










费曼讲解大模型参数微调——小白也能看懂

学贵专精正
人工超级智能(ASI)——聚焦AI数据、算法、思想、伦理等深度洞察,致力于AI先进科技、先进思想、先进文化。
23篇原创内容
公众号
故事是这样的
人物组(1):老师、学生。
人物组(2)爸爸、妈妈、我,妹妹。
任务一:妈妈监管我的学习,我学习理科,我主要就是寻找窍门,提升解题的技巧和方法,想在考试中获得高分,这样妈妈就会多给我零花钱。
任务二:爸爸监管妹妹的学习,妹妹学习文科。妹妹主要就是背,就是把书本上学到的知识都背下来,通过记忆内容来学习。
任务二: 爸爸监管妹妹的文科学习爸爸开始监管妹妹学习文科背诵书本知识记忆标准答案完成文科学习任务一: 妈妈监管我的理科学习妈妈开始监管我学习理科寻找解题窍门提升技巧方法考试获得高分获得更多零花钱
学贵专精正
人工超级智能(ASI)——聚焦AI数据、算法、思想、伦理等深度洞察,致力于AI先进科技、先进思想、先进文化。
23篇原创内容
公众号
全家大脑和大语言模型的关系
大家都使用过ChatGPT,deepseek,我们只要简单的对大模型网页输入一个问题,就会马上得到答案。所以,输进去的是文字,大模型回答的也是文字。那么大模型这个大脑是咋想完就说出答案的呢?我们先看下面这个图,主要是蓝色的步。
- • 第一步,从左边开始,我们给大模型说一句话:今天我们来开会。
- • 第二步,每一个汉字都被编成了电报码,编码的办法就是让每个汉字自己的位置是1,其他位置是0。这些电报码被逐个送入到大模型的核心计算单元——神经元里。
- • 第三步,大模型的神经元(计算单元)根据输入的电报码,逐个计算出新的电报码,
- • 第四步,这些个电报码又被破译成汉字。
- • 第五步,被破译的汉字,逐个从大模型输出:大家很高兴,这就是大模型对我们提给他的问题的答案。
神经元计算细节示例:今=[1,0,0...]深度计算示例:[0,1,0...]=天(1) 输入语句(2) 汉字编码(3) 神经元计算(4) 电报码解码(5) 输出结果
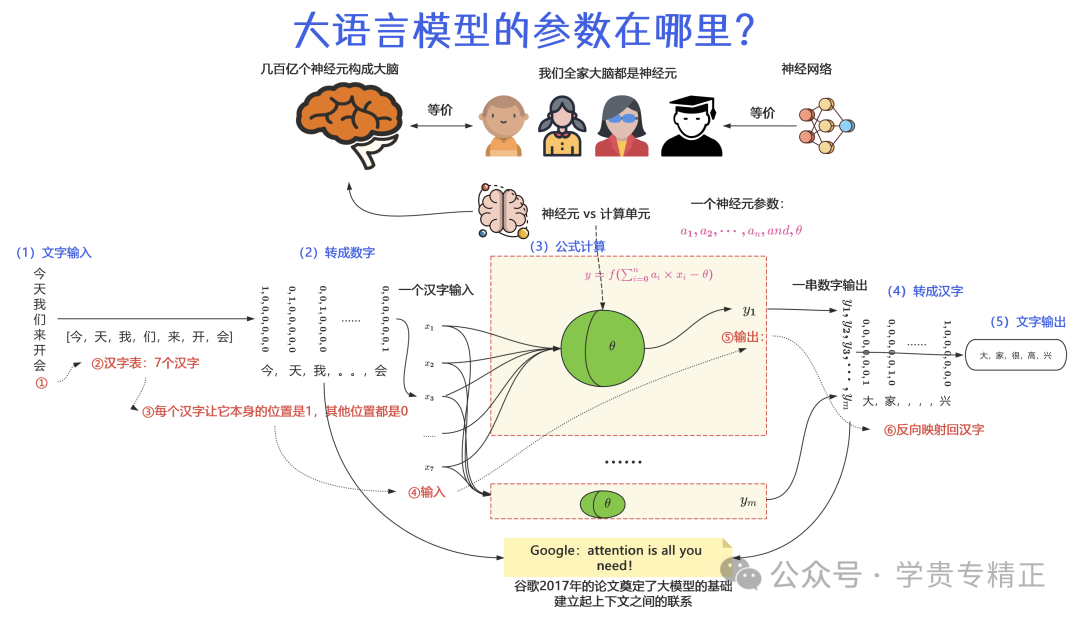
因为大语言模型里的神经元的数量是很大的,大语言模型使用数量巨大的神经元来模拟人脑的几百亿个神经元。这样,大语言模型就类似人脑。而每个神经元里其实都是一个线性或者非线性的计算公式,这个公式里包含着公式系数,如。几百亿个神经元,就是几百亿个类似的公式,通过加减乘除或者指数方式拼成了一个更加巨大的公式,然后就有了几百亿甚至上千亿个系数。这些系数就是大模型的参数。
这不是一个严谨的说法,但我们只要知道大语言模型是由公式和公式系数构成的就好。公式决定了大语言模型思考问题的规律,也就是大语言模型是按照数学计算公式来思考问题的,而系数决定了大模型思考问题的配置,思考方式+思考配置,最终确定了大语言模型的输出内容。
学贵专精正
人工超级智能(ASI)——聚焦AI数据、算法、思想、伦理等深度洞察,致力于AI先进科技、先进思想、先进文化。
23篇原创内容
公众号
学生如何跟着老师学知识——小模型参数学习/蒸馏范式
我们知道了大语言模型可以思考问题,但是,大语言模型怎么学习(训练)呢?其实大语言模型学习和我们人类学习的方法差不多,只不过大语言模型学习的方法更加笨拙一些,不如人类的学习方法灵活。人类就是想学就学,碰见什么东西学什么?从来不固定的学习方法,但是机器不一样,谁让它是机器呢。
下图展示了一个学生(知识少的小语言模型)如何跟着老师(知识多的大语言模型)学知识的过程。
①右图:模型参数学习/蒸馏范式。从下往上看。
如果一个没有多少知识的学生想要学到更多的知识,他或者跟着老师学,或者自己学。跟着老师学最后的结果就是老师头脑里的知识被迁移到了学生的头脑(小语言模型),自己学,其实也是要读书,书也是曾经的老师们创造的知识。
无论怎么样,都可以按照图中的方法,假如学生准备学习数学知识,那么可以找很多精题试卷,分别让学生作答,老师作答。将作答的试卷结果进行比较,必将比较的结果以不同的方式反馈给学生。
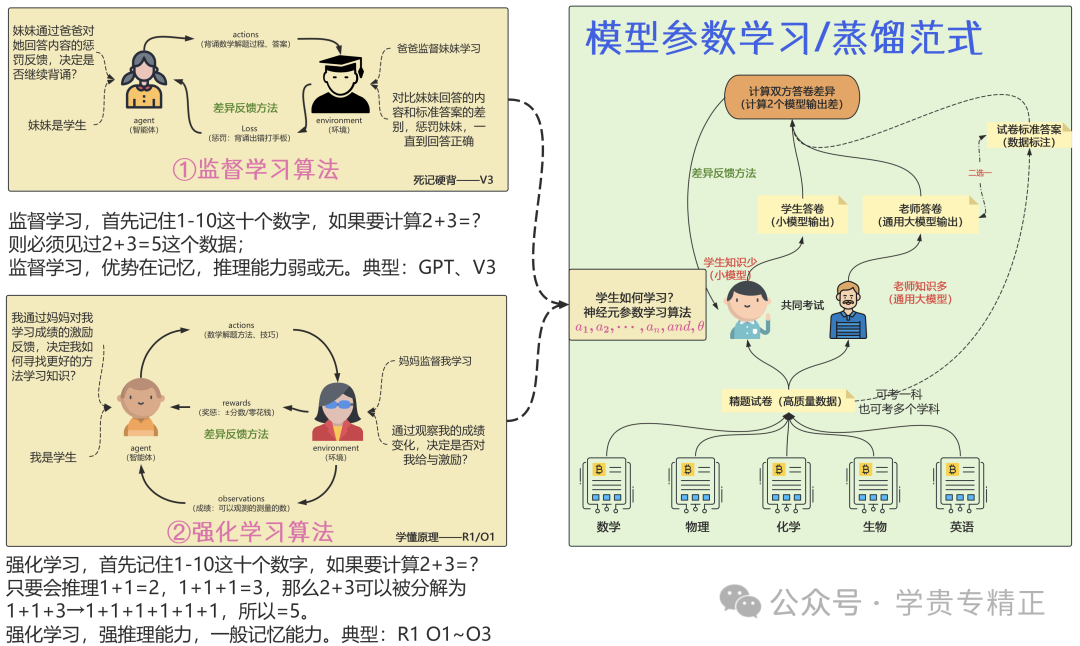
②左图:这里反馈的方法不同,直接决定了学生学习的具体行动方式和思路,从上往下看。
- • 假如妹妹跟着爸爸学习。妹妹每天背诵,爸爸负责检查,如果爸爸每次反馈的方法是:比较妹妹回答的内容和标准答案的差异,如果差异大就惩罚妹妹,差异小就惩罚少,那么这就是用监督学习方法。妹妹最好的学习方法就是将过程和答案都背下来,死记硬背,不用考虑其他。这种学习过程本质是妹妹(小模型)记忆强化,背的越多,学的越好,非常适合文科内容的学习,尤其是常识性的问题。现实中常见的早期的ChatGPT,以及DeepSeek-V3、llama等等,都属于这类模型。就是见过的,就知道,没见过的,就很难了。再举一个例子,首先记住1-10这十个数字,如果要计算2+3=?则必须见过2+3=5这道题,如果没记住,那么即便是你会2+2=4,也大概率不会2+3=5;所以,监督学习,优势在记忆,推理能力很弱或早期的模型就没有(后来毕竟改进了)。
- • 假如我跟着妈妈学习。我每天学习,妈妈负责检查。如果妈妈每次反馈的方法是:告诉我考试成绩和老师考试成绩的差异,如果差异变大,我就不能得到更多的零花钱,如果差异变小,那么就可以得到更多的零花钱,那么就是用强化学习方法。给我分数差异的变化,我就知道我是否进步了,并且这种学习方法,我的目标性不是像监督学习那样,一定要背下来某个东西,我才能学习好,而是我只要分数进步大,我就是进步了,就可以得到更多的零花钱。那么此时,我的学习技巧?其实就是我的自由,这种情况,我可以选择背诵,但是我也可以选择逻辑推理。如果我学习理科,那我肯定更愿意学习推理,因为背诵题目是背不完的,数理化的题目是无穷无尽的。我只要寻找更好的推理技巧,掌握了数理化的原理,以不变应万变,我的分数相反可以提升的更快;但如果学习文科,则必须要背诵、记忆,反倒是非常消耗时间。同样举计算2+3=?的例子,首先记住1-10这十个数字,如果要计算2+3=?我即便从来没见过2+3=5这道题,我只要会推理1+1=2,1+1+1=3,那么2+3可以被分解为1+1+3→1+1+1+1+1+1,所以=5。所以强化学习的方法,强推理能力,一般记忆能力。典型:R1 O1~O3。
理科学习模式文科学习模式差异大差异小差异增加差异减小典型模型:ChatGPT/LLaMA典型架构:DeepSeek-R1/O3开始背诵输入标准答案机械记忆检查差异强化惩罚减少惩罚加强死记硬背开始学习探索解题策略自主推理成绩对比奖励减少奖励增加调整方法早期大模型新一代模型
实际上,监督学习对应着提升学生的记忆内容的量,而强化学习对应着提升学生逻辑推理能力。到底使用哪种方法进行学习,要看我们学习的问题是属于要记忆才能学好的,还是要学会推理才能学好的?文科就是属于要记忆的,理科即是必须学会推理的。
回头来,两种不同的学习方法,对应了学生的两种不同思考模式。也对应了两种不同的更新小语言模型参数的算法。
学贵专精正
人工超级智能(ASI)——聚焦AI数据、算法、思想、伦理等深度洞察,致力于AI先进科技、先进思想、先进文化。
23篇原创内容
公众号
用我和妹妹的方法全流程培养学生
我们要全流程的培养学生,就要考虑学生从学习方法,到将来就业,这是负责任的教育态度,是对未来负责的态度。我们要培养一个学生,一定是有目的的培养学生,我和妹妹的学习方法只是一方面。也要选择合适的学习资料和学习工具,将来为毕业生提供合适的岗位。
- • ①确定目标。我们的学生主要是搞文字工作的,还是搞书法艺术的?如果是文字工作方面,那么我们就要选一个开源的文本生成大模型;如果是搞书法艺术方面,那么我们就要选一个开源的多模态大模型。
- • ②学习资料的选择。基础课程(开源专业数据集)和专业课程都要有。基础课可以不那么挑选教材,但专业课程,就必须选择和学生未来的职业发展密切相关且质量好的读本,这些读本必须精挑细选,避免学生学习过程中出现学到错误或者浪费就精力的问题。只有学的材料书本是非常精良的,才能保证学生的学习别学偏了。
- • ③学习工具的选择。学习工具应该选择一个适合学生学习方式的工具,学习条件、学校,以及学生学好了专业之后,合适的岗位和工作地点。
- • ④学习方法的确定。学习方法就是上文介绍的两种,分别是监督学习和强化学习。
④确定学习方法陈述性程序性知识类型监督学习强化学习③配置学习工具教学平台Jupyter训练框架PyTorch部署环境Docker②选择学习资料开源数据集精选教材通识基础Wikipedia专业技能行业文档①确定培养目标文字创作艺术设计人才需求分析核心方向文本大模型多模态模型①确定培养目标②选择学习资料③配置学习工具④确定学习方法就业输出
对应大语言模型的学习流程,就对应以下四个步骤。
一、预训练模型选择
基于业务场景需求选择基础模型架构:
①文本大模型(适用于NLP任务)
②多模态大模型(适用图文生成任务)
二、专业数据处理流程
构建高质量训练数据集:
- 数据来源:开源数据集+内部真实业务场景数据(多类典型场景数据)
- 预处理:数据去重→清洗(异常值/噪声处理)→格式化与向量化
- 数据优化:通过聚类算法进行多样性筛选,结合THINK过程生成标注标签
三、微调工具链配置
构建完整训练框架:
- 核心工具:LLaMA-Factory框架/字节verl框架/unsloth加速库
- 部署方案:集成vllm、sglang等推理优化工具
- 硬件适配:支持PyTorch Lightning、DeepSpeed等分布式训练方案
四、微调算法实现
实施两类主流训练方法:
(一)有监督微调(SFT)
流程:自定义数据集→交叉熵损失函数→分布式训练循环→评估指标验证(Accuracy/BLEU)→迭代优化
(二)强化学习微调(RL)
四阶段实施:
- 数据准备:采集人类/AI标注的偏好对比数据
- 奖励建模:训练独立奖励评估模型
- 策略生成:基于监督模型初始化,通过集束搜索生成响应
- 策略优化:使用PPO/TRL等算法优化策略模型,KL散度约束防止偏离
参考下图。
强化学习算法有监督学习算法模型微调四步法①基于业务需求选择预训练模型文本大模型多模态大模型②专业数据集开源专业数据集内部数据集真实场景数据(1)真实场景数据(2)真实场景数据(3)数据去重数据清理真实场景数据(4)格式化,向量化聚类算法多样性筛选标注生成THINK过程③基于数据集微调工具框架LLaMA-Factoryverl(字节开源)部署、推理工具(vllm、sglang)unsloth④主要微调算法流程有监督微调 SFT强化学习微调 RLHF,GRPO/PPO/DAPO预处理(自行收集和整理数据集)定义损失函数(Cross-Entropy)训练循环(PyTorch LightningDeepSpeed/Megatron)验证集评估(Accuracy/BLEU)模型迭代偏好数据收集(Human/AI标注对比)训练奖励模型(Reward Modeling)初始化策略模型(基于有监督学习模型)生成响应(Beam Search)奖励模型打分(RM Inference)策略优化(PPO/TRLRL4LMs)KL散度约束模型迭代
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









