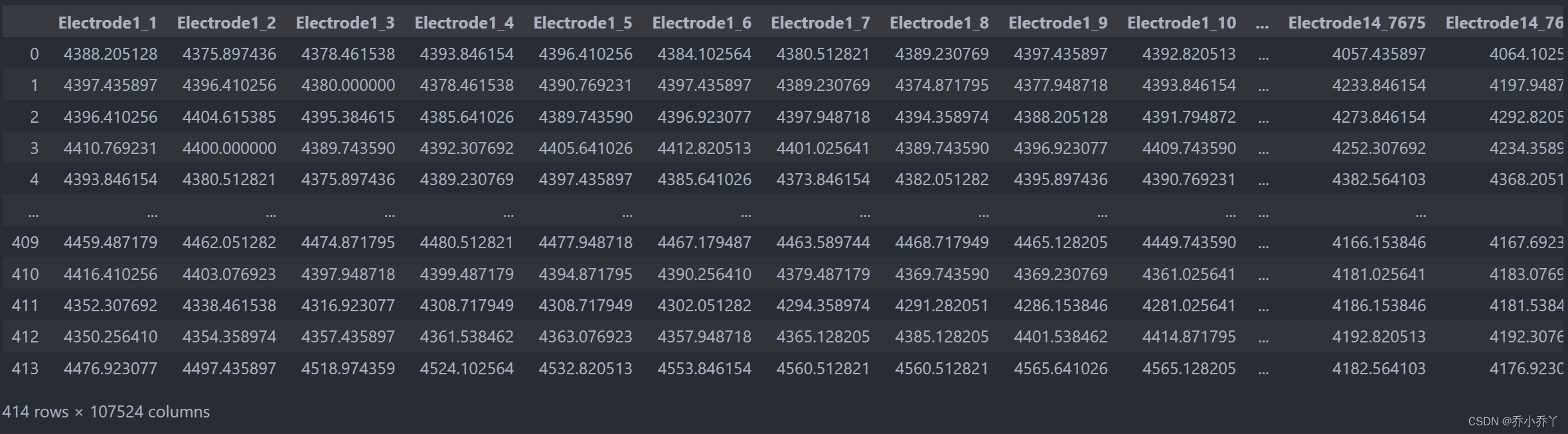
num_rows = 18
total_iterations = 23
# 保存文件的初始编号
file_index = 1
b= []
for i in range(1):
# 计算起始行和结束行的索引
start_row = i * num_rows
end_row = (i + 1) * num_rows
a = []
for j in range(1,15):
selected_columns = [col for col in df.columns if col.startswith('Electrode'+str(j)+'_')]
result_df = df[selected_columns].iloc[start_row:end_row]
a.append(result_df)
b.append(a)
b = np.array(b)
# 保存结果到 Excel 文件
excel_filename = f'C:/Users/86157/Desktop/dreamer/output_electrode1_{start_row + 1}_to_{end_row}.npy'
np.save(excel_filename,b)
print(f'提取的数据已保存到 {excel_filename}')
# 更新文件编号
file_index += 1提取的数据已保存到 C:/Users/86157/Desktop/dreamer/output_electrode1_1_to_18.npy
num_rows = 18
total_iterations = 23
for i in range(total_iterations):
b= []
start_row = i * num_rows
end_row = (i + 1) * num_rows
a = []
for j in range(1,15):
selected_columns = [col for col in df.columns if col.startswith('Electrode'+str(j)+'_')]
result_df = df[selected_columns].iloc[start_row:end_row]
a.append(result_df)
b.append(a)
b = np.array(b)
c = b.reshape(14,18,7680)
c= np.transpose(c,(1,0,2))
# 保存结果到 Excel 文件
excel_filename = f'C:/Users/86157/Desktop/dreamer/dreamer{str(i)}.npy'
np.save(excel_filename,c)
print(f'提取的数据已保存到 {excel_filename}')
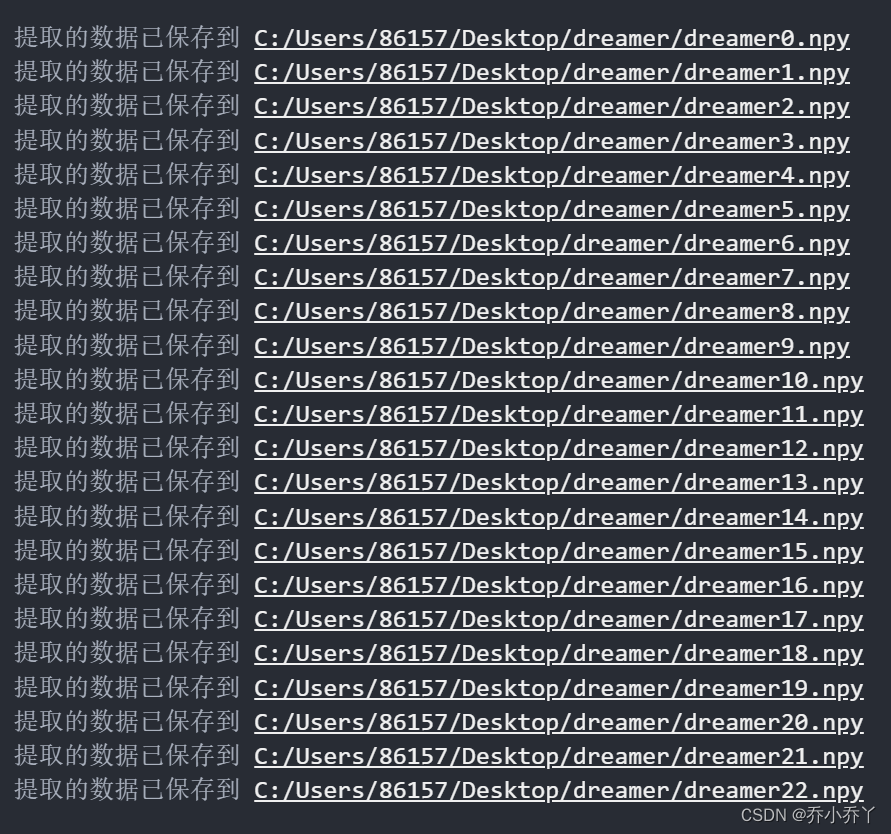

















 5912
5912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









