






**VQ-VAE跟VAE完全是两个概念。**题目中所谓的“VAE + Diffusion效果好”指的应该是“VAE/VQ-VAE(VQ-GAN) + Diffusion效果好”,我猜你想说的就是Stable Diffusion做的事。
首先我们来看下VAE和VQ-VAE的区别。

VAE的流程图
VAE的流程:encoder将图片编码为均值和方差,同时随机采样出一个服从正态分布的ε,通过ε × std + mean的方式重采样得到latent feature,最后latent feature送入decoder重建得到RGB图片。
**VQ-VAE的流程:**encoder将图片编码,同时通过最邻近搜索将编码得到的特征对codebook进行映射,得到离散的latent feature,最后latent feature送入decoder重建得到RGB图片。VQ-VAE相当于维护了一个codebook,而并非直接对连续的latent feature做重构。

VQ-VAE的流程图
VQ-GAN在VQ-VAE的训练进一步加入了perceptual loss以及GAN loss,从而让重构的图片质量更好。

VQ-GAN的流程图
综上,可以理解为VQ-VAE或者是VQ-GAN都提供了一个有效的图片表征方法,即通过一个压缩后的latent feature就能够在RGB空间上对应一张图。扩散模型中,DDPM已经证明了通过大量的算力资源训练一个diffusion model能够在RGB空间把图像分布拟合好,Stable Diffusion的思路则是“既然通过一个压缩后的latent feature能够表征好一张图,那就索性在latent feature的隐空间上做扩散”,因此Stable Diffusion本质上是一个latent diffusion model。

Stable Diffusion的流程图
SD原文3.1节中同时提供了VAE和VQ-VAE两种方案,VAE效果更好所以被大家一直沿用)**之所以效果这么好,主要还是因为diffusion model强大。强大到用diffusion model去拟合的隐空间分布,能够逼近VAE或者VQ-VAE用encoder编码RGB图片得到的latent feature分布。
其实话说回来,从用到的数据和算力上也能说明问题,VAE decoder那才用多少数据算力,Stable Diffusion用的2048张A100和几亿数量级的数据(参见LAION-5B)做训练可不是闹着玩的,要是效果不好也不敢放出来了。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
**

**!
【Stable Diffusion学习路线思维导图】
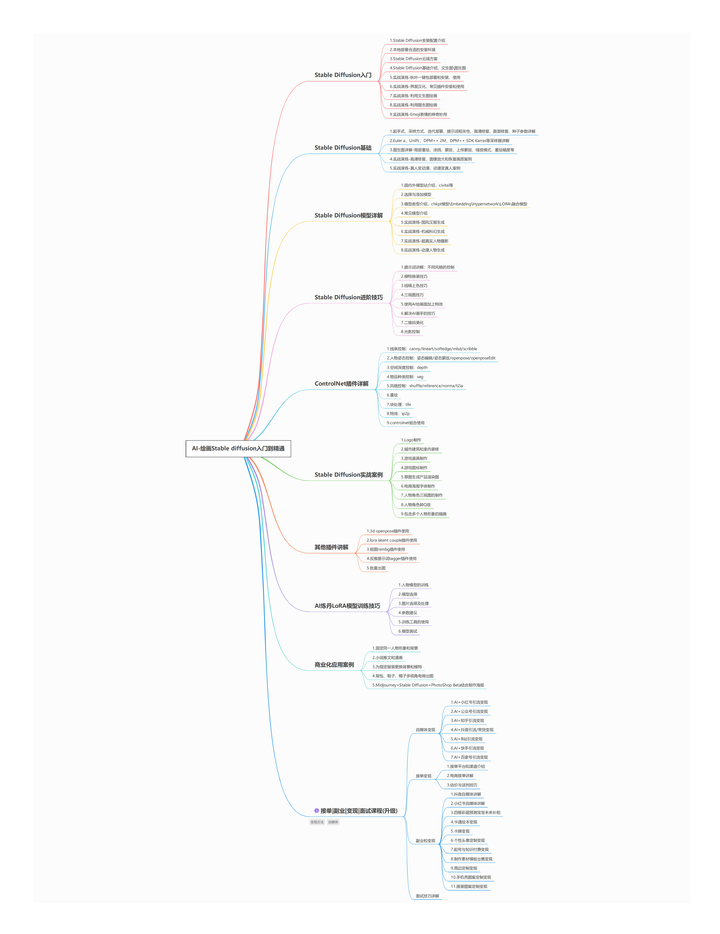
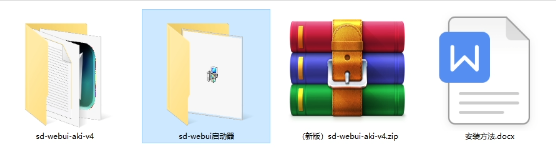
【Stable Diffusion安装包(含常用插件、模型)】
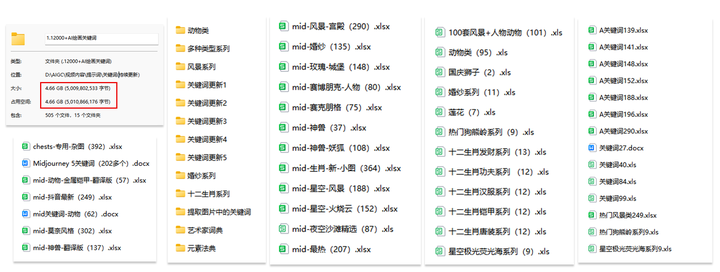
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

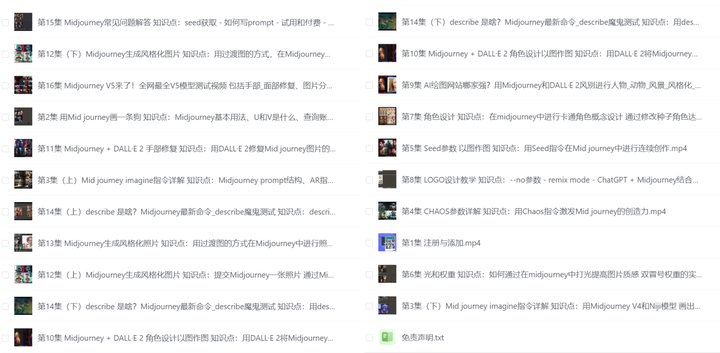
【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!

















 5835
5835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









